 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
FusionMind -- Improving question and answering with external context fusion
Dec 31, 2023Answering questions using pre-trained language models (LMs) and knowledge graphs (KGs) presents challenges in identifying relevant knowledge and performing joint reasoning.We compared LMs (fine-tuned for the task) with the previously published QAGNN method for the Question-answering (QA) objective and further measured the impact of additional factual context on the QAGNN performance. The QAGNN method employs LMs to encode QA context and estimate KG node importance, and effectively update the question choice entity representations using Graph Neural Networks (GNNs). We further experimented with enhancing the QA context encoding by incorporating relevant knowledge facts for the question stem. The models are trained on the OpenbookQA dataset, which contains ~6000 4-way multiple choice questions and is widely used as a benchmark for QA tasks. Through our experimentation, we found that incorporating knowledge facts context led to a significant improvement in performance. In contrast, the addition of knowledge graphs to language models resulted in only a modest increase. This suggests that the integration of contextual knowledge facts may be more impactful for enhancing question answering performance compared to solely adding knowledge graphs.
Reducing LLM Hallucinations using Epistemic Neural Networks
Dec 25, 2023Reducing and detecting hallucinations in large language models is an open research problem. In this project, we attempt to leverage recent advances in the field of uncertainty estimation to reduce hallucinations in frozen large language models. Epistemic neural networks have recently been proposed to improve output joint distributions for large pre-trained models. ENNs are small networks attached to large, frozen models to improve the model's joint distributions and uncertainty estimates. In this work, we train an epistemic neural network on top of the Llama-2 7B model combined with a contrastive decoding feature enhancement technique. We are the first to train an ENN for the next token prediction task and explore the efficacy of this method in reducing hallucinations on the TruthfulQA dataset. In essence, we provide a method that leverages a pre-trained model's latent embeddings to reduce hallucinations.
TarGEN: Targeted Data Generation with Large Language Models
Oct 30, 2023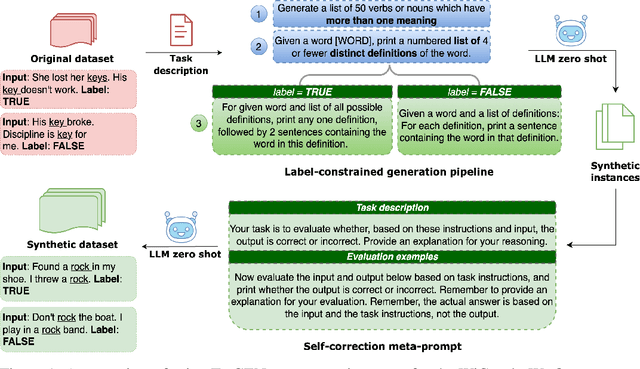
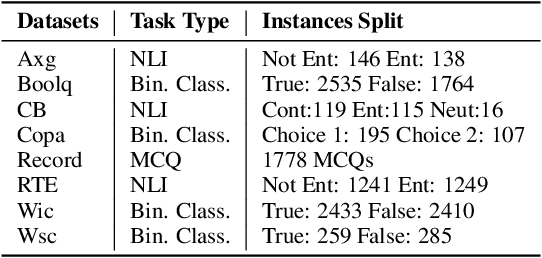
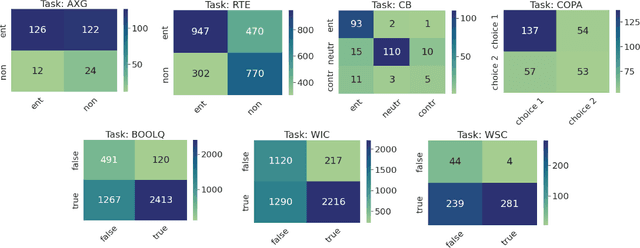
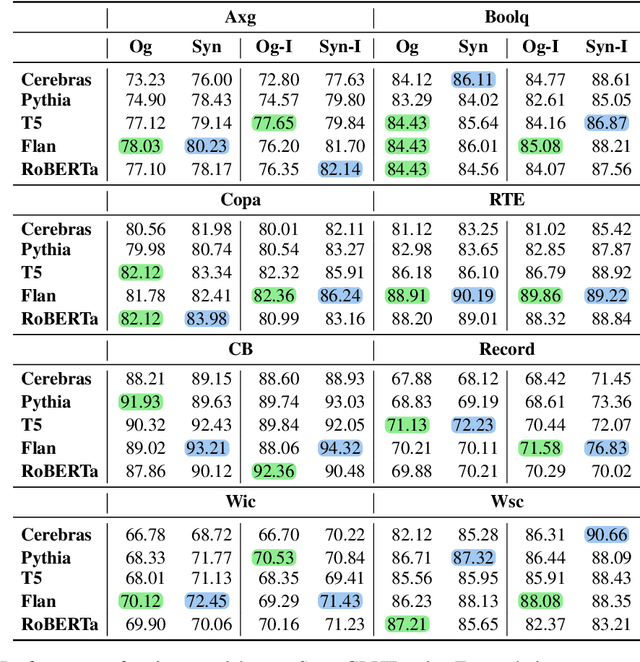
The rapid advancement of large language models (LLMs) has sparked interest in data synthesis techniques, aiming to generate diverse and high-quality synthetic datasets. However, these synthetic datasets often suffer from a lack of diversity and added noise. In this paper, we present TarGEN, a multi-step prompting strategy for generating high-quality synthetic datasets utilizing a LLM. An advantage of TarGEN is its seedless nature; it does not require specific task instances, broadening its applicability beyond task replication. We augment TarGEN with a method known as self-correction empowering LLMs to rectify inaccurately labeled instances during dataset creation, ensuring reliable labels. To assess our technique's effectiveness, we emulate 8 tasks from the SuperGLUE benchmark and finetune various language models, including encoder-only, encoder-decoder, and decoder-only models on both synthetic and original training sets. Evaluation on the original test set reveals that models trained on datasets generated by TarGEN perform approximately 1-2% points better than those trained on original datasets (82.84% via syn. vs. 81.12% on og. using Flan-T5). When incorporating instruction tuning, the performance increases to 84.54% on synthetic data vs. 81.49% on original data by Flan-T5. A comprehensive analysis of the synthetic dataset compared to the original dataset reveals that the synthetic dataset demonstrates similar or higher levels of dataset complexity and diversity. Furthermore, the synthetic dataset displays a bias level that aligns closely with the original dataset. Finally, when pre-finetuned on our synthetic SuperGLUE dataset, T5-3B yields impressive results on the OpenLLM leaderboard, surpassing the model trained on the Self-Instruct dataset by 4.14% points. We hope that TarGEN can be helpful for quality data generation and reducing the human efforts to create complex benchmarks.