 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Graph Reinforcement Learning for UAV-Enabled Multi-User Secure Communications
Apr 02, 2025



While unmanned aerial vehicles (UAVs) with flexible mobility are envisioned to enhance physical layer security in wireless communications, the efficient security design that adapts to such high network dynamics is rather challenging. The conventional approaches extended from optimization perspectives are usually quite involved, especially when jointly considering factors in different scales such as deployment and transmission in UAV-related scenarios. In this paper, we address the UAV-enabled multi-user secure communications by proposing a deep graph reinforcement learning framework. Specifically, we reinterpret the security beamforming as a graph neural network (GNN) learning task, where mutual interference among users is managed through the message-passing mechanism. Then, the UAV deployment is obtained through soft actor-critic reinforcement learning, where the GNN-based security beamforming is exploited to guide the deployment strategy update. Simulation results demonstrate that the proposed approach achieves near-optimal security performance and significantly enhances the efficiency of strategy determination. Moreover, the deep graph reinforcement learning framework offers a scalable solution, adaptable to various network scenarios and configurations, establishing a robust basis for information security in UAV-enabled communications.
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Sep 21, 2020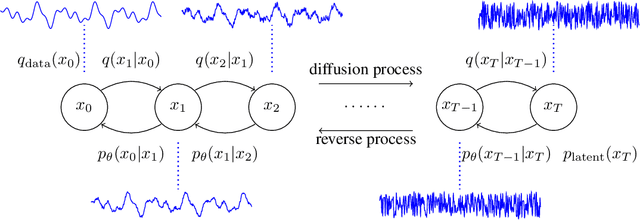
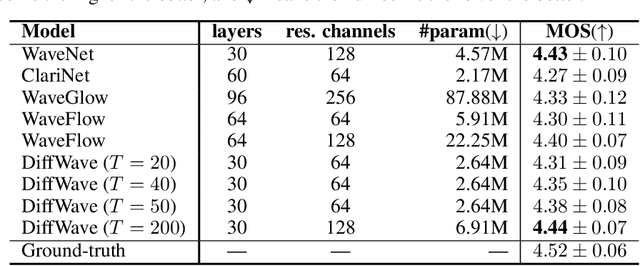
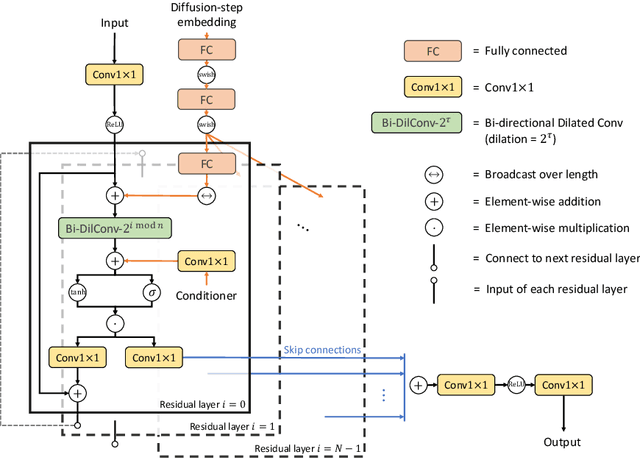
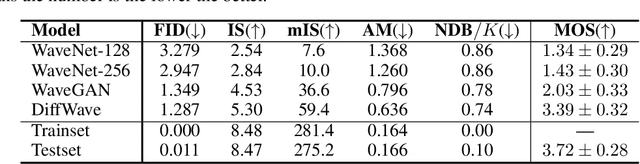
In this work, we propose DiffWave, a versatile Diffusion probabilistic model for conditional and unconditional Waveform generation. The model is non-autoregressive, and converts the white noise signal into structured waveform through a Markov chain with a constant number of steps at synthesis. It is efficiently trained by optimizing a variant of variational bound on the data likelihood. DiffWave produces high-fidelity audios in Different Waveform generation tasks, including neural vocoding conditioned on mel spectrogram, class-conditional generation, and unconditional generation. We demonstrate that DiffWave matches a strong WaveNet vocoder in terms of speech quality~(MOS: 4.44 versus 4.43), while synthesizing orders of magnitude faster. In particular, it significantly outperforms autoregressive and GAN-based waveform models in the challenging unconditional generation task in terms of audio quality and sample diversity from various automatic and human evaluations.
WaveFlow: A Compact Flow-based Model for Raw Audio
Jan 10, 2020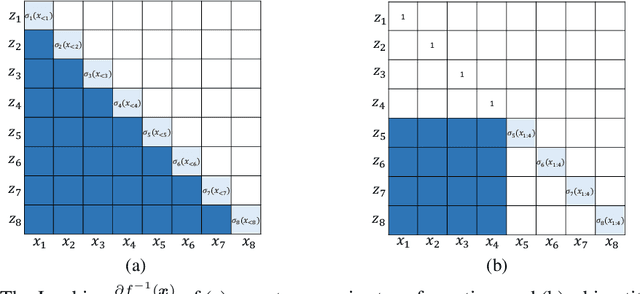



In this work, we propose WaveFlow, a small-footprint generative flow for raw audio, which is directly trained with maximum likelihood. WaveFlow handles the long-range structure of waveform with a dilated 2-D convolutional architecture, while modeling the local variations using compact autoregressive functions. It provides a unified view of likelihood-based models for raw audio, including WaveNet and WaveGlow as special cases. WaveFlow can generate high-fidelity speech as WaveNet, while synthesizing several orders of magnitude faster as it only requires a few sequential steps to generate waveforms with hundreds of thousands of time-steps. Furthermore, it can close the significant likelihood gap that has existed between autoregressive models and flow-based models for efficient synthesis. Finally, our small-footprint WaveFlow has 15$\times$ fewer parameters than WaveGlow and can generate 22.05 kHz high-fidelity audio 42.6$\times$ faster than real-time on a V100 GPU without engineered inference kernels.
Multi-Speaker End-to-End Speech Synthesis
Jul 09, 2019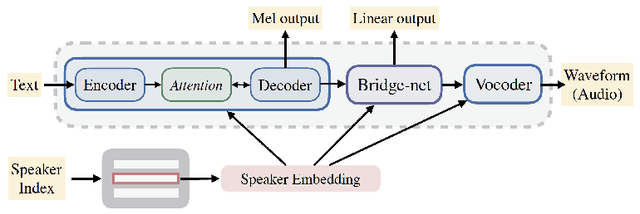
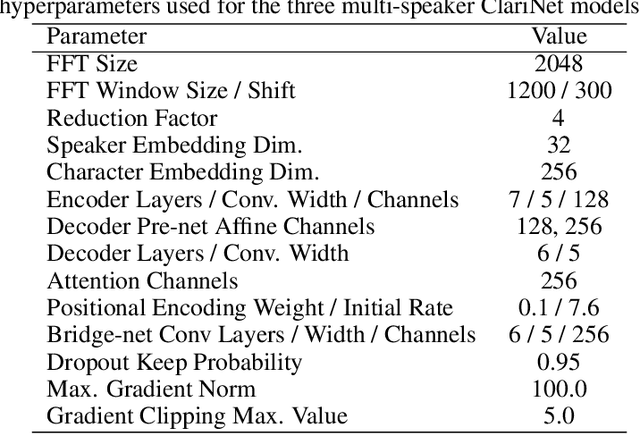
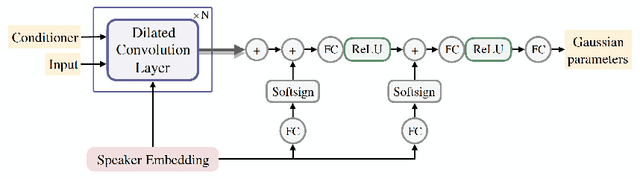
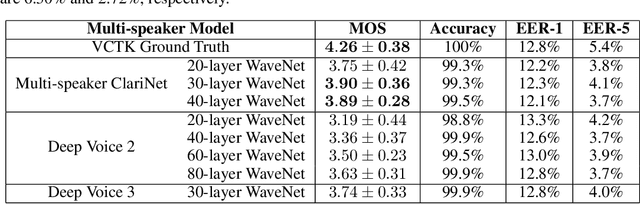
In this work, we extend ClariNet (Ping et al., 2019), a fully end-to-end speech synthesis model (i.e., text-to-wave), to generate high-fidelity speech from multiple speakers. To model the unique characteristic of different voices, low dimensional trainable speaker embeddings are shared across each component of ClariNet and trained together with the rest of the model. We demonstrate that the multi-speaker ClariNet outperforms state-of-the-art systems in terms of naturalness, because the whole model is jointly optimized in an end-to-end manner.
Parallel Neural Text-to-Speech
Jun 05, 2019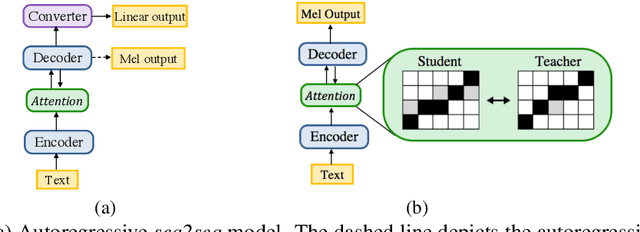
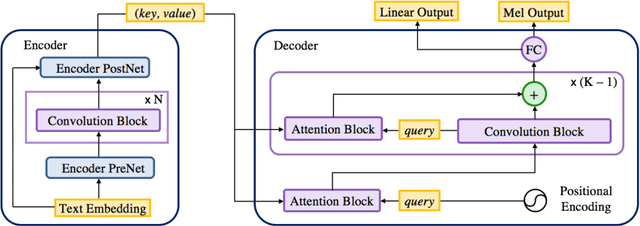

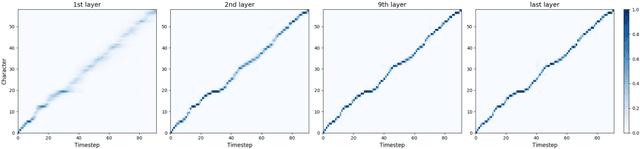
In this work, we propose a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and obtains about 46.7 times speed-up over Deep Voice 3 at synthesis while maintaining comparable speech quality using a WaveNet vocoder. Interestingly, it has even fewer attention errors than the autoregressive model on the challenging test sentences. Furthermore, we build the first fully parallel neural text-to-speech system by applying the inverse autoregressive flow~(IAF) as the parallel neural vocoder. Our system can synthesize speech from text through a single feed-forward pass. We also explore a novel approach to train the IAF from scratch as a generative model for raw waveform, which avoids the need for distillation from a separately trained WaveNet.
Trace norm regularization and faster inference for embedded speech recognition RNNs
Feb 06, 2018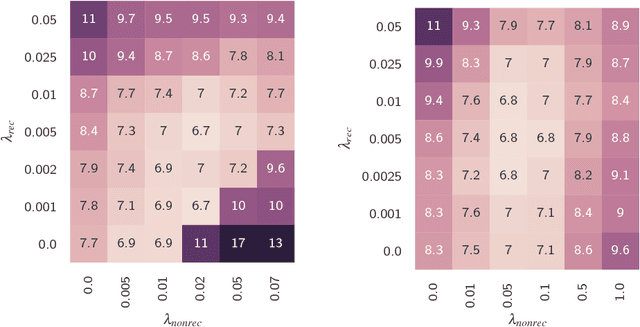

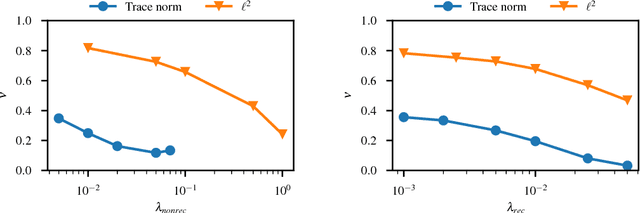
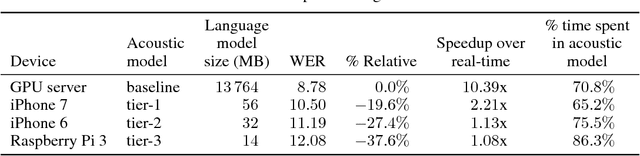
We propose and evaluate new techniques for compressing and speeding up dense matrix multiplications as found in the fully connected and recurrent layers of neural networks for embedded large vocabulary continuous speech recognition (LVCSR). For compression, we introduce and study a trace norm regularization technique for training low rank factored versions of matrix multiplications. Compared to standard low rank training, we show that our method leads to good accuracy versus number of parameter trade-offs and can be used to speed up training of large models. For speedup, we enable faster inference on ARM processors through new open sourced kernels optimized for small batch sizes, resulting in 3x to 7x speed ups over the widely used gemmlowp library. Beyond LVCSR, we expect our techniques and kernels to be more generally applicable to embedded neural networks with large fully connected or recurrent layers.