 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Alignment Mitigates Reward Hacking in Reinforcement Learning for Language Models
May 24, 2026Reward hacking arises when a model improves a proxy reward by exploiting shortcuts rather than solving the intended task. We study this failure mode through the geometry of reinforcement learning updates in language models and argue that hacking emerges when optimization drifts away from a stable low-dimensional learning trajectory. We analyze this drift through dominant singular directions of parameter updates and show that reward-hacking runs exhibit substantially larger directional change than clean runs. Motivated by this observation, we introduce trusted-direction projection, which constrains gradients to remain within a clean reference subspace. Across reward-hacking experiments on mathematical reasoning, the proposed approach delays shortcut exploitation and better preserves task performance.
Inference Optimization of Foundation Models on AI Accelerators
Jul 12, 2024



Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022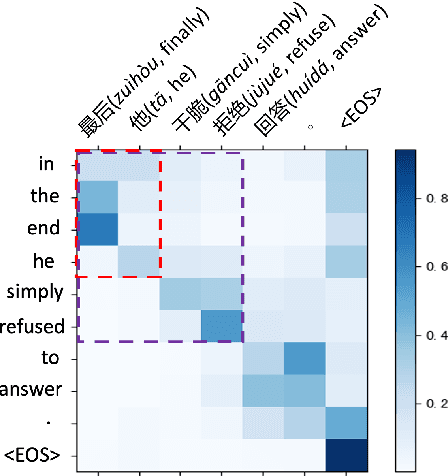
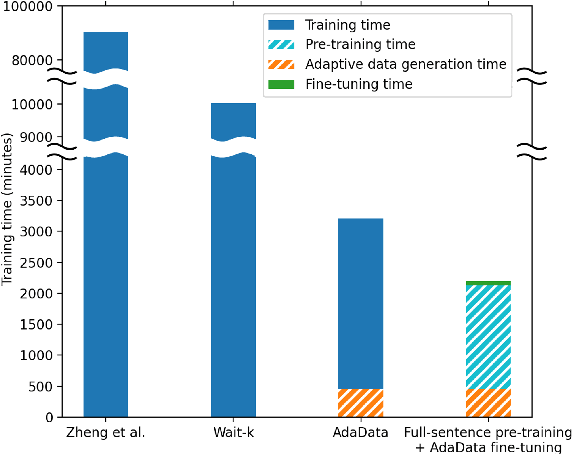
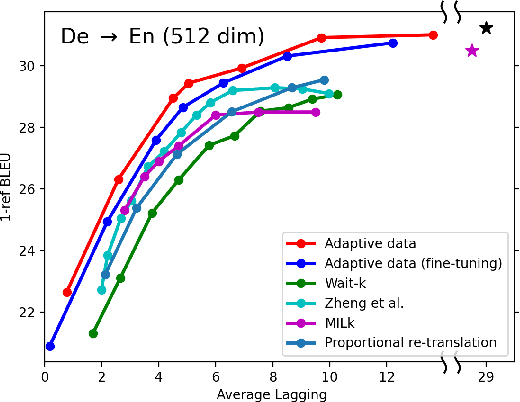
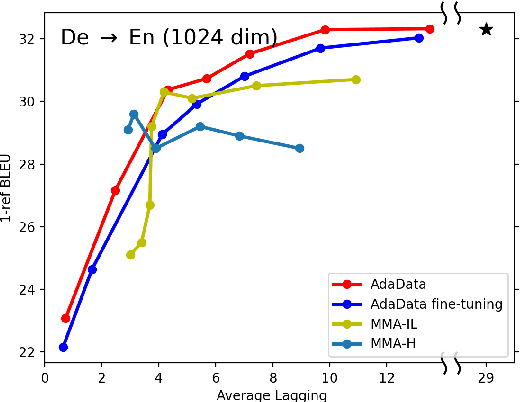
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Exploiting a Zoo of Checkpoints for Unseen Tasks
Nov 05, 2021
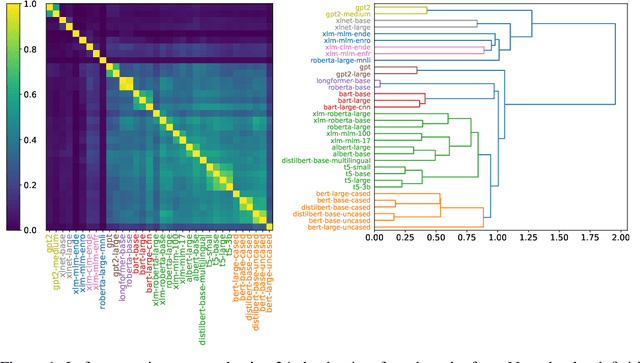
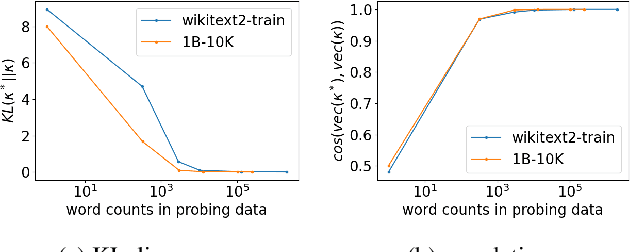

There are so many models in the literature that it is difficult for practitioners to decide which combinations are likely to be effective for a new task. This paper attempts to address this question by capturing relationships among checkpoints published on the web. We model the space of tasks as a Gaussian process. The covariance can be estimated from checkpoints and unlabeled probing data. With the Gaussian process, we can identify representative checkpoints by a maximum mutual information criterion. This objective is submodular. A greedy method identifies representatives that are likely to "cover" the task space. These representatives generalize to new tasks with superior performance. Empirical evidence is provided for applications from both computational linguistics as well as computer vision.
Better than BERT but Worse than Baseline
May 12, 2021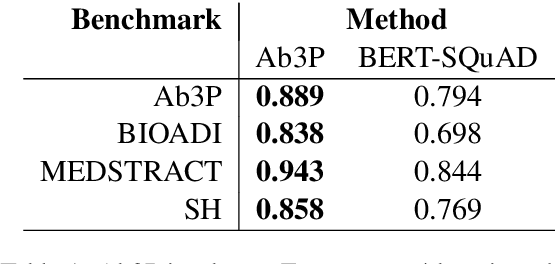
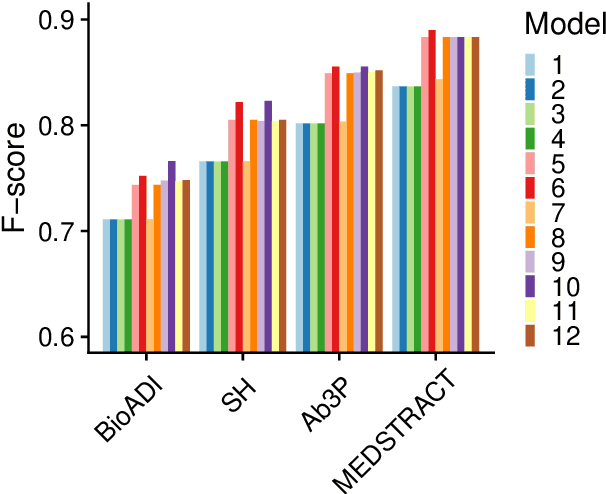
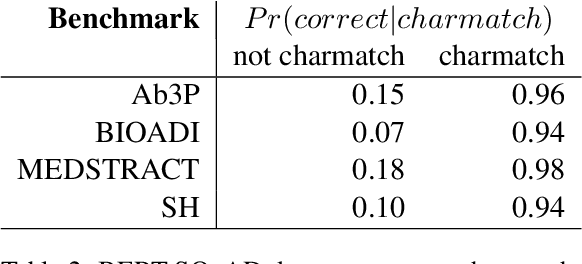
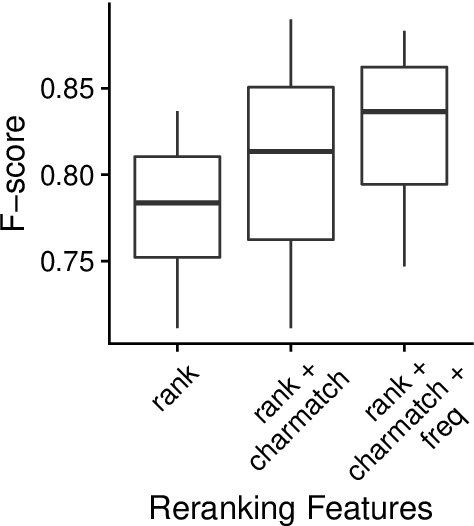
This paper compares BERT-SQuAD and Ab3P on the Abbreviation Definition Identification (ADI) task. ADI inputs a text and outputs short forms (abbreviations/acronyms) and long forms (expansions). BERT with reranking improves over BERT without reranking but fails to reach the Ab3P rule-based baseline. What is BERT missing? Reranking introduces two new features: charmatch and freq. The first feature identifies opportunities to take advantage of character constraints in acronyms and the second feature identifies opportunities to take advantage of frequency constraints across documents.
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Sep 21, 2020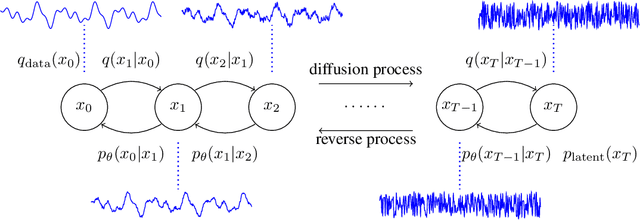
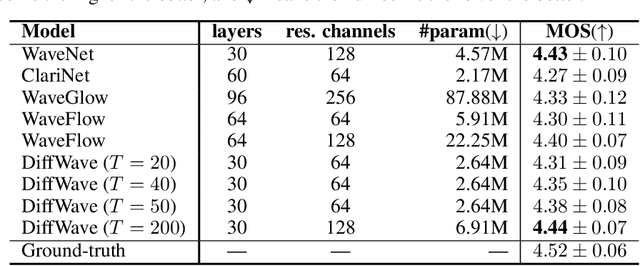
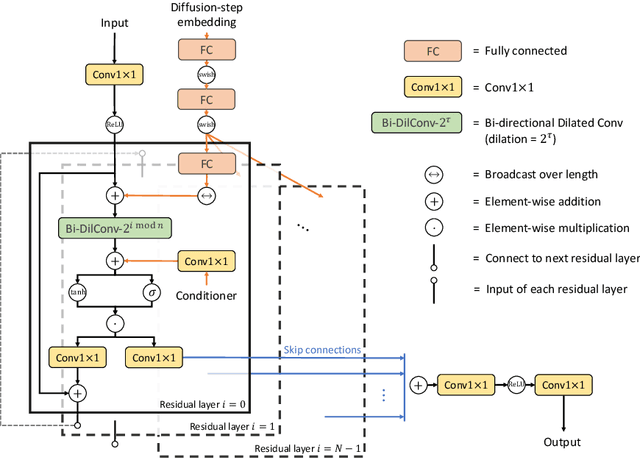
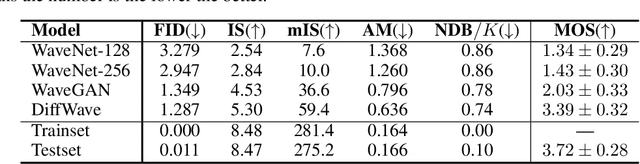
In this work, we propose DiffWave, a versatile Diffusion probabilistic model for conditional and unconditional Waveform generation. The model is non-autoregressive, and converts the white noise signal into structured waveform through a Markov chain with a constant number of steps at synthesis. It is efficiently trained by optimizing a variant of variational bound on the data likelihood. DiffWave produces high-fidelity audios in Different Waveform generation tasks, including neural vocoding conditioned on mel spectrogram, class-conditional generation, and unconditional generation. We demonstrate that DiffWave matches a strong WaveNet vocoder in terms of speech quality~(MOS: 4.44 versus 4.43), while synthesizing orders of magnitude faster. In particular, it significantly outperforms autoregressive and GAN-based waveform models in the challenging unconditional generation task in terms of audio quality and sample diversity from various automatic and human evaluations.
Long-tail Visual Relationship Recognition with a Visiolinguistic Hubless Loss
Apr 20, 2020
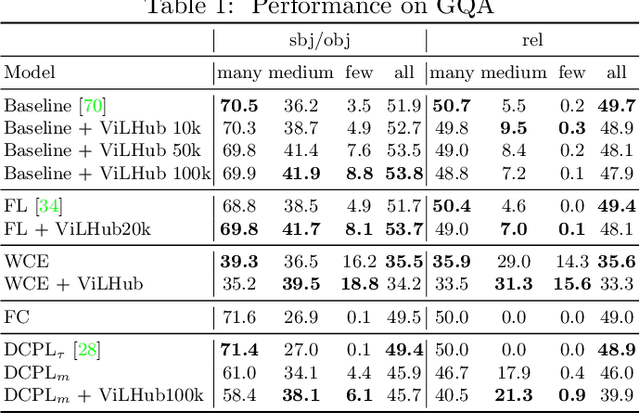
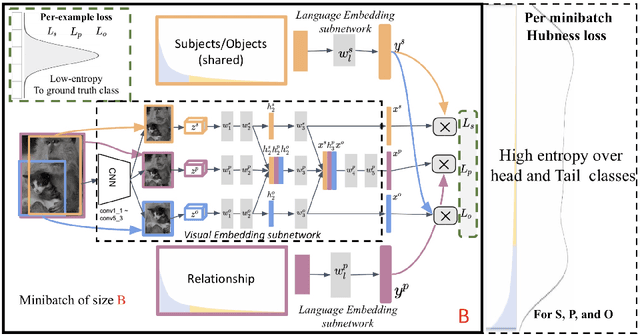
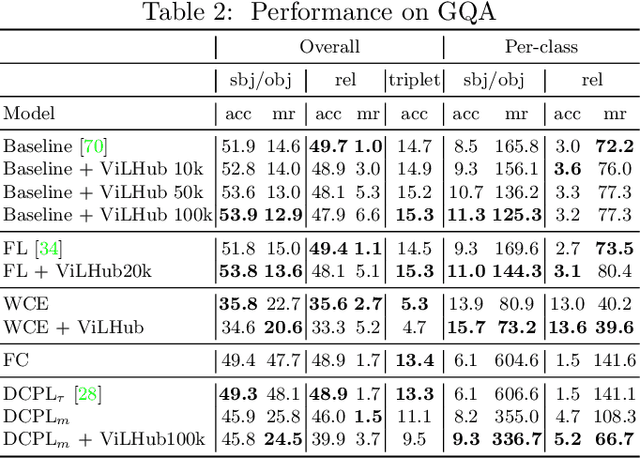
Scaling up the vocabulary and complexity of current visual understanding systems is necessary in order to bridge the gap between human and machine visual intelligence. However, a crucial impediment to this end lies in the difficulty of generalizing to data distributions that come from real-world scenarios. Typically such distributions follow Zipf's law which states that only a small portion of the collected object classes will have abundant examples (head); while most classes will contain just a few (tail). In this paper, we propose to study a novel task concerning the generalization of visual relationships that are on the distribution's tail, i.e. we investigate how to help AI systems to better recognize rare relationships like <S:dog, P:riding, O:horse>, where the subject S, predicate P, and/or the object O come from the tail of the corresponding distributions. To achieve this goal, we first introduce two large-scale visual-relationship detection benchmarks built upon the widely used Visual Genome and GQA datasets. We also propose an intuitive evaluation protocol that gives credit to classifiers who prefer concepts that are semantically close to the ground truth class according to wordNet- or word2vec-induced metrics. Finally, we introduce a visiolinguistic version of a Hubless loss which we show experimentally that it consistently encourages classifiers to be more predictive of the tail classes while still being accurate on head classes. Our code and models are available on http://bit.ly/LTVRR.
Language Modeling at Scale
Oct 23, 2018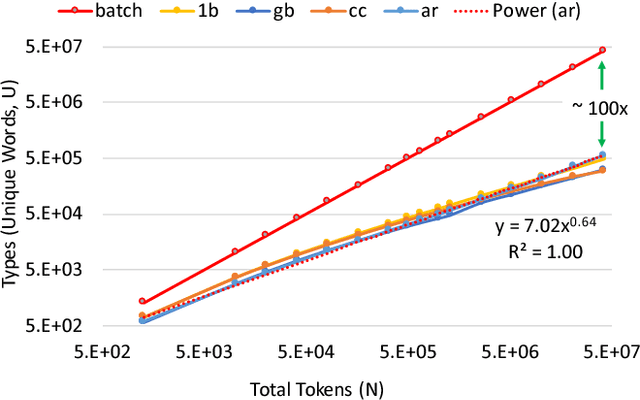
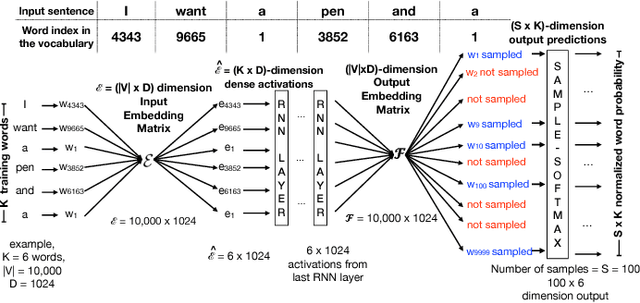
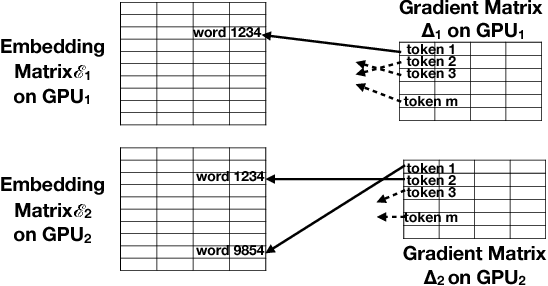
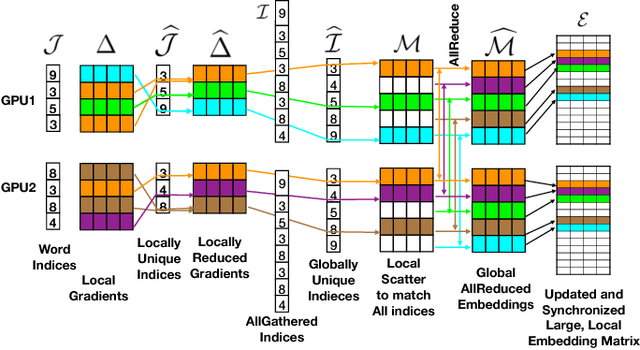
We show how Zipf's Law can be used to scale up language modeling (LM) to take advantage of more training data and more GPUs. LM plays a key role in many important natural language applications such as speech recognition and machine translation. Scaling up LM is important since it is widely accepted by the community that there is no data like more data. Eventually, we would like to train on terabytes (TBs) of text (trillions of words). Modern training methods are far from this goal, because of various bottlenecks, especially memory (within GPUs) and communication (across GPUs). This paper shows how Zipf's Law can address these bottlenecks by grouping parameters for common words and character sequences, because $U \ll N$, where $U$ is the number of unique words (types) and $N$ is the size of the training set (tokens). For a local batch size $K$ with $G$ GPUs and a $D$-dimension embedding matrix, we reduce the original per-GPU memory and communication asymptotic complexity from $\Theta(GKD)$ to $\Theta(GK + UD)$. Empirically, we find $U \propto (GK)^{0.64}$ on four publicly available large datasets. When we scale up the number of GPUs to 64, a factor of 8, training time speeds up by factors up to 6.7$\times$ (for character LMs) and 6.3$\times$ (for word LMs) with negligible loss of accuracy. Our weak scaling on 192 GPUs on the Tieba dataset shows a 35\% improvement in LM prediction accuracy by training on 93 GB of data (2.5$\times$ larger than publicly available SOTA dataset), but taking only 1.25$\times$ increase in training time, compared to 3 GB of the same dataset running on 6 GPUs.
Large Margin Neural Language Model
Aug 27, 2018
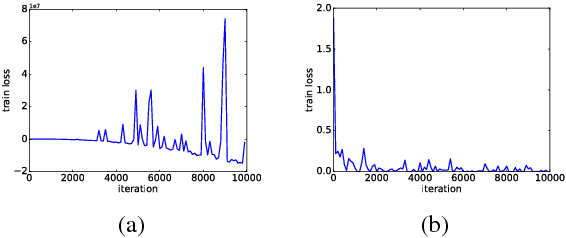

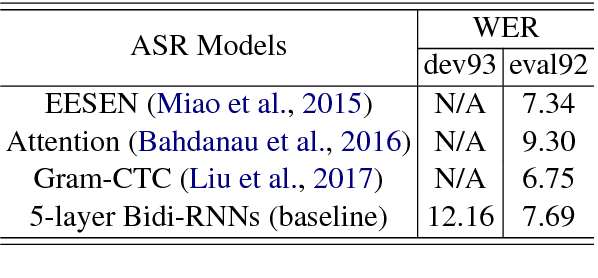
We propose a large margin criterion for training neural language models. Conventionally, neural language models are trained by minimizing perplexity (PPL) on grammatical sentences. However, we demonstrate that PPL may not be the best metric to optimize in some tasks, and further propose a large margin formulation. The proposed method aims to enlarge the margin between the "good" and "bad" sentences in a task-specific sense. It is trained end-to-end and can be widely applied to tasks that involve re-scoring of generated text. Compared with minimum-PPL training, our method gains up to 1.1 WER reduction for speech recognition and 1.0 BLEU increase for machine translation.
Topic Compositional Neural Language Model
Feb 26, 2018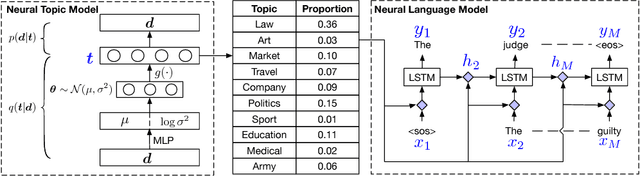


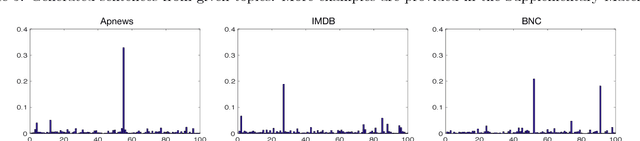
We propose a Topic Compositional Neural Language Model (TCNLM), a novel method designed to simultaneously capture both the global semantic meaning and the local word ordering structure in a document. The TCNLM learns the global semantic coherence of a document via a neural topic model, and the probability of each learned latent topic is further used to build a Mixture-of-Experts (MoE) language model, where each expert (corresponding to one topic) is a recurrent neural network (RNN) that accounts for learning the local structure of a word sequence. In order to train the MoE model efficiently, a matrix factorization method is applied, by extending each weight matrix of the RNN to be an ensemble of topic-dependent weight matrices. The degree to which each member of the ensemble is used is tied to the document-dependent probability of the corresponding topics. Experimental results on several corpora show that the proposed approach outperforms both a pure RNN-based model and other topic-guided language models. Further, our model yields sensible topics, and also has the capacity to generate meaningful sentences conditioned on given topics.