 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Disagreement in Health-Literacy Annotation: Epistemic Stability, Conceptual Difficulty, and Agreement-Stratified Inference
Apr 21, 2026Annotation pipelines in Natural Language Processing (NLP) commonly assume a single latent ground truth per instance and resolve disagreement through label aggregation. Perspectivist approaches challenge this view by treating disagreement as potentially informative rather than erroneous. We present a large-scale analysis of graded health-literacy annotations from 6,323 open-ended COVID-19 responses collected in Ecuador and Peru. Each response was independently labeled by multiple annotators using proportional correctness scores, reflecting the degree to which responses align with normative public-health guidelines, allowing us to analyze the full distribution of judgments rather than aggregated labels. Variance decomposition shows that question-level conceptual difficulty accounts for substantially more variance than annotator identity, indicating that disagreement is structured by the task itself rather than driven by individual raters. Agreement-stratified analyses further reveal that key social-scientific effects, including country, education, and urban-rural differences, vary in magnitude and in some cases reverse direction across levels of inter-annotator agreement. These findings suggest that graded health-literacy evaluation contains both epistemically stable and unstable components, and that aggregating across them can obscure important inferential differences. We therefore argue that strong perspectivist modeling is not only conceptually justified but statistically necessary for valid inference in graded interpretive tasks.
Lost in Speech: Benchmarking, Evaluation, and Parsing of Spoken Code-Switching Beyond Standard UD Assumptions
Feb 06, 2026Spoken code-switching (CSW) challenges syntactic parsing in ways not observed in written text. Disfluencies, repetition, ellipsis, and discourse-driven structure routinely violate standard Universal Dependencies (UD) assumptions, causing parsers and large language models (LLMs) to fail despite strong performance on written data. These failures are compounded by rigid evaluation metrics that conflate genuine structural errors with acceptable variation. In this work, we present a systems-oriented approach to spoken CSW parsing. We introduce a linguistically grounded taxonomy of spoken CSW phenomena and SpokeBench, an expert-annotated gold benchmark designed to test spoken-language structure beyond standard UD assumptions. We further propose FLEX-UD, an ambiguity-aware evaluation metric, which reveals that existing parsing techniques perform poorly on spoken CSW by penalizing linguistically plausible analyses as errors. We then propose DECAP, a decoupled agentic parsing framework that isolates spoken-phenomena handling from core syntactic analysis. Experiments show that DECAP produces more robust and interpretable parses without retraining and achieves up to 52.6% improvements over existing parsing techniques. FLEX-UD evaluations further reveal qualitative improvements that are masked by standard metrics.
Parsing the Switch: LLM-Based UD Annotation for Complex Code-Switched and Low-Resource Languages
Jun 08, 2025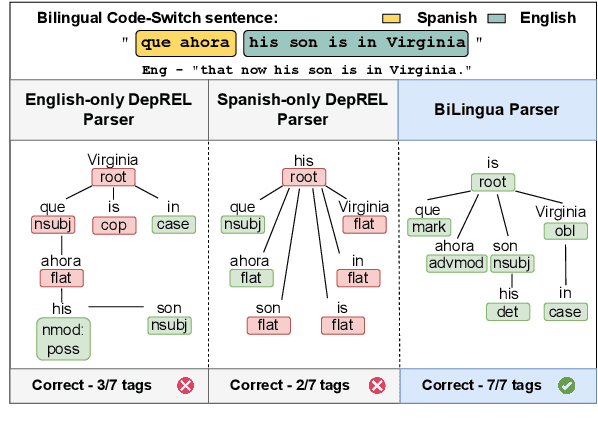
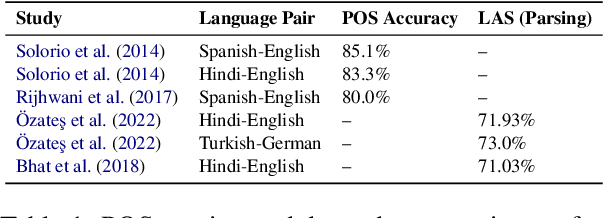
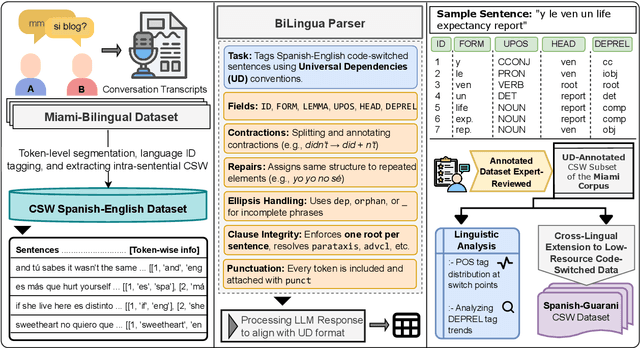
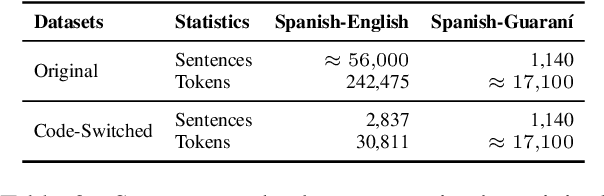
Code-switching presents a complex challenge for syntactic analysis, especially in low-resource language settings where annotated data is scarce. While recent work has explored the use of large language models (LLMs) for sequence-level tagging, few approaches systematically investigate how well these models capture syntactic structure in code-switched contexts. Moreover, existing parsers trained on monolingual treebanks often fail to generalize to multilingual and mixed-language input. To address this gap, we introduce the BiLingua Parser, an LLM-based annotation pipeline designed to produce Universal Dependencies (UD) annotations for code-switched text. First, we develop a prompt-based framework for Spanish-English and Spanish-Guaran\'i data, combining few-shot LLM prompting with expert review. Second, we release two annotated datasets, including the first Spanish-Guaran\'i UD-parsed corpus. Third, we conduct a detailed syntactic analysis of switch points across language pairs and communicative contexts. Experimental results show that BiLingua Parser achieves up to 95.29% LAS after expert revision, significantly outperforming prior baselines and multilingual parsers. These results show that LLMs, when carefully guided, can serve as practical tools for bootstrapping syntactic resources in under-resourced, code-switched environments. Data and source code are available at https://github.com/N3mika/ParsingProject
Step-by-Step Reasoning to Solve Grid Puzzles: Where do LLMs Falter?
Jul 20, 2024



Solving grid puzzles involves a significant amount of logical reasoning. Hence, it is a good domain to evaluate the reasoning capability of a model which can then guide us to improve the reasoning ability of models. However, most existing works evaluate only the final predicted answer of a puzzle, without delving into an in-depth analysis of the LLMs' reasoning chains (such as where they falter) or providing any finer metrics to evaluate them. Since LLMs may rely on simple heuristics or artifacts to predict the final answer, it is crucial to evaluate the generated reasoning chain beyond overall correctness measures, for accurately evaluating the reasoning abilities of LLMs. To this end, we first develop GridPuzzle, an evaluation dataset comprising 274 grid-based puzzles with different complexities. Second, we propose a new error taxonomy derived from manual analysis of reasoning chains from LLMs including GPT-4, Claude-3, Gemini, Mistral, and Llama-2. Then, we develop an LLM-based framework for large-scale subjective evaluation (i.e., identifying errors) and an objective metric, PuzzleEval, to evaluate the correctness of reasoning chains. Evaluating reasoning chains from LLMs leads to several interesting findings. We further show that existing prompting methods used for enhancing models' reasoning abilities do not improve performance on GridPuzzle. This highlights the importance of understanding fine-grained errors and presents a challenge for future research to enhance LLMs' puzzle-solving abilities by developing methods that address these errors. Data and source code are available at https://github.com/Mihir3009/GridPuzzle.
Chaos with Keywords: Exposing Large Language Models Sycophancy to Misleading Keywords and Evaluating Defense Strategies
Jun 06, 2024This study explores the sycophantic tendencies of Large Language Models (LLMs), where these models tend to provide answers that match what users want to hear, even if they are not entirely correct. The motivation behind this exploration stems from the common behavior observed in individuals searching the internet for facts with partial or misleading knowledge. Similar to using web search engines, users may recall fragments of misleading keywords and submit them to an LLM, hoping for a comprehensive response. Our empirical analysis of several LLMs shows the potential danger of these models amplifying misinformation when presented with misleading keywords. Additionally, we thoroughly assess four existing hallucination mitigation strategies to reduce LLMs sycophantic behavior. Our experiments demonstrate the effectiveness of these strategies for generating factually correct statements. Furthermore, our analyses delve into knowledge-probing experiments on factual keywords and different categories of sycophancy mitigation.