 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
May 25, 2026Autonomous research agents produce competitive solutions and professional-looking manuscripts, yet their outputs contain verifiability failures undetectable by surface-level evaluation: fabricated citations, unreproducible scores, and method descriptions that diverge from the implementation. We address this through three contributions. First, Chain-of-Evidence (CoE), a verifiability framework requiring every claim to be traceable to its evidence source. Second, ScientistOne, an end-to-end autonomous research system that maintains evidence chains by construction throughout literature review, solution discovery, and paper writing. Third, CoE Audit, a post-hoc audit whose four integrity checks -- score verification, specification violation, reference verification, and method-code alignment -- apply uniformly to all systems. Across 75 papers spanning five systems and five frontier research tasks, every baseline exhibits at least one systematic failure mode: hallucinated reference rates reach 21%, score verification passes in as few as 42% of papers, and method-code alignment ranges from 20% to 80%. ScientistOne achieves zero hallucinated references (0/337), perfect score verification (12/12), and the highest method-code alignment (14/15), while matching or exceeding human expert performance on all five tasks. ScientistOne further generalizes to six additional tasks spanning medical imaging, fine-grained recognition, 3D perception, and language modeling, achieving state-of-the-art on Parameter Golf and gold medals on MLE-Bench tasks where baselines fail entirely.
LiSA: Lifelong Safety Adaptation via Conservative Policy Induction
May 14, 2026As AI agents move from chat interfaces to systems that read private data, call tools, and execute multi-step workflows, guardrails become a last line of defense against concrete deployment harms. In these settings, guardrail failures are no longer merely answer-quality errors: they can leak secrets, authorize unsafe actions, or block legitimate work. The hardest failures are often contextual: whether an action is acceptable depends on local privacy norms, organizational policies, and user expectations that resist pre-deployment specification. This creates a practical gap: guardrails must adapt to their own operating environments, yet deployment feedback is typically limited to sparse, noisy user-reported failures, and repeated fine-tuning is often impractical. To address this gap, we propose LiSA (Lifelong Safety Adaptation), a conservative policy induction framework that improves a fixed base guardrail through structured memory. LiSA converts occasional failures into reusable policy abstractions so that sparse reports can generalize beyond individual cases, adds conflict-aware local rules to prevent overgeneralization in mixed-label contexts, and applies evidence-aware confidence gating via a posterior lower bound, so that memory reuse scales with accumulated evidence rather than empirical accuracy alone. Across PrivacyLens+, ConFaide+, and AgentHarm, LiSA consistently outperforms strong memory-based baselines under sparse feedback, remains robust under noisy user feedback even at 20% label-flip rates, and pushes the latency--performance frontier beyond backbone model scaling. Ultimately, LiSA offers a practical path to secure AI agents against the unpredictable long tail of real-world edge risks.
Nexus : An Agentic Framework for Time Series Forecasting
May 14, 2026Time series forecasting is not just numerical extrapolation, but often requires reasoning with unstructured contextual data such as news or events. While specialized Time Series Foundation Models (TSFMs) excel at forecasting based on numerical patterns, they remain unaware to real-world textual signals. Conversely, while LLMs are emerging as zero-shot forecasters, their performance remains uneven across domains and contextual grounding. To bridge this gap, we introduce Nexus, a multi-agent forecasting framework that decomposes prediction into specialized stages: isolating macro-level and micro-level temporal fluctuations, and integrating contextual information when available before synthesizing a final forecast. This decomposition enables Nexus to adapt from seasonal signals to volatile, event-driven information without relying on external statistical anchors or monolithic prompting. We show that current-generation LLMs possess substantially stronger intrinsic forecasting ability than previously recognized, depending critically on how numerical and contextual reasoning are organized. Evaluated on data strictly succeeding LLM knowledge cutoffs spanning Zillow real estate metrics and volatile stock market equities, Nexus consistently matches or outperforms state-of-the-art TSFMs and strong LLM baselines. Beyond numerical accuracy, Nexus produces high-quality reasoning traces that explicitly show the fundamental drivers behind each forecast. Our results establish that real-world forecasting is an agentic reasoning problem extending well beyond only sequence modeling.
CoAct: Co-Active LLM Preference Learning with Human-AI Synergy
Apr 19, 2026Learning from preference-based feedback has become an effective approach for aligning LLMs across diverse tasks. However, high-quality human-annotated preference data remains expensive and scarce. Existing methods address this challenge through either self-rewarding, which scales by using purely AI-generated labels but risks unreliability, or active learning, which ensures quality through oracle annotation but cannot fully leverage unlabeled data. In this paper, we present CoAct, a novel framework that synergistically combines self-rewarding and active learning through strategic human-AI collaboration. CoAct leverages self-consistency to identify both reliable self-labeled data and samples that require oracle verification. Additionally, oracle feedback guides the model to generate new instructions within its solvable capability. Evaluated on three reasoning benchmarks across two model families, CoAct achieves average improvements of +13.25% on GSM8K, +8.19% on MATH, and +13.16% on WebInstruct, consistently outperforming all baselines.
CANVAS: Continuity-Aware Narratives via Visual Agentic Storyboarding
Apr 15, 2026Long-form visual storytelling requires maintaining continuity across shots, including consistent characters, stable environments, and smooth scene transitions. While existing generative models can produce strong individual frames, they fail to preserve such continuity, leading to appearance changes, inconsistent backgrounds, and abrupt scene shifts. We introduce CANVAS (Continuity-Aware Narratives via Visual Agentic Storyboarding), a multi-agent framework that explicitly plans visual continuity in multi-shot narratives. CANVAS enforces coherence through character continuity, persistent background anchors, and location-aware scene planning for smooth transitions within the same setting We evaluate CANVAS on two storyboard generation benchmarks ST-BENCH and ViStoryBench and introduce a new challenging benchmark HardContinuityBench for long-range narrative consistency. CANVAS consistently outperforms the best-performing baseline, improving background continuity by 21.6%, character consistency by 9.6% and props consistency by 7.6%.
TFRBench: A Reasoning Benchmark for Evaluating Forecasting Systems
Apr 07, 2026We introduce TFRBench, the first benchmark designed to evaluate the reasoning capabilities of forecasting systems. Traditionally, time-series forecasting has been evaluated solely on numerical accuracy, treating foundation models as ``black boxes.'' Unlike existing benchmarks, TFRBench provides a protocol for evaluating the reasoning generated by forecasting systems--specifically their analysis of cross-channel dependencies, trends, and external events. To enable this, we propose a systematic multi-agent framework that utilizes an iterative verification loop to synthesize numerically grounded reasoning traces. Spanning ten datasets across five domains, our evaluation confirms that this reasoning is causally effective; useful for evaluation; and prompting LLMs with our generated traces significantly improves forecasting accuracy compared to direct numerical prediction (e.g., avg. $\sim40.2\%\to56.6\%)$, validating the quality of our reasoning. Conversely, benchmarking experiments reveal that off-the-shelf LLMs consistently struggle with both reasoning (lower LLM-as-a-Judge scores) and numerical forecasting, frequently failing to capture domain-specific dynamics. TFRBench thus establishes a new standard for interpretable, reasoning-based evaluation in time-series forecasting. Our benchmark is available at: https://tfrbench.github.io
CausalArmor: Efficient Indirect Prompt Injection Guardrails via Causal Attribution
Feb 08, 2026AI agents equipped with tool-calling capabilities are susceptible to Indirect Prompt Injection (IPI) attacks. In this attack scenario, malicious commands hidden within untrusted content trick the agent into performing unauthorized actions. Existing defenses can reduce attack success but often suffer from the over-defense dilemma: they deploy expensive, always-on sanitization regardless of actual threat, thereby degrading utility and latency even in benign scenarios. We revisit IPI through a causal ablation perspective: a successful injection manifests as a dominance shift where the user request no longer provides decisive support for the agent's privileged action, while a particular untrusted segment, such as a retrieved document or tool output, provides disproportionate attributable influence. Based on this signature, we propose CausalArmor, a selective defense framework that (i) computes lightweight, leave-one-out ablation-based attributions at privileged decision points, and (ii) triggers targeted sanitization only when an untrusted segment dominates the user intent. Additionally, CausalArmor employs retroactive Chain-of-Thought masking to prevent the agent from acting on ``poisoned'' reasoning traces. We present a theoretical analysis showing that sanitization based on attribution margins conditionally yields an exponentially small upper bound on the probability of selecting malicious actions. Experiments on AgentDojo and DoomArena demonstrate that CausalArmor matches the security of aggressive defenses while improving explainability and preserving utility and latency of AI agents.
ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review
Jan 30, 2026Automated peer review has evolved from simple text classification to structured feedback generation. However, current state-of-the-art systems still struggle with "surface-level" critiques: they excel at summarizing content but often fail to accurately assess novelty and significance or identify deep methodological flaws because they evaluate papers in a vacuum, lacking the external context a human expert possesses. In this paper, we introduce ScholarPeer, a search-enabled multi-agent framework designed to emulate the cognitive processes of a senior researcher. ScholarPeer employs a dual-stream process of context acquisition and active verification. It dynamically constructs a domain narrative using a historian agent, identifies missing comparisons via a baseline scout, and verifies claims through a multi-aspect Q&A engine, grounding the critique in live web-scale literature. We evaluate ScholarPeer on DeepReview-13K and the results demonstrate that ScholarPeer achieves significant win-rates against state-of-the-art approaches in side-by-side evaluations and reduces the gap to human-level diversity.
Synapse: Adaptive Arbitration of Complementary Expertise in Time Series Foundational Models
Nov 07, 2025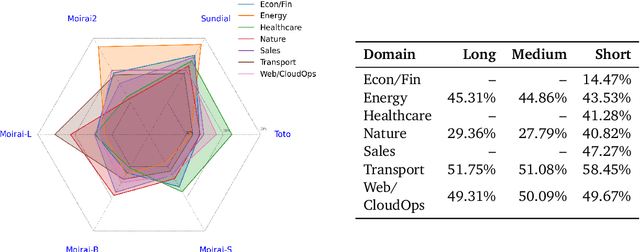
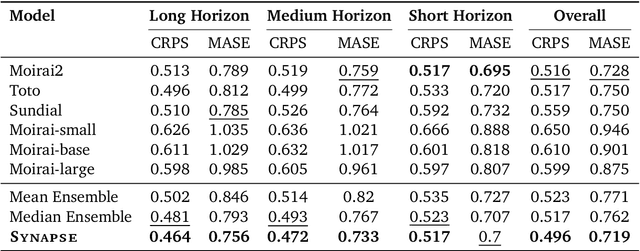
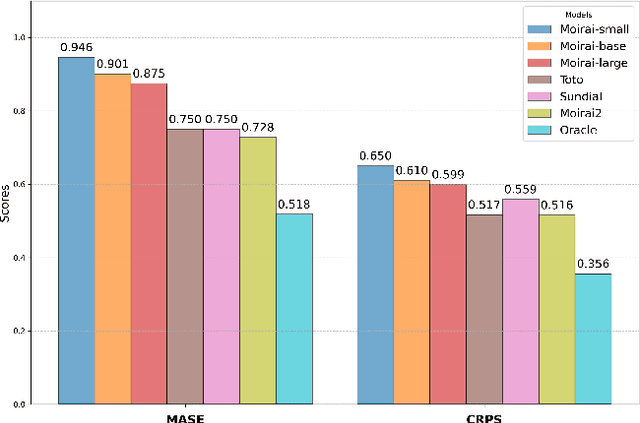

Pre-trained Time Series Foundational Models (TSFMs) represent a significant advance, capable of forecasting diverse time series with complex characteristics, including varied seasonalities, trends, and long-range dependencies. Despite their primary goal of universal time series forecasting, their efficacy is far from uniform; divergent training protocols and data sources cause individual TSFMs to exhibit highly variable performance across different forecasting tasks, domains, and horizons. Leveraging this complementary expertise by arbitrating existing TSFM outputs presents a compelling strategy, yet this remains a largely unexplored area of research. In this paper, we conduct a thorough examination of how different TSFMs exhibit specialized performance profiles across various forecasting settings, and how we can effectively leverage this behavior in arbitration between different time series models. We specifically analyze how factors such as model selection and forecast horizon distribution can influence the efficacy of arbitration strategies. Based on this analysis, we propose Synapse, a novel arbitration framework for TSFMs. Synapse is designed to dynamically leverage a pool of TSFMs, assign and adjust predictive weights based on their relative, context-dependent performance, and construct a robust forecast distribution by adaptively sampling from the output quantiles of constituent models. Experimental results demonstrate that Synapse consistently outperforms other popular ensembling techniques as well as individual TSFMs, demonstrating Synapse's efficacy in time series forecasting.
ThinkTuning: Instilling Cognitive Reflections without Distillation
Aug 11, 2025
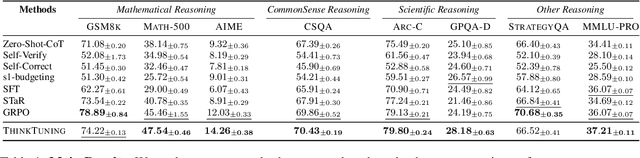
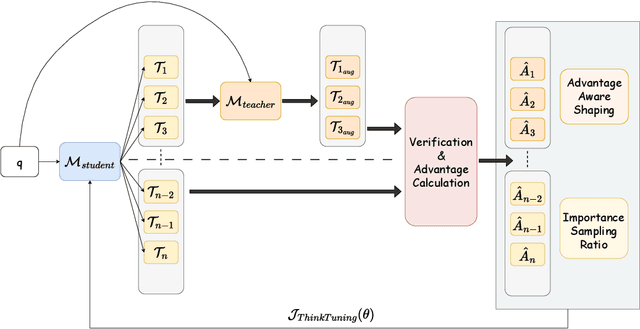
Recent advances in test-time scaling have led to the emergence of thinking LLMs that exhibit self-reflective behaviors and multi-step reasoning. While RL drives this self-improvement paradigm, a recent study (Gandhi et al., 2025) shows that RL alone does not truly instill these new reasoning abilities - it merely draws out behaviors already present in the base models. This raises a question: How can we train the models that don't exhibit such thinking behavior to develop it in the first place? To this end, we propose ThinkTuning, a GRPO-based interactive training approach where we augment the rollouts of a student model with the guidance from a teacher model. A simple idea from classroom practice inspires our method: a teacher poses a problem, lets the student try an answer, then gives corrective feedback -- enough to point the mind in the right direction and then show the solution. Each piece of feedback reshapes the student's thoughts, leading them to arrive at the correct solution. Similarly, we find that this type of implicit supervision through feedback from a teacher model of the same size improves the reasoning capabilities of the student model. In particular, on average, our method shows a 3.85% improvement over zero-shot baselines across benchmarks, and on MATH-500, AIME and GPQA-Diamond it shows 2.08%, 2.23% and 3.99% improvements over the vanilla-GRPO baseline. Source code is available at https://github.com/3rdAT/ThinkTuning.