 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"John is 50 years old, can his son be 65?" Evaluating NLP Models' Understanding of Feasibility
Oct 14, 2022
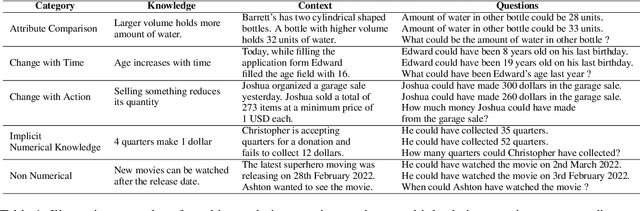
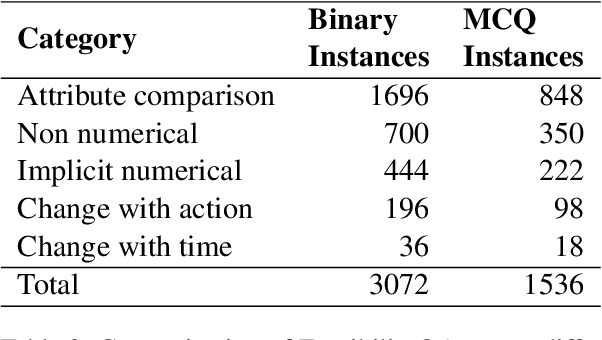

In current NLP research, large-scale language models and their abilities are widely being discussed. Some recent works have also found notable failures of these models. Often these failure examples involve complex reasoning abilities. This work focuses on a simple commonsense ability, reasoning about when an action (or its effect) is feasible. We introduce FeasibilityQA, a question-answering dataset involving binary classification (BCQ) and multi-choice multi-correct questions (MCQ) that test understanding of feasibility. We show that even state-of-the-art models such as GPT-3 struggle to answer the feasibility questions correctly. Specifically, on (MCQ, BCQ) questions, GPT-3 achieves accuracy of just (19%, 62%) and (25%, 64%) in zero-shot and few-shot settings, respectively. We also evaluate models by providing relevant knowledge statements required to answer the question and find that the additional knowledge leads to a 7% gain in performance, but the overall performance still remains low. These results make one wonder how much commonsense knowledge about action feasibility is encoded in GPT-3 and how well the model can reason about it.
The Open Catalyst 2022 Dataset and Challenges for Oxide Electrocatalysis
Jun 17, 2022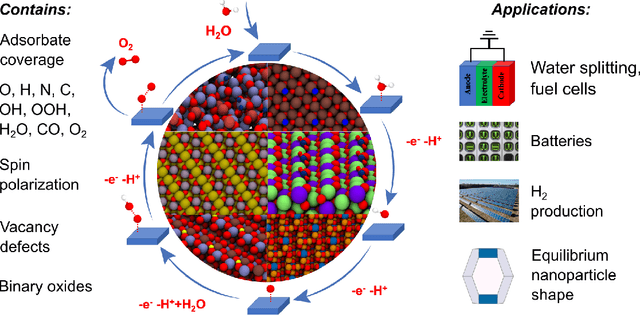
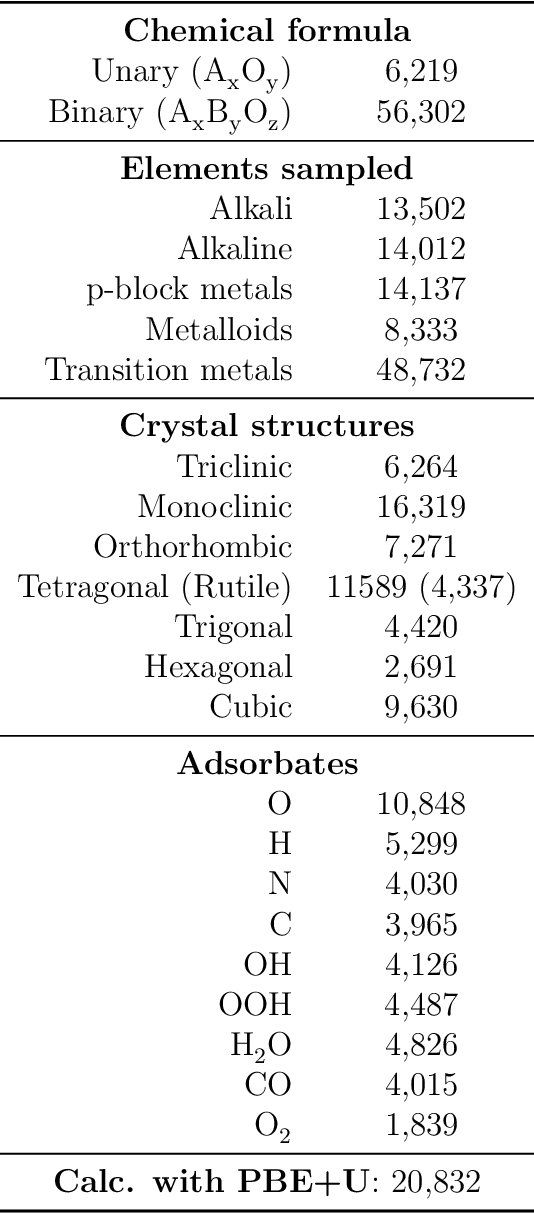
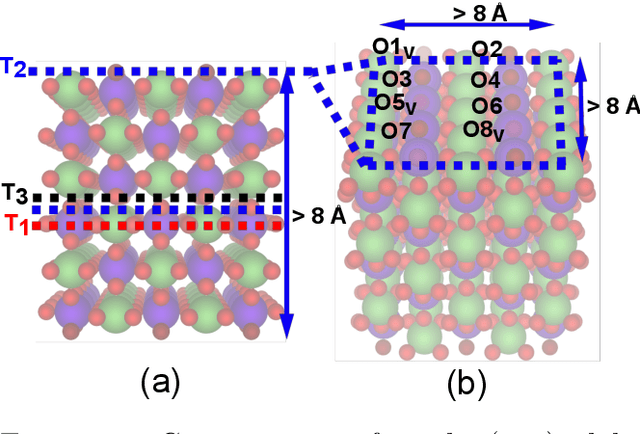

Computational catalysis and machine learning communities have made considerable progress in developing machine learning models for catalyst discovery and design. Yet, a general machine learning potential that spans the chemical space of catalysis is still out of reach. A significant hurdle is obtaining access to training data across a wide range of materials. One important class of materials where data is lacking are oxides, which inhibits models from studying the Oxygen Evolution Reaction and oxide electrocatalysis more generally. To address this we developed the Open Catalyst 2022(OC22) dataset, consisting of 62,521 Density Functional Theory (DFT) relaxations (~9,884,504 single point calculations) across a range of oxide materials, coverages, and adsorbates (*H, *O, *N, *C, *OOH, *OH, *OH2, *O2, *CO). We define generalized tasks to predict the total system energy that are applicable across catalysis, develop baseline performance of several graph neural networks (SchNet, DimeNet++, ForceNet, SpinConv, PaiNN, GemNet-dT, GemNet-OC), and provide pre-defined dataset splits to establish clear benchmarks for future efforts. For all tasks, we study whether combining datasets leads to better results, even if they contain different materials or adsorbates. Specifically, we jointly train models on Open Catalyst 2020 (OC20) Dataset and OC22, or fine-tune pretrained OC20 models on OC22. In the most general task, GemNet-OC sees a ~32% improvement in energy predictions through fine-tuning and a ~9% improvement in force predictions via joint training. Surprisingly, joint training on both the OC20 and much smaller OC22 datasets also improves total energy predictions on OC20 by ~19%. The dataset and baseline models are open sourced, and a public leaderboard will follow to encourage continued community developments on the total energy tasks and data.
Towards Training Billion Parameter Graph Neural Networks for Atomic Simulations
Mar 18, 2022
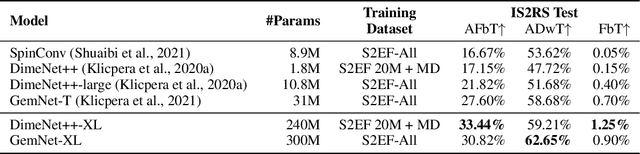
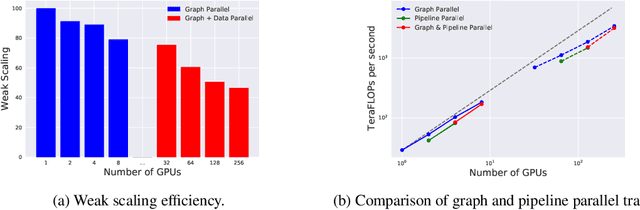
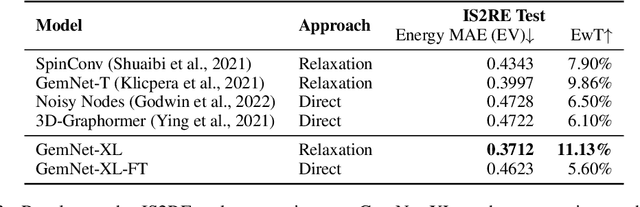
Recent progress in Graph Neural Networks (GNNs) for modeling atomic simulations has the potential to revolutionize catalyst discovery, which is a key step in making progress towards the energy breakthroughs needed to combat climate change. However, the GNNs that have proven most effective for this task are memory intensive as they model higher-order interactions in the graphs such as those between triplets or quadruplets of atoms, making it challenging to scale these models. In this paper, we introduce Graph Parallelism, a method to distribute input graphs across multiple GPUs, enabling us to train very large GNNs with hundreds of millions or billions of parameters. We empirically evaluate our method by scaling up the number of parameters of the recently proposed DimeNet++ and GemNet models by over an order of magnitude. On the large-scale Open Catalyst 2020 (OC20) dataset, these graph-parallelized models lead to relative improvements of 1) 15% on the force MAE metric for the S2EF task and 2) 21% on the AFbT metric for the IS2RS task, establishing new state-of-the-art results.
ForceNet: A Graph Neural Network for Large-Scale Quantum Calculations
Mar 02, 2021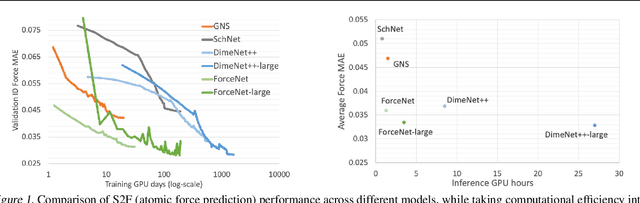
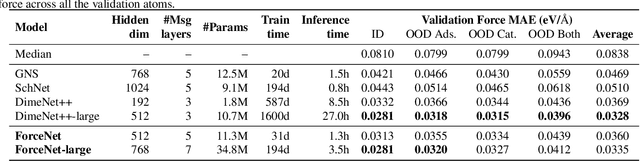

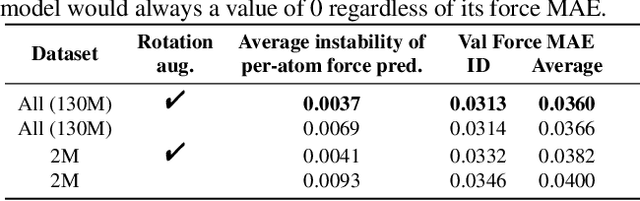
With massive amounts of atomic simulation data available, there is a huge opportunity to develop fast and accurate machine learning models to approximate expensive physics-based calculations. The key quantity to estimate is atomic forces, where the state-of-the-art Graph Neural Networks (GNNs) explicitly enforce basic physical constraints such as rotation-covariance. However, to strictly satisfy the physical constraints, existing models have to make tradeoffs between computational efficiency and model expressiveness. Here we explore an alternative approach. By not imposing explicit physical constraints, we can flexibly design expressive models while maintaining their computational efficiency. Physical constraints are implicitly imposed by training the models using physics-based data augmentation. To evaluate the approach, we carefully design a scalable and expressive GNN model, ForceNet, and apply it to OC20 (Chanussot et al., 2020), an unprecedentedly-large dataset of quantum physics calculations. Our proposed ForceNet is able to predict atomic forces more accurately than state-of-the-art physics-based GNNs while being faster both in training and inference. Overall, our promising and counter-intuitive results open up an exciting avenue for future research.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020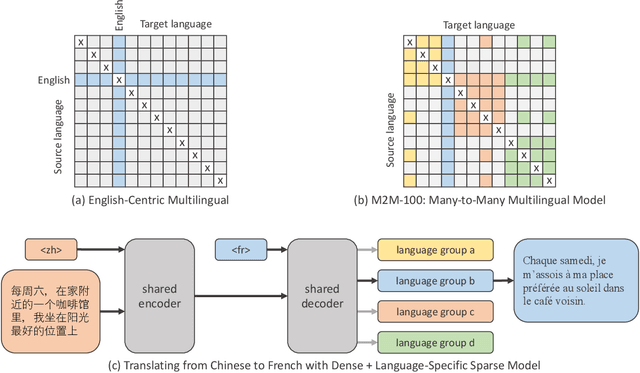
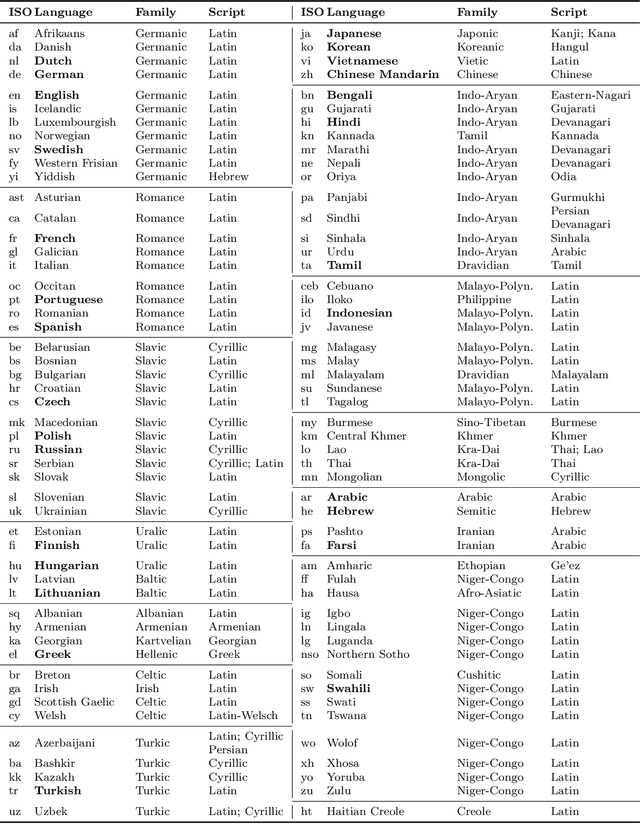
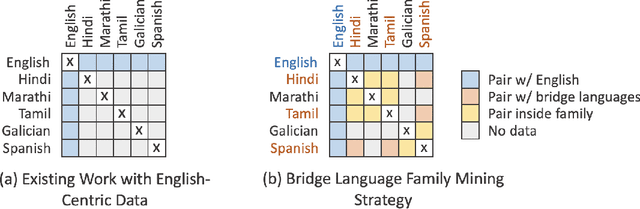

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
The Open Catalyst 2020 Dataset and Community Challenges
Oct 20, 2020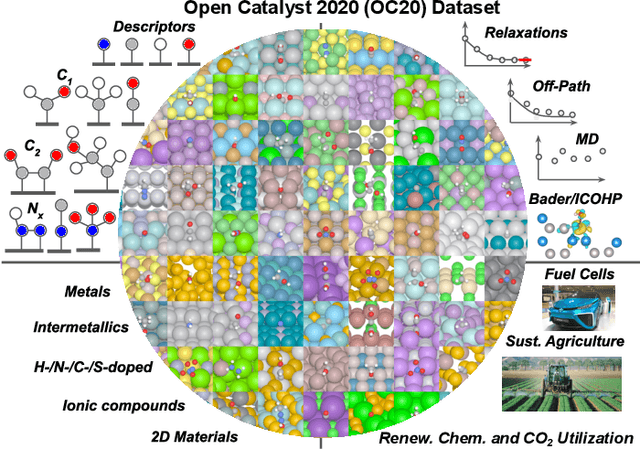

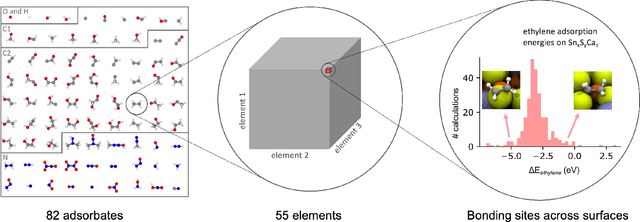
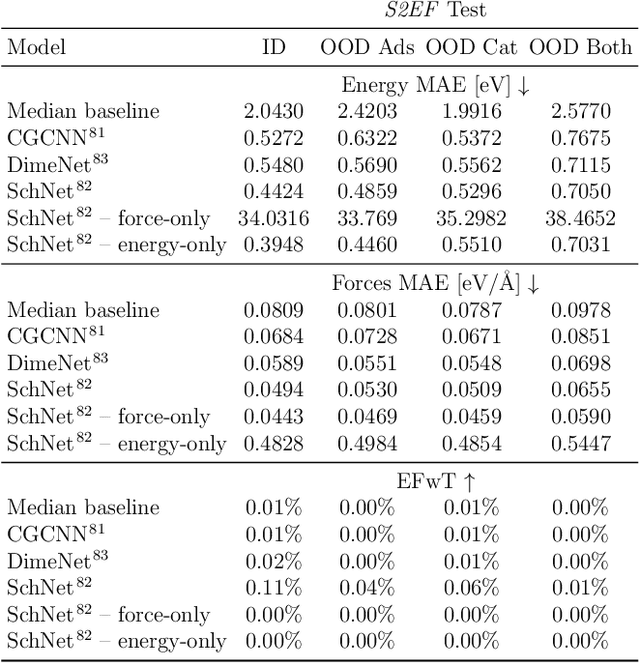
Catalyst discovery and optimization is key to solving many societal and energy challenges including solar fuels synthesis, long-term energy storage, and renewable fertilizer production. Despite considerable effort by the catalysis community to apply machine learning models to the computational catalyst discovery process, it remains an open challenge to build models that can generalize across both elemental compositions of surfaces and adsorbate identity/configurations, perhaps because datasets have been smaller in catalysis than related fields. To address this we developed the OC20 dataset, consisting of 1,281,121 Density Functional Theory (DFT) relaxations (264,900,500 single point evaluations) across a wide swath of materials, surfaces, and adsorbates (nitrogen, carbon, and oxygen chemistries). We supplemented this dataset with randomly perturbed structures, short timescale molecular dynamics, and electronic structure analyses. The dataset comprises three central tasks indicative of day-to-day catalyst modeling and comes with pre-defined train/validation/test splits to facilitate direct comparisons with future model development efforts. We applied three state-of-the-art graph neural network models (SchNet, Dimenet, CGCNN) to each of these tasks as baseline demonstrations for the community to build on. In almost every task, no upper limit on model size was identified, suggesting that even larger models are likely to improve on initial results. The dataset and baseline models are both provided as open resources, as well as a public leader board to encourage community contributions to solve these important tasks.
An Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020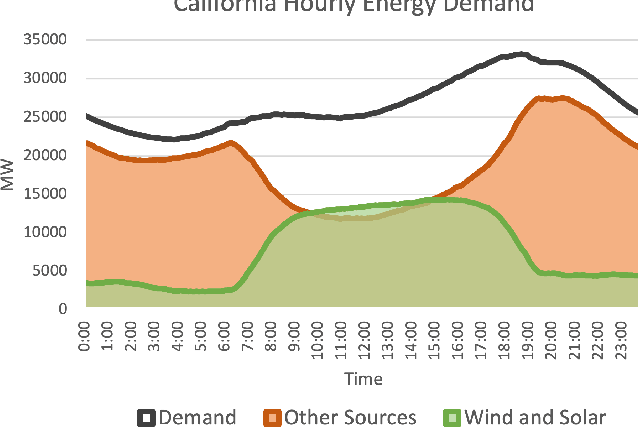
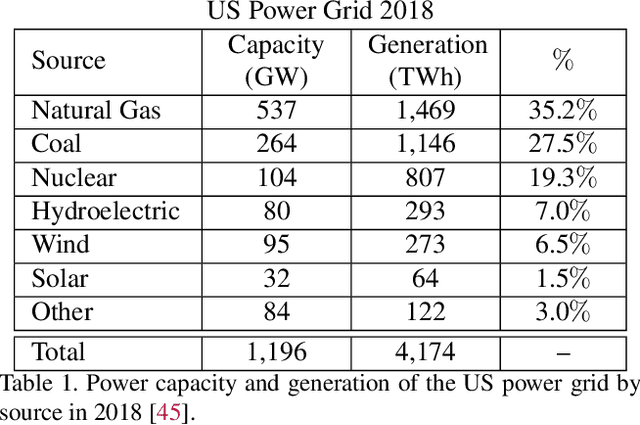
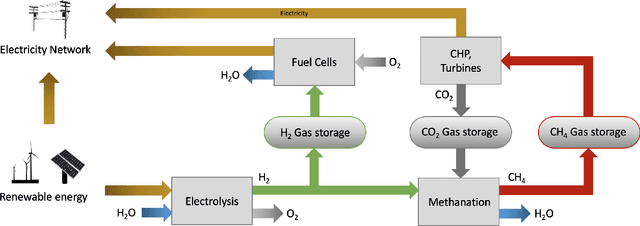
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.
CraftAssist: A Framework for Dialogue-enabled Interactive Agents
Jul 19, 2019
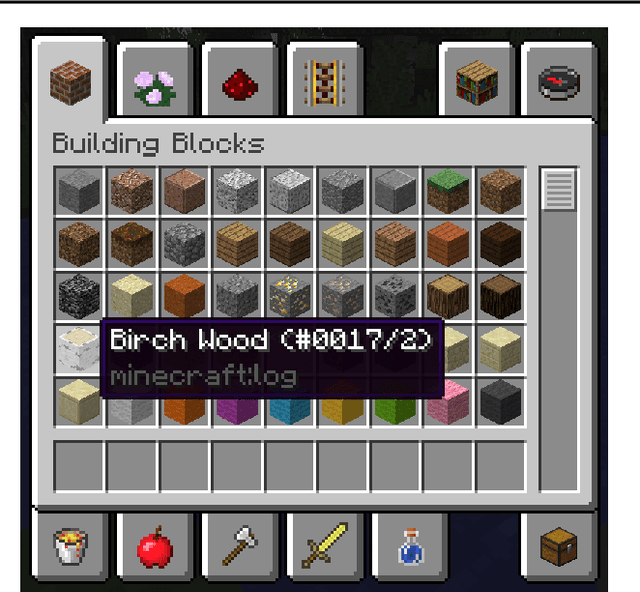
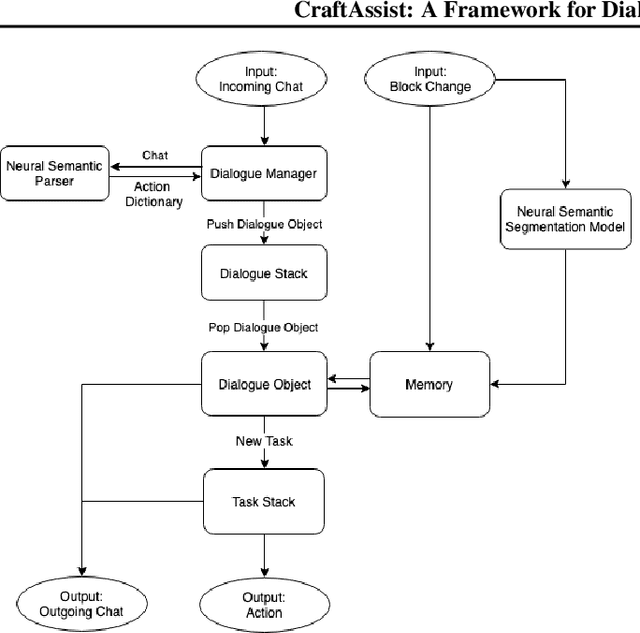

This paper describes an implementation of a bot assistant in Minecraft, and the tools and platform allowing players to interact with the bot and to record those interactions. The purpose of building such an assistant is to facilitate the study of agents that can complete tasks specified by dialogue, and eventually, to learn from dialogue interactions.
Trace norm regularization and faster inference for embedded speech recognition RNNs
Feb 06, 2018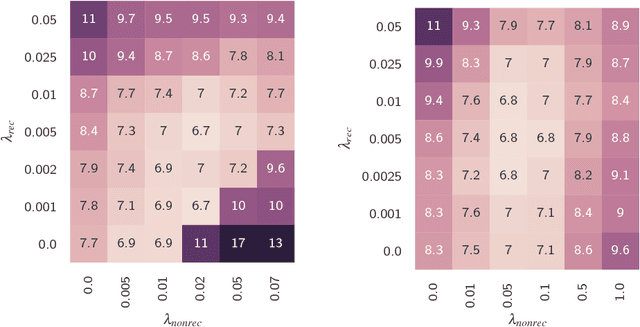

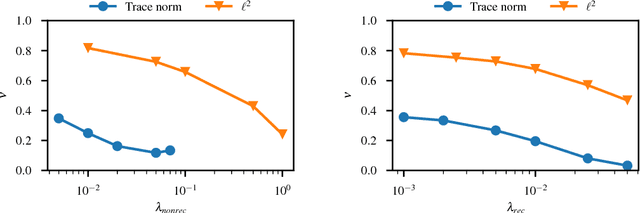
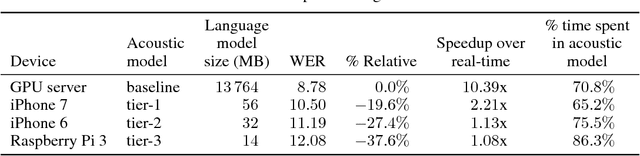
We propose and evaluate new techniques for compressing and speeding up dense matrix multiplications as found in the fully connected and recurrent layers of neural networks for embedded large vocabulary continuous speech recognition (LVCSR). For compression, we introduce and study a trace norm regularization technique for training low rank factored versions of matrix multiplications. Compared to standard low rank training, we show that our method leads to good accuracy versus number of parameter trade-offs and can be used to speed up training of large models. For speedup, we enable faster inference on ARM processors through new open sourced kernels optimized for small batch sizes, resulting in 3x to 7x speed ups over the widely used gemmlowp library. Beyond LVCSR, we expect our techniques and kernels to be more generally applicable to embedded neural networks with large fully connected or recurrent layers.