 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-ICE: An Inner Interpretable Framework for Image Classification via Bi-directional Interactions between Concept and Input Embeddings
Nov 26, 2024
Inner interpretability is a promising field focused on uncovering the internal mechanisms of AI systems and developing scalable, automated methods to understand these systems at a mechanistic level. While significant research has explored top-down approaches starting from high-level problems or algorithmic hypotheses and bottom-up approaches building higher-level abstractions from low-level or circuit-level descriptions, most efforts have concentrated on analyzing large language models. Moreover, limited attention has been given to applying inner interpretability to large-scale image tasks, primarily focusing on architectural and functional levels to visualize learned concepts. In this paper, we first present a conceptual framework that supports inner interpretability and multilevel analysis for large-scale image classification tasks. We introduce the Bi-directional Interaction between Concept and Input Embeddings (Bi-ICE) module, which facilitates interpretability across the computational, algorithmic, and implementation levels. This module enhances transparency by generating predictions based on human-understandable concepts, quantifying their contributions, and localizing them within the inputs. Finally, we showcase enhanced transparency in image classification, measuring concept contributions and pinpointing their locations within the inputs. Our approach highlights algorithmic interpretability by demonstrating the process of concept learning and its convergence.
Learning Decomposable and Debiased Representations via Attribute-Centric Information Bottlenecks
Mar 21, 2024


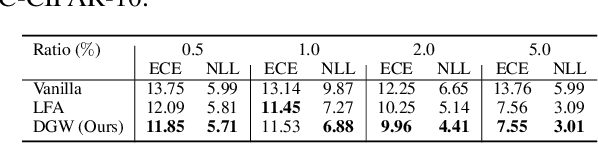
Biased attributes, spuriously correlated with target labels in a dataset, can problematically lead to neural networks that learn improper shortcuts for classifications and limit their capabilities for out-of-distribution (OOD) generalization. Although many debiasing approaches have been proposed to ensure correct predictions from biased datasets, few studies have considered learning latent embedding consisting of intrinsic and biased attributes that contribute to improved performance and explain how the model pays attention to attributes. In this paper, we propose a novel debiasing framework, Debiasing Global Workspace, introducing attention-based information bottlenecks for learning compositional representations of attributes without defining specific bias types. Based on our observation that learning shape-centric representation helps robust performance on OOD datasets, we adopt those abilities to learn robust and generalizable representations of decomposable latent embeddings corresponding to intrinsic and biasing attributes. We conduct comprehensive evaluations on biased datasets, along with both quantitative and qualitative analyses, to showcase our approach's efficacy in attribute-centric representation learning and its ability to differentiate between intrinsic and bias-related features.
Interpreting Answers to Yes-No Questions in User-Generated Content
Oct 24, 2023Interpreting answers to yes-no questions in social media is difficult. Yes and no keywords are uncommon, and the few answers that include them are rarely to be interpreted what the keywords suggest. In this paper, we present a new corpus of 4,442 yes-no question-answer pairs from Twitter. We discuss linguistic characteristics of answers whose interpretation is yes or no, as well as answers whose interpretation is unknown. We show that large language models are far from solving this problem, even after fine-tuning and blending other corpora for the same problem but outside social media.
Interpreting Indirect Answers to Yes-No Questions in Multiple Languages
Oct 20, 2023
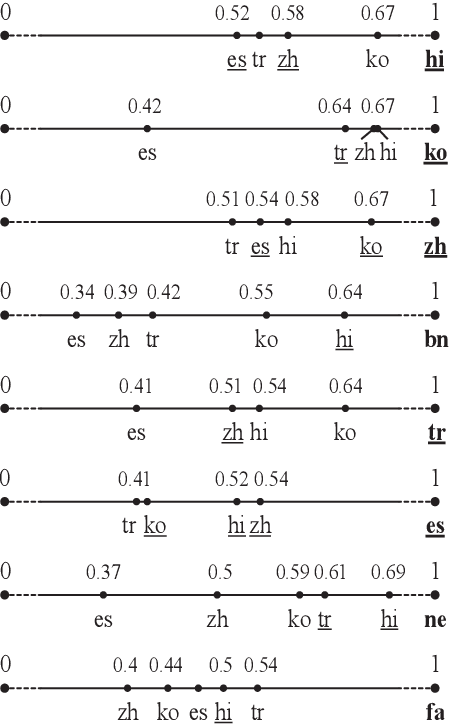
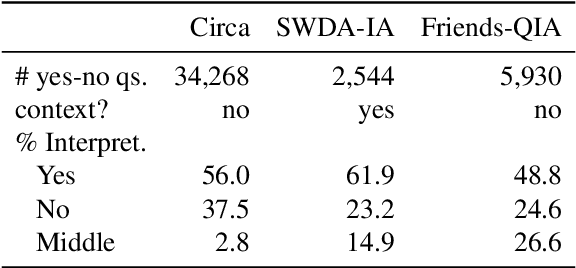

Yes-no questions expect a yes or no for an answer, but people often skip polar keywords. Instead, they answer with long explanations that must be interpreted. In this paper, we focus on this challenging problem and release new benchmarks in eight languages. We present a distant supervision approach to collect training data. We also demonstrate that direct answers (i.e., with polar keywords) are useful to train models to interpret indirect answers (i.e., without polar keywords). Experimental results demonstrate that monolingual fine-tuning is beneficial if training data can be obtained via distant supervision for the language of interest (5 languages). Additionally, we show that cross-lingual fine-tuning is always beneficial (8 languages).
Adversarial Demonstration Attacks on Large Language Models
May 24, 2023

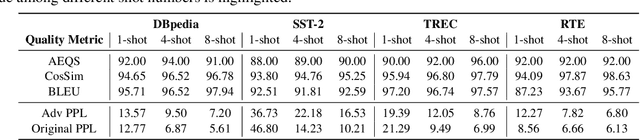

With the emergence of more powerful large language models (LLMs), such as ChatGPT and GPT-4, in-context learning (ICL) has gained significant prominence in leveraging these models for specific tasks by utilizing data-label pairs as precondition prompts. While incorporating demonstrations can greatly enhance the performance of LLMs across various tasks, it may introduce a new security concern: attackers can manipulate only the demonstrations without changing the input to perform an attack. In this paper, we investigate the security concern of ICL from an adversarial perspective, focusing on the impact of demonstrations. We propose an ICL attack based on TextAttack, which aims to only manipulate the demonstration without changing the input to mislead the models. Our results demonstrate that as the number of demonstrations increases, the robustness of in-context learning would decreases. Furthermore, we also observe that adversarially attacked demonstrations exhibit transferability to diverse input examples. These findings emphasize the critical security risks associated with ICL and underscore the necessity for extensive research on the robustness of ICL, particularly given its increasing significance in the advancement of LLMs.