 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkTuning: Instilling Cognitive Reflections without Distillation
Aug 11, 2025
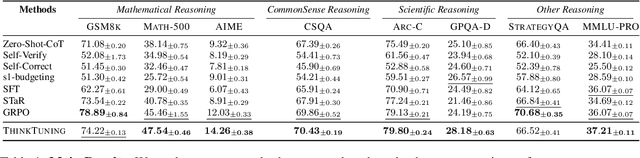
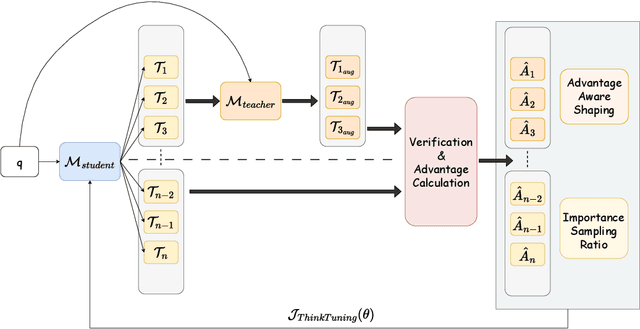
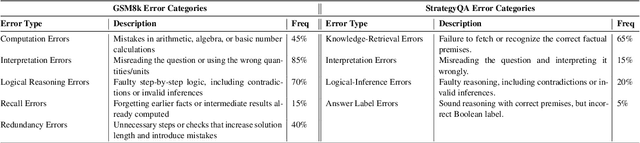
Recent advances in test-time scaling have led to the emergence of thinking LLMs that exhibit self-reflective behaviors and multi-step reasoning. While RL drives this self-improvement paradigm, a recent study (Gandhi et al., 2025) shows that RL alone does not truly instill these new reasoning abilities - it merely draws out behaviors already present in the base models. This raises a question: How can we train the models that don't exhibit such thinking behavior to develop it in the first place? To this end, we propose ThinkTuning, a GRPO-based interactive training approach where we augment the rollouts of a student model with the guidance from a teacher model. A simple idea from classroom practice inspires our method: a teacher poses a problem, lets the student try an answer, then gives corrective feedback -- enough to point the mind in the right direction and then show the solution. Each piece of feedback reshapes the student's thoughts, leading them to arrive at the correct solution. Similarly, we find that this type of implicit supervision through feedback from a teacher model of the same size improves the reasoning capabilities of the student model. In particular, on average, our method shows a 3.85% improvement over zero-shot baselines across benchmarks, and on MATH-500, AIME and GPQA-Diamond it shows 2.08%, 2.23% and 3.99% improvements over the vanilla-GRPO baseline. Source code is available at https://github.com/3rdAT/ThinkTuning.
UnSeenTimeQA: Time-Sensitive Question-Answering Beyond LLMs' Memorization
Jul 03, 2024



This paper introduces UnSeenTimeQA, a novel time-sensitive question-answering (TSQA) benchmark that diverges from traditional TSQA benchmarks by avoiding factual and web-searchable queries. We present a series of time-sensitive event scenarios decoupled from real-world factual information. It requires large language models (LLMs) to engage in genuine temporal reasoning, disassociating from the knowledge acquired during the pre-training phase. Our evaluation of six open-source LLMs (ranging from 2B to 70B in size) and three closed-source LLMs reveal that the questions from the UnSeenTimeQA present substantial challenges. This indicates the models' difficulties in handling complex temporal reasoning scenarios. Additionally, we present several analyses shedding light on the models' performance in answering time-sensitive questions.
Chaos with Keywords: Exposing Large Language Models Sycophancy to Misleading Keywords and Evaluating Defense Strategies
Jun 06, 2024This study explores the sycophantic tendencies of Large Language Models (LLMs), where these models tend to provide answers that match what users want to hear, even if they are not entirely correct. The motivation behind this exploration stems from the common behavior observed in individuals searching the internet for facts with partial or misleading knowledge. Similar to using web search engines, users may recall fragments of misleading keywords and submit them to an LLM, hoping for a comprehensive response. Our empirical analysis of several LLMs shows the potential danger of these models amplifying misinformation when presented with misleading keywords. Additionally, we thoroughly assess four existing hallucination mitigation strategies to reduce LLMs sycophantic behavior. Our experiments demonstrate the effectiveness of these strategies for generating factually correct statements. Furthermore, our analyses delve into knowledge-probing experiments on factual keywords and different categories of sycophancy mitigation.
Asking and Answering Questions to Extract Event-Argument Structures
Apr 25, 2024This paper presents a question-answering approach to extract document-level event-argument structures. We automatically ask and answer questions for each argument type an event may have. Questions are generated using manually defined templates and generative transformers. Template-based questions are generated using predefined role-specific wh-words and event triggers from the context document. Transformer-based questions are generated using large language models trained to formulate questions based on a passage and the expected answer. Additionally, we develop novel data augmentation strategies specialized in inter-sentential event-argument relations. We use a simple span-swapping technique, coreference resolution, and large language models to augment the training instances. Our approach enables transfer learning without any corpora-specific modifications and yields competitive results with the RAMS dataset. It outperforms previous work, and it is especially beneficial to extract arguments that appear in different sentences than the event trigger. We also present detailed quantitative and qualitative analyses shedding light on the most common errors made by our best model.
Generating Uncontextualized and Contextualized Questions for Document-Level Event Argument Extraction
Apr 07, 2024This paper presents multiple question generation strategies for document-level event argument extraction. These strategies do not require human involvement and result in uncontextualized questions as well as contextualized questions grounded on the event and document of interest. Experimental results show that combining uncontextualized and contextualized questions is beneficial, especially when event triggers and arguments appear in different sentences. Our approach does not have corpus-specific components, in particular, the question generation strategies transfer across corpora. We also present a qualitative analysis of the most common errors made by our best model.
Interpreting Indirect Answers to Yes-No Questions in Multiple Languages
Oct 20, 2023
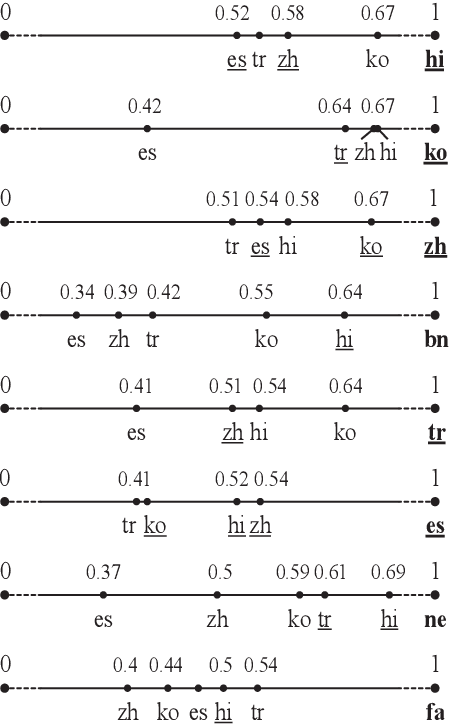

Yes-no questions expect a yes or no for an answer, but people often skip polar keywords. Instead, they answer with long explanations that must be interpreted. In this paper, we focus on this challenging problem and release new benchmarks in eight languages. We present a distant supervision approach to collect training data. We also demonstrate that direct answers (i.e., with polar keywords) are useful to train models to interpret indirect answers (i.e., without polar keywords). Experimental results demonstrate that monolingual fine-tuning is beneficial if training data can be obtained via distant supervision for the language of interest (5 languages). Additionally, we show that cross-lingual fine-tuning is always beneficial (8 languages).