 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Feb 11, 2025The imitation of voice, targeted on specific speech attributes such as timbre and speaking style, is crucial in speech generation. However, existing methods rely heavily on annotated data, and struggle with effectively disentangling timbre and style, leading to challenges in achieving controllable generation, especially in zero-shot scenarios. To address these issues, we propose Vevo, a versatile zero-shot voice imitation framework with controllable timbre and style. Vevo operates in two core stages: (1) Content-Style Modeling: Given either text or speech's content tokens as input, we utilize an autoregressive transformer to generate the content-style tokens, which is prompted by a style reference; (2) Acoustic Modeling: Given the content-style tokens as input, we employ a flow-matching transformer to produce acoustic representations, which is prompted by a timbre reference. To obtain the content and content-style tokens of speech, we design a fully self-supervised approach that progressively decouples the timbre, style, and linguistic content of speech. Specifically, we adopt VQ-VAE as the tokenizer for the continuous hidden features of HuBERT. We treat the vocabulary size of the VQ-VAE codebook as the information bottleneck, and adjust it carefully to obtain the disentangled speech representations. Solely self-supervised trained on 60K hours of audiobook speech data, without any fine-tuning on style-specific corpora, Vevo matches or surpasses existing methods in accent and emotion conversion tasks. Additionally, Vevo's effectiveness in zero-shot voice conversion and text-to-speech tasks further demonstrates its strong generalization and versatility. Audio samples are available at https://versavoice.github.io.
VoiceShop: A Unified Speech-to-Speech Framework for Identity-Preserving Zero-Shot Voice Editing
Apr 11, 2024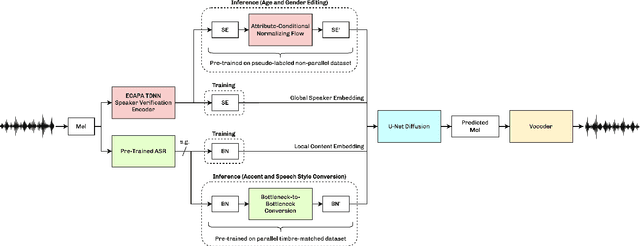

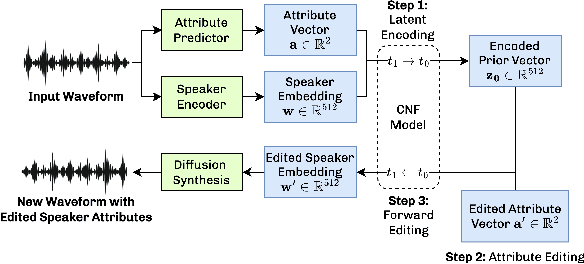
We present VoiceShop, a novel speech-to-speech framework that can modify multiple attributes of speech, such as age, gender, accent, and speech style, in a single forward pass while preserving the input speaker's timbre. Previous works have been constrained to specialized models that can only edit these attributes individually and suffer from the following pitfalls: the magnitude of the conversion effect is weak, there is no zero-shot capability for out-of-distribution speakers, or the synthesized outputs exhibit undesirable timbre leakage. Our work proposes solutions for each of these issues in a simple modular framework based on a conditional diffusion backbone model with optional normalizing flow-based and sequence-to-sequence speaker attribute-editing modules, whose components can be combined or removed during inference to meet a wide array of tasks without additional model finetuning. Audio samples are available at \url{https://voiceshopai.github.io}.
Efficient Neural Music Generation
May 25, 2023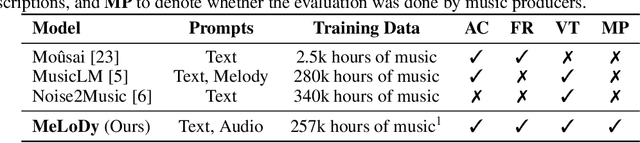
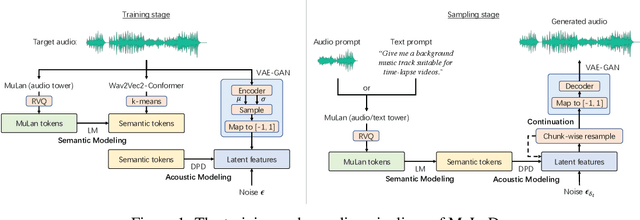
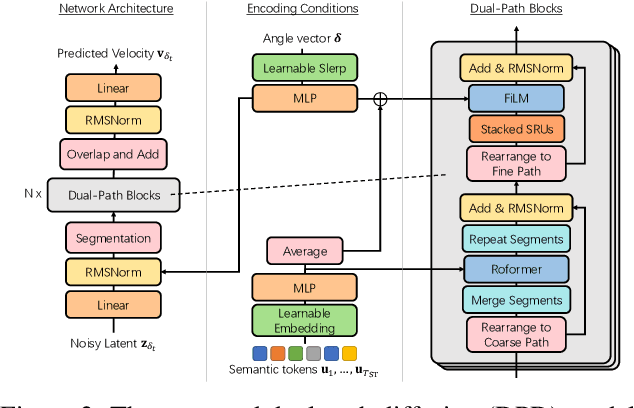

Recent progress in music generation has been remarkably advanced by the state-of-the-art MusicLM, which comprises a hierarchy of three LMs, respectively, for semantic, coarse acoustic, and fine acoustic modelings. Yet, sampling with the MusicLM requires processing through these LMs one by one to obtain the fine-grained acoustic tokens, making it computationally expensive and prohibitive for a real-time generation. Efficient music generation with a quality on par with MusicLM remains a significant challenge. In this paper, we present MeLoDy (M for music; L for LM; D for diffusion), an LM-guided diffusion model that generates music audios of state-of-the-art quality meanwhile reducing 95.7% or 99.6% forward passes in MusicLM, respectively, for sampling 10s or 30s music. MeLoDy inherits the highest-level LM from MusicLM for semantic modeling, and applies a novel dual-path diffusion (DPD) model and an audio VAE-GAN to efficiently decode the conditioning semantic tokens into waveform. DPD is proposed to simultaneously model the coarse and fine acoustics by incorporating the semantic information into segments of latents effectively via cross-attention at each denoising step. Our experimental results suggest the superiority of MeLoDy, not only in its practical advantages on sampling speed and infinitely continuable generation, but also in its state-of-the-art musicality, audio quality, and text correlation. Our samples are available at https://Efficient-MeLoDy.github.io/.
Non-parallel Accent Conversion using Pseudo Siamese Disentanglement Network
Dec 12, 2022



The main goal of accent conversion (AC) is to convert the accent of speech into the target accent while preserving the content and timbre. Previous reference-based methods rely on reference utterances in the inference phase, which limits their practical application. What's more, previous reference-free methods mostly require parallel data in the training phase. In this paper, we propose a reference-free method based on non-parallel data from the perspective of feature disentanglement. Pseudo Siamese Disentanglement Network (PSDN) is proposed to disentangle the accent information from the content representation and model the target accent. Besides, a timbre augmentation method is proposed to enhance the ability of timbre retaining for speakers without target-accent data. Experimental results show that the proposed system can convert the accent of native American English speech into Indian accent with higher accentedness (3.47) than the baseline (2.75) and input (1.19). The naturalness of converted speech is also comparable to that of the input.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022
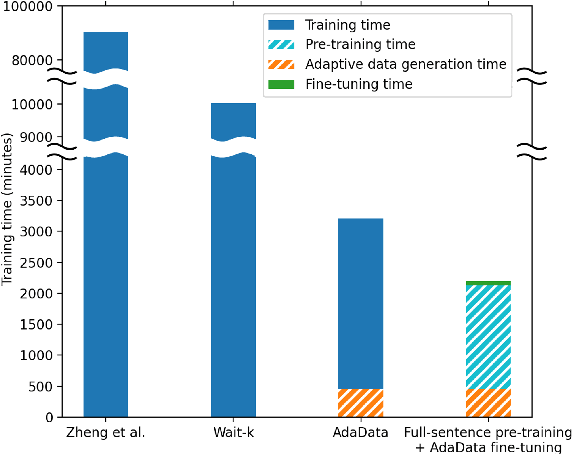
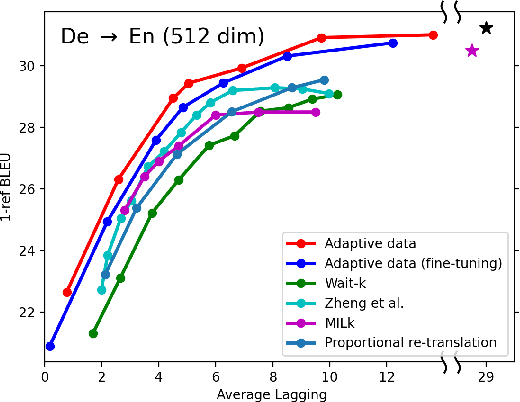
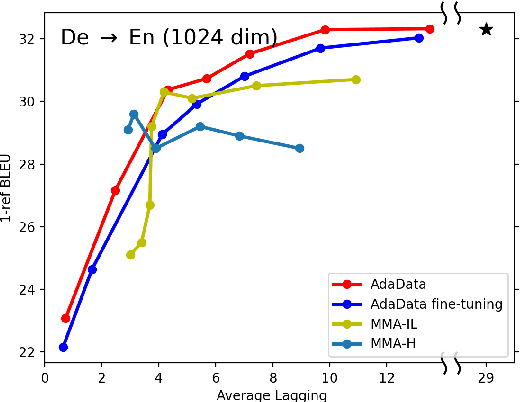
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022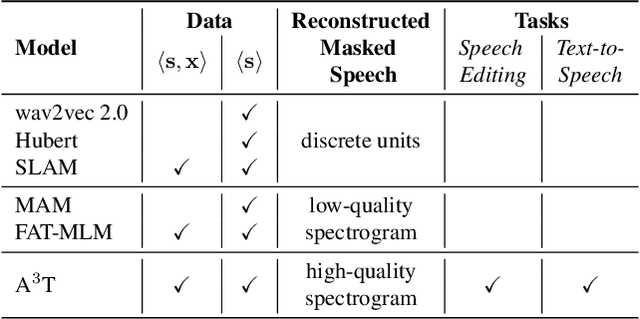
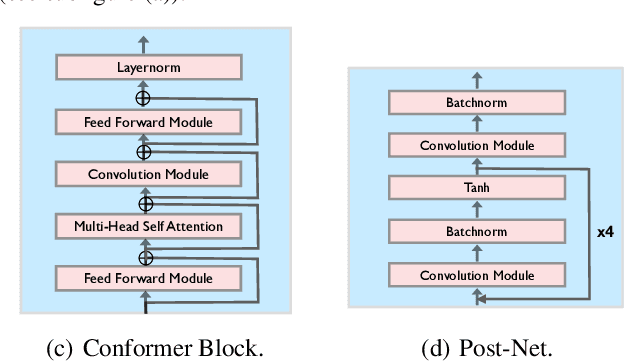

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
Direct Simultaneous Speech-to-Text Translation Assisted by Synchronized Streaming ASR
Jun 11, 2021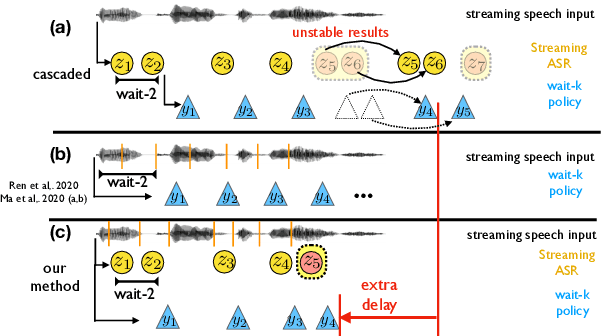
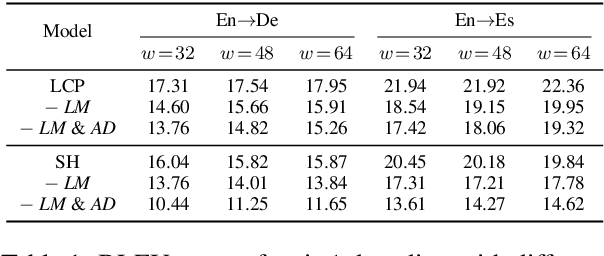
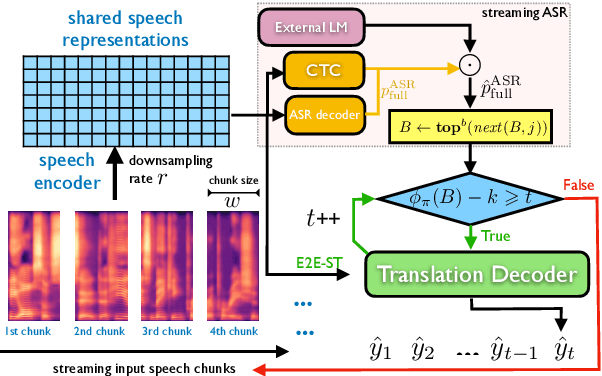
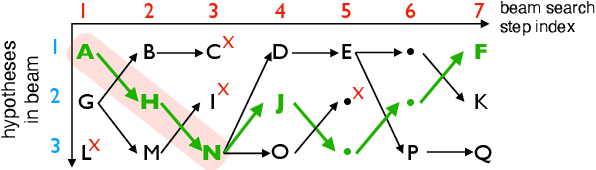
Simultaneous speech-to-text translation is widely useful in many scenarios. The conventional cascaded approach uses a pipeline of streaming ASR followed by simultaneous MT, but suffers from error propagation and extra latency. To alleviate these issues, recent efforts attempt to directly translate the source speech into target text simultaneously, but this is much harder due to the combination of two separate tasks. We instead propose a new paradigm with the advantages of both cascaded and end-to-end approaches. The key idea is to use two separate, but synchronized, decoders on streaming ASR and direct speech-to-text translation (ST), respectively, and the intermediate results of ASR guide the decoding policy of (but is not fed as input to) ST. During training time, we use multitask learning to jointly learn these two tasks with a shared encoder. En-to-De and En-to-Es experiments on the MuSTC dataset demonstrate that our proposed technique achieves substantially better translation quality at similar levels of latency.
Fused Acoustic and Text Encoding for Multimodal Bilingual Pretraining and Speech Translation
Feb 10, 2021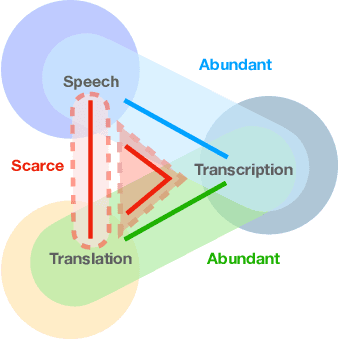
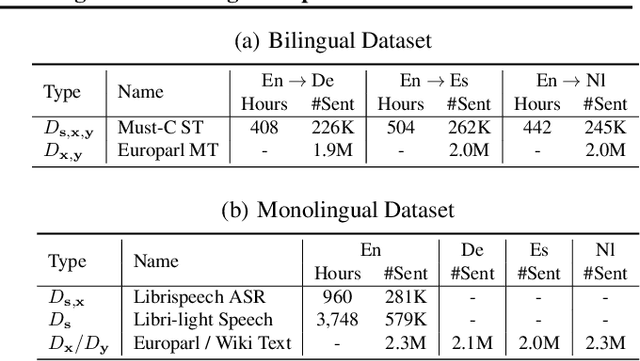
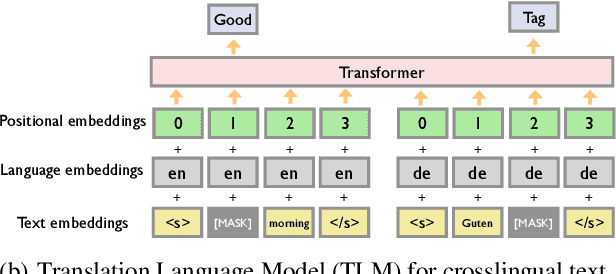
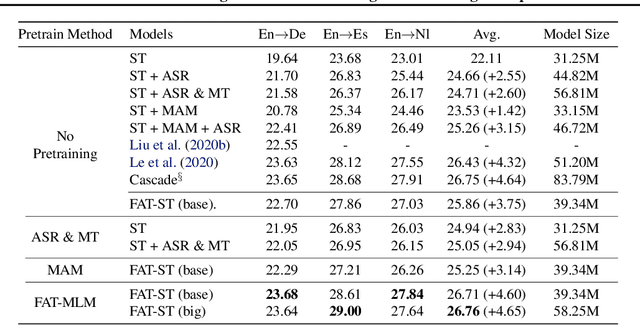
Recently text and speech representation learning has successfully improved many language related tasks. However, all existing methods only learn from one input modality, while a unified acoustic and text representation is desired by many speech-related tasks such as speech translation. We propose a Fused Acoustic and Text Masked Language Model (FAT-MLM) which jointly learns a unified representation for both acoustic and text in-put. Within this cross modal representation learning framework, we further present an end-to-end model for Fused Acoustic and Text Speech Translation (FAT-ST). Experiments on three translation directions show that our proposed speech translation models fine-tuned from FAT-MLM substantially improve translation quality (+5.90 BLEU).