 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Spatial Priors for Anatomy-Aware Object Detection in Surgical Videos
Jun 13, 2026Detecting anatomical structures in surgical video is essential for intraoperative safety frameworks such as the Critical View of Myopectineal Orifice (CVMPO) in inguinal hernia repair. While prominent structures like the Cooper's Ligament and Triangle of Doom are reliably detected by standard methods, smaller structures such as the epigastric vessels remain challenging due to their visual ambiguity and intermittent visibility. We observe that the spatial relationship between structures is anatomically constrained, and propose a Gaussian Spatial Prior (GSP) module that encodes this relationship as a compact, parametric bias injected into the self-attention of a DAB-DETR decoder. The prior is computed offline from training annotations as a small set of frozen Gaussian parameters and recomputed at each decoder layer using the iteratively refined reference points. On a dataset of inguinal hernia repair videos with 5-fold cross-validation, GSP improves dependent class detection by $+33.5\%$ ($\text{AP}_{50}$) over DAB-DETR and $+53.9\%$ over YOLOv26, while also improving anchor detection by $+6.0\%$. These gains are statistically significant across all folds ($p=0.012$, paired $t-$test).
Translate-R1: Cost-Aware Translation Tool Use via Reinforcement Learning
Jun 05, 2026The performance gap across languages in LLMs is well documented, and closing it natively requires pretraining or fine-tuning on corpora that, for most languages, do not exist. Translation offers an alternative: converting an input into the model's dominant language unlocks its full capabilities at once. Applying translation to every input, however, is wasteful for languages the model already handles, while leaving the choice to the model fails in the opposite way, as LLMs are overconfident and skip the tool even when they cannot understand the input. Prior work resolves this with language-specific rules, domain heuristics, language identifiers, or external routers, each requiring manual engineering. We instead learn a single policy that decides when to translate from reward alone, developing language- and domain-adaptive introspection that assesses its own comprehension and invokes translation only when it cannot solve a task natively. Using data built by our answer-preserving translation pipeline, we continue RL on the post-trained Qwen3-4B across 22 languages in 3 resource tiers (High, Low, XLow) and 5 domains, and introduce confidence-gated GSPO for cost-sensitive tool use. The gated policy lifts reward over the baseline by +4.6 on High, +23.5 on Low, and +17.5 on XLow. Against an unconstrained policy that almost always translates, it preserves full reward at 63% of the cost and is Pareto-optimal across 87% of the cost-sensitivity range. Additionally, to simulate behavior on a completely unseen language, we create 2 synthetic languages, where our gated policy improves +18.7 over the overconfident baseline that underutilizes the tool even on these incomprehensible inputs. The policy transfers zero-shot to 9 held-out languages, and we analyze how tool use emerges over training, per language and per domain.
Efficient Multi-Robot Motion Planning with Precomputed Translation-Invariant Edge Bundles
May 10, 2026Solving multi-robot motion planning (MRMP) requires generating collision-free kinodynamically feasible trajectories for multiple interacting robots. We introduce Kinodynamic Translation-Invariant Edge Bundles or KiTE-Extend, a planner-agnostic action selection mechanism for sampling-based kinodynamic motion planning. KiTE-Extend uses a library of trajectory segments computed offline to guide action selection during online planning, improving the ability of existing planners to identify feasible motion segments without altering state propagation, collision checking, or cost evaluation, and without changing their theoretical guarantees. While KiTE-Extend can modestly improve single-agent planners, its benefits are most clear in the multi-agent setting, where it is able to explore more effectively and significantly improve planning through the dense spatiotemporal constraints introduced by robot-robot interaction. Through experiments on multiple kinodynamic systems and environments, we show that KiTE-Extend reduces planning time and improves scalability across the three most common MRMP paradigms: centralized, prioritized, and conflict-based.
Expert Upcycling: Shifting the Compute-Efficient Frontier of Mixture-of-Experts
Apr 21, 2026Mixture-of-Experts (MoE) has become the dominant architecture for scaling large language models: frontier models routinely decouple total parameters from per-token computation through sparse expert routing. Scaling laws show that under fixed active computation, model quality scales predictably with total parameters, and MoEs realize this by increasing expert count. However, training large MoEs is expensive, as memory requirements and inter-device communication both scale with total parameter count. We propose expert upcycling, a method for progressively expanding MoE capacity by increasing the number of experts during continued pre-training (CPT). Given a trained E-expert model, the upcycling operator constructs an mE-expert model through expert duplication and router extension while holding top-K routing fixed, preserving per-token inference cost. Duplication provides a warm initialization: the expanded model inherits the source checkpoint's learned representations, starting from a substantially lower loss than random initialization. Subsequent CPT then breaks the symmetry among duplicated experts to drive specialization. We formalize the upcycling operator and develop a theoretical framework decomposing the quality gap into a capacity term and an initialization term. We further introduce utility-based expert selection, which uses gradient-based importance scores to guide non-uniform duplication, more than tripling gap closure when CPT is limited. In our 7B-13B total parameter experiments, the upcycled model matches the fixed-size baseline on validation loss while saving 32% of GPU hours. Comprehensive ablations across model scales, activation ratios, MoE architectures, and training budgets yield a practical recipe for deploying expert upcycling, establishing it as a principled, compute-efficient alternative to training large MoE models from scratch.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Study on Stock Forecasting Using Deep Learning and Statistical Models
Feb 08, 2024



Predicting a fast and accurate model for stock price forecasting is been a challenging task and this is an active area of research where it is yet to be found which is the best way to forecast the stock price. Machine learning, deep learning and statistical analysis techniques are used here to get the accurate result so the investors can see the future trend and maximize the return of investment in stock trading. This paper will review many deep learning algorithms for stock price forecasting. We use a record of s&p 500 index data for training and testing. The survey motive is to check various deep learning and statistical model techniques for stock price forecasting that are Moving Averages, ARIMA which are statistical techniques and LSTM, RNN, CNN, and FULL CNN which are deep learning models. It will discuss various models, including the Auto regression integration moving average model, the Recurrent neural network model, the long short-term model which is the type of RNN used for long dependency for data, the convolutional neural network model, and the full convolutional neural network model, in terms of error calculation or percentage of accuracy that how much it is accurate which measures by the function like Root mean square error, mean absolute error, mean squared error. The model can be used to predict the stock price by checking the low MAE value as lower the MAE value the difference between the predicting and the actual value will be less and this model will predict the price more accurately than other models.
Face Detection: Present State and Research Directions
Feb 06, 2024The majority of computer vision applications that handle images featuring humans use face detection as a core component. Face detection still has issues, despite much research on the topic. Face detection's accuracy and speed might yet be increased. This review paper shows the progress made in this area as well as the substantial issues that still need to be tackled. The paper provides research directions that can be taken up as research projects in the field of face detection.
LongBoX: Evaluating Transformers on Long-Sequence Clinical Tasks
Nov 16, 2023Many large language models (LLMs) for medicine have largely been evaluated on short texts, and their ability to handle longer sequences such as a complete electronic health record (EHR) has not been systematically explored. Assessing these models on long sequences is crucial since prior work in the general domain has demonstrated performance degradation of LLMs on longer texts. Motivated by this, we introduce LongBoX, a collection of seven medical datasets in text-to-text format, designed to investigate model performance on long sequences. Preliminary experiments reveal that both medical LLMs (e.g., BioGPT) and strong general domain LLMs (e.g., FLAN-T5) struggle on this benchmark. We further evaluate two techniques designed for long-sequence handling: (i) local-global attention, and (ii) Fusion-in-Decoder (FiD). Our results demonstrate mixed results with long-sequence handling - while scores on some datasets increase, there is substantial room for improvement. We hope that LongBoX facilitates the development of more effective long-sequence techniques for the medical domain. Data and source code are available at https://github.com/Mihir3009/LongBoX.
TarGEN: Targeted Data Generation with Large Language Models
Oct 30, 2023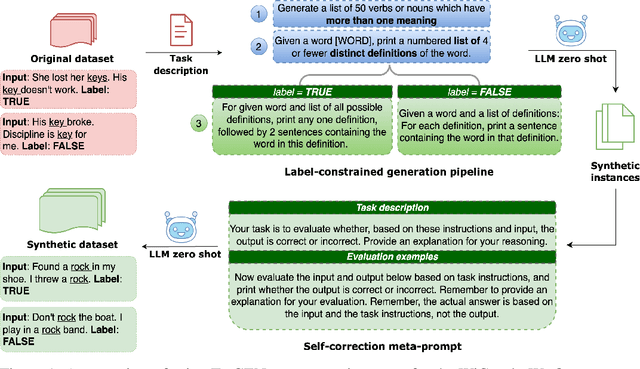
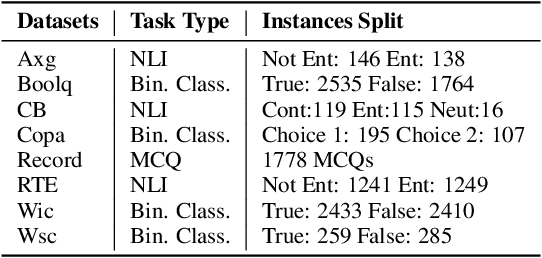
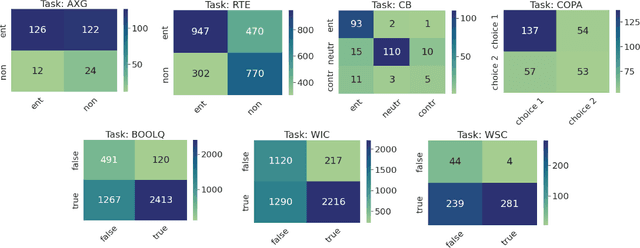
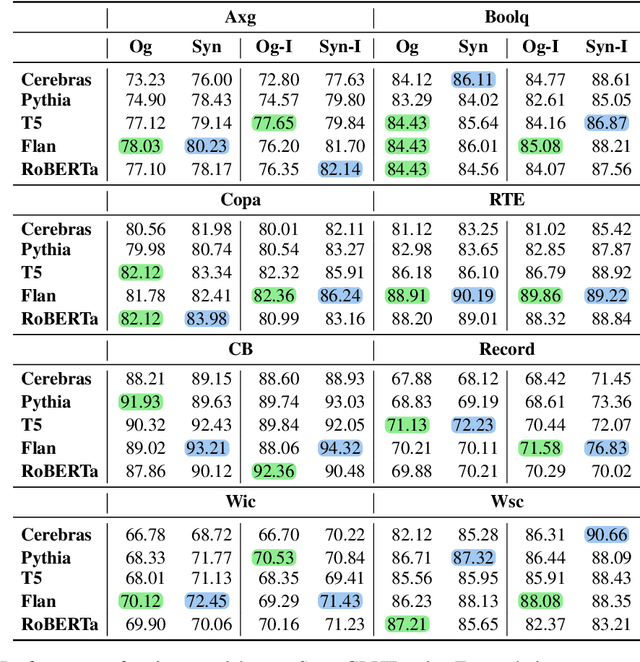
The rapid advancement of large language models (LLMs) has sparked interest in data synthesis techniques, aiming to generate diverse and high-quality synthetic datasets. However, these synthetic datasets often suffer from a lack of diversity and added noise. In this paper, we present TarGEN, a multi-step prompting strategy for generating high-quality synthetic datasets utilizing a LLM. An advantage of TarGEN is its seedless nature; it does not require specific task instances, broadening its applicability beyond task replication. We augment TarGEN with a method known as self-correction empowering LLMs to rectify inaccurately labeled instances during dataset creation, ensuring reliable labels. To assess our technique's effectiveness, we emulate 8 tasks from the SuperGLUE benchmark and finetune various language models, including encoder-only, encoder-decoder, and decoder-only models on both synthetic and original training sets. Evaluation on the original test set reveals that models trained on datasets generated by TarGEN perform approximately 1-2% points better than those trained on original datasets (82.84% via syn. vs. 81.12% on og. using Flan-T5). When incorporating instruction tuning, the performance increases to 84.54% on synthetic data vs. 81.49% on original data by Flan-T5. A comprehensive analysis of the synthetic dataset compared to the original dataset reveals that the synthetic dataset demonstrates similar or higher levels of dataset complexity and diversity. Furthermore, the synthetic dataset displays a bias level that aligns closely with the original dataset. Finally, when pre-finetuned on our synthetic SuperGLUE dataset, T5-3B yields impressive results on the OpenLLM leaderboard, surpassing the model trained on the Self-Instruct dataset by 4.14% points. We hope that TarGEN can be helpful for quality data generation and reducing the human efforts to create complex benchmarks.
Automated Assessment of Critical View of Safety in Laparoscopic Cholecystectomy
Sep 13, 2023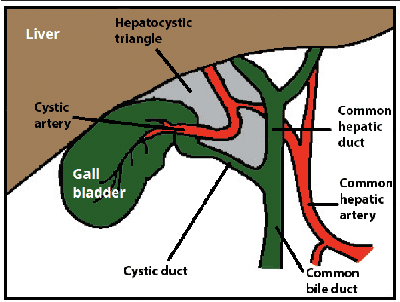
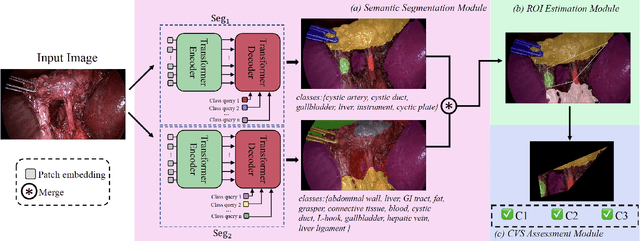
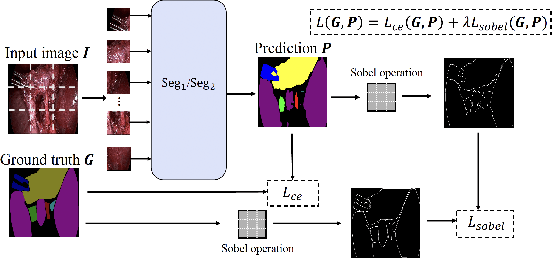
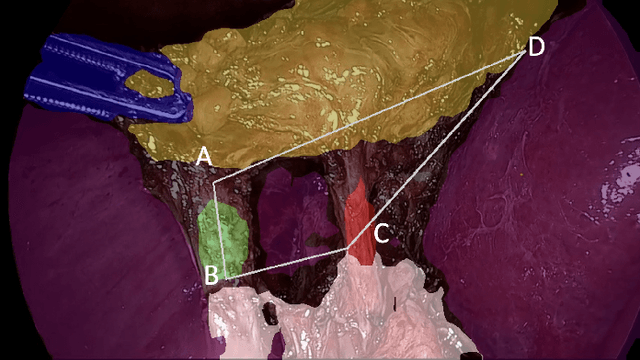
Cholecystectomy (gallbladder removal) is one of the most common procedures in the US, with more than 1.2M procedures annually. Compared with classical open cholecystectomy, laparoscopic cholecystectomy (LC) is associated with significantly shorter recovery period, and hence is the preferred method. However, LC is also associated with an increase in bile duct injuries (BDIs), resulting in significant morbidity and mortality. The primary cause of BDIs from LCs is misidentification of the cystic duct with the bile duct. Critical view of safety (CVS) is the most effective of safety protocols, which is said to be achieved during the surgery if certain criteria are met. However, due to suboptimal understanding and implementation of CVS, the BDI rates have remained stable over the last three decades. In this paper, we develop deep-learning techniques to automate the assessment of CVS in LCs. An innovative aspect of our research is on developing specialized learning techniques by incorporating domain knowledge to compensate for the limited training data available in practice. In particular, our CVS assessment process involves a fusion of two segmentation maps followed by an estimation of a certain region of interest based on anatomical structures close to the gallbladder, and then finally determination of each of the three CVS criteria via rule-based assessment of structural information. We achieved a gain of over 11.8% in mIoU on relevant classes with our two-stream semantic segmentation approach when compared to a single-model baseline, and 1.84% in mIoU with our proposed Sobel loss function when compared to a Transformer-based baseline model. For CVS criteria, we achieved up to 16% improvement and, for the overall CVS assessment, we achieved 5% improvement in balanced accuracy compared to DeepCVS under the same experiment settings.