 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnt-inspired Walling Strategies for Scalable Swarm Separation: Reinforcement Learning Approaches Based on Finite State Machines
Oct 26, 2025In natural systems, emergent structures often arise to balance competing demands. Army ants, for example, form temporary "walls" that prevent interference between foraging trails. Inspired by this behavior, we developed two decentralized controllers for heterogeneous robotic swarms to maintain spatial separation while executing concurrent tasks. The first is a finite-state machine (FSM)-based controller that uses encounter-triggered transitions to create rigid, stable walls. The second integrates FSM states with a Deep Q-Network (DQN), dynamically optimizing separation through emergent "demilitarized zones." In simulation, both controllers reduce mixing between subgroups, with the DQN-enhanced controller improving adaptability and reducing mixing by 40-50% while achieving faster convergence.
Bi-ICE: An Inner Interpretable Framework for Image Classification via Bi-directional Interactions between Concept and Input Embeddings
Nov 26, 2024
Inner interpretability is a promising field focused on uncovering the internal mechanisms of AI systems and developing scalable, automated methods to understand these systems at a mechanistic level. While significant research has explored top-down approaches starting from high-level problems or algorithmic hypotheses and bottom-up approaches building higher-level abstractions from low-level or circuit-level descriptions, most efforts have concentrated on analyzing large language models. Moreover, limited attention has been given to applying inner interpretability to large-scale image tasks, primarily focusing on architectural and functional levels to visualize learned concepts. In this paper, we first present a conceptual framework that supports inner interpretability and multilevel analysis for large-scale image classification tasks. We introduce the Bi-directional Interaction between Concept and Input Embeddings (Bi-ICE) module, which facilitates interpretability across the computational, algorithmic, and implementation levels. This module enhances transparency by generating predictions based on human-understandable concepts, quantifying their contributions, and localizing them within the inputs. Finally, we showcase enhanced transparency in image classification, measuring concept contributions and pinpointing their locations within the inputs. Our approach highlights algorithmic interpretability by demonstrating the process of concept learning and its convergence.
Learning Decomposable and Debiased Representations via Attribute-Centric Information Bottlenecks
Mar 21, 2024


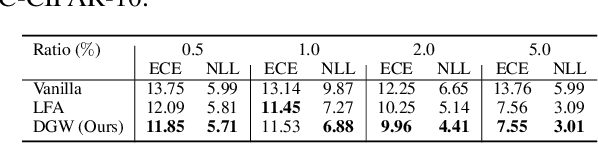
Biased attributes, spuriously correlated with target labels in a dataset, can problematically lead to neural networks that learn improper shortcuts for classifications and limit their capabilities for out-of-distribution (OOD) generalization. Although many debiasing approaches have been proposed to ensure correct predictions from biased datasets, few studies have considered learning latent embedding consisting of intrinsic and biased attributes that contribute to improved performance and explain how the model pays attention to attributes. In this paper, we propose a novel debiasing framework, Debiasing Global Workspace, introducing attention-based information bottlenecks for learning compositional representations of attributes without defining specific bias types. Based on our observation that learning shape-centric representation helps robust performance on OOD datasets, we adopt those abilities to learn robust and generalizable representations of decomposable latent embeddings corresponding to intrinsic and biasing attributes. We conduct comprehensive evaluations on biased datasets, along with both quantitative and qualitative analyses, to showcase our approach's efficacy in attribute-centric representation learning and its ability to differentiate between intrinsic and bias-related features.
Concept-Centric Transformers: Concept Transformers with Object-Centric Concept Learning for Interpretability
May 25, 2023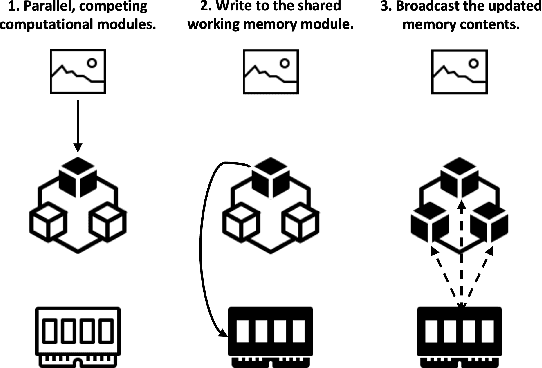
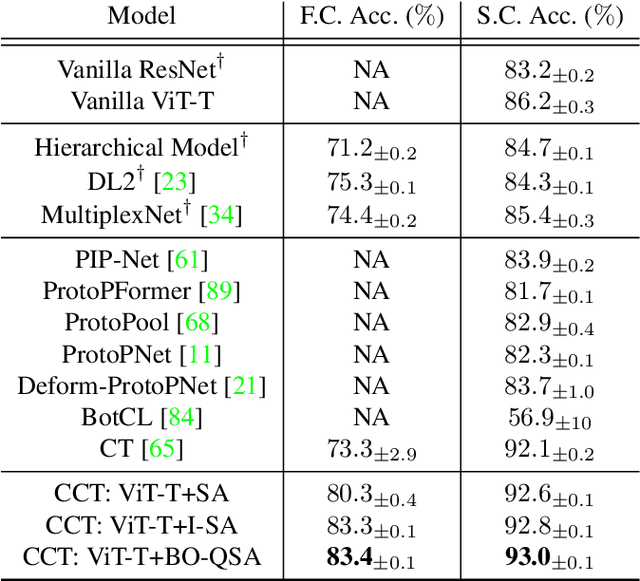
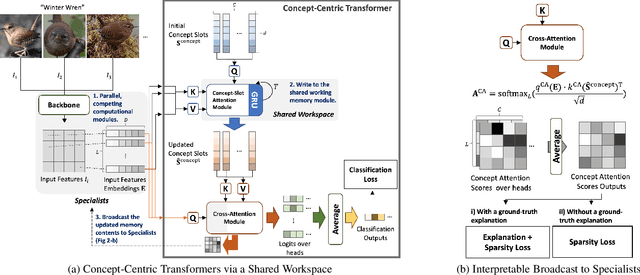

Attention mechanisms have greatly improved the performance of deep-learning models on visual, NLP, and multimodal tasks while also providing tools to aid in the model's interpretability. In particular, attention scores over input regions or concrete image features can be used to measure how much the attended elements contribute to the model inference. The recently proposed Concept Transformer (CT) generalizes the Transformer attention mechanism from such low-level input features to more abstract, intermediate-level latent concepts that better allow human analysts to more directly assess an explanation for the reasoning of the model about any particular output classification. However, the concept learning employed by CT implicitly assumes that across every image in a class, each image patch makes the same contribution to concepts that characterize membership in that class. Instead of using the CT's image-patch-centric concepts, object-centric concepts could lead to better classification performance as well as better explainability. Thus, we propose Concept-Centric Transformers (CCT), a new family of concept transformers that provides more robust explanations and performance by integrating a novel concept-extraction module based on object-centric learning. We test our proposed CCT against the CT and several other existing approaches on classification problems for MNIST (odd/even), CIFAR100 (super-classes), and CUB-200-2011 (bird species). Our experiments demonstrate that CCT not only achieves significantly better classification accuracy than all selected benchmark classifiers across all three of our test problems, but it generates more consistent concept-based explanations of classification output when compared to CT.
CHARTOPOLIS: A Small-Scale Labor-art-ory for Research and Reflection on Autonomous Vehicles, Human-Robot Interaction, and Sociotechnical Imaginaries
Oct 01, 2022
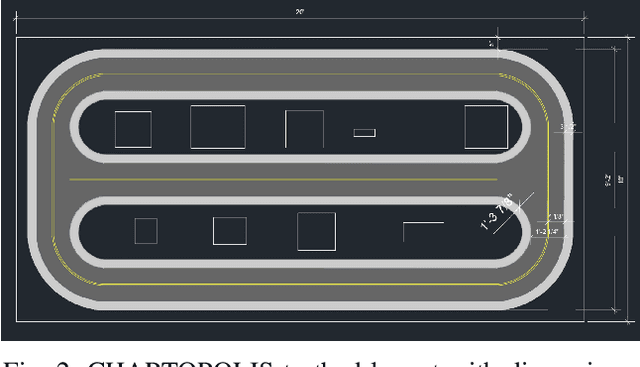
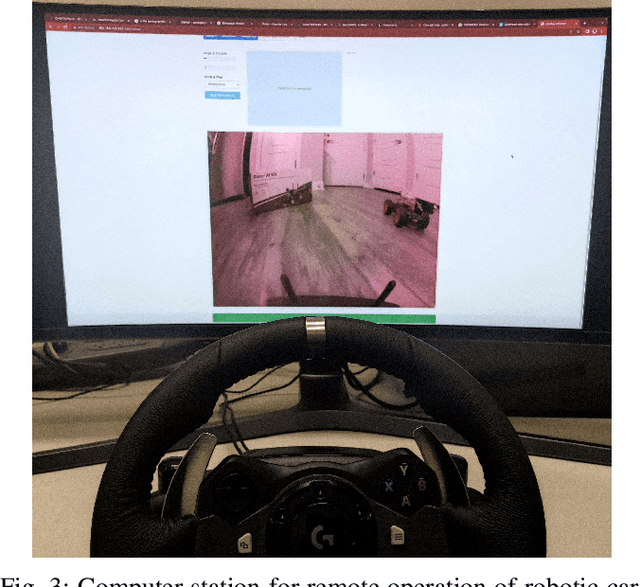

CHARTOPOLIS is a multi-faceted sociotechnical testbed meant to aid in building connections among engineers, psychologists, anthropologists, ethicists, and artists. Superficially, it is an urban autonomous-vehicle testbed that includes both a physical environment for small-scale robotic vehicles as well as a high-fidelity virtual replica that provides extra flexibility by way of computer simulation. However, both environments have been developed to allow for participatory simulation with human drivers as well. Each physical vehicle can be remotely operated by human drivers that have a driver-seat point of view that immerses them within the small-scale testbed, and those same drivers can also pilot high-fidelity models of those vehicles in a virtual replica of the environment. Juxtaposing human driving performance across these two contexts will help identify to what extent human driving behaviors are sensorimotor responses or involve psychological engagement with a system that has physical, not virtual, side effects and consequences. Furthermore, through collaboration with artists, we have designed the physical testbed to make tangible the reality that technological advancement causes the history of a city to fork into multiple, parallel timelines that take place within populations whose increasing isolation effectively creates multiple independent cities in one. Ultimately, CHARTOPOLIS is meant to challenge engineers to take a more holistic view when designing autonomous systems, while also enabling them to gather novel data that will assist them in making these systems more trustworthy.
Learning to modulate random weights can induce task-specific contexts for economical meta and continual learning
Apr 08, 2022
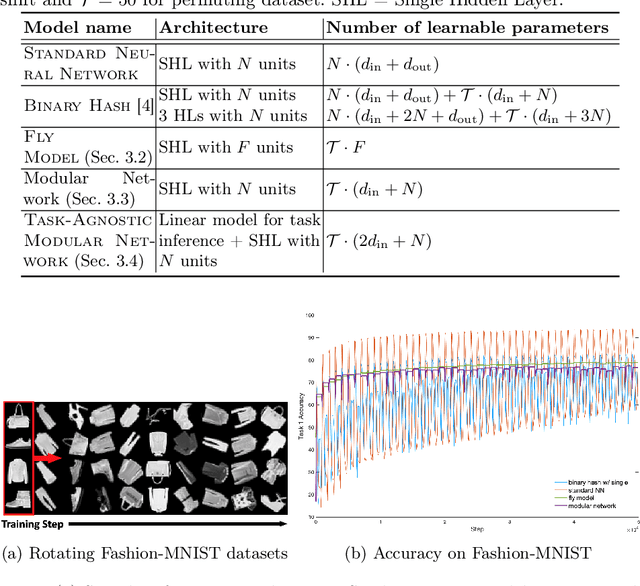
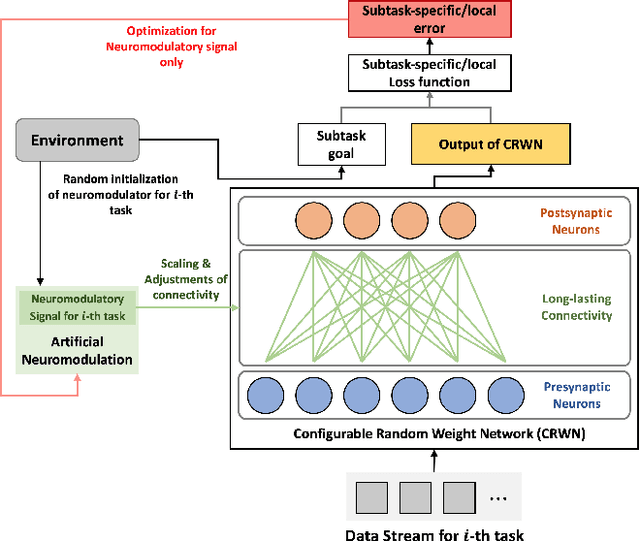
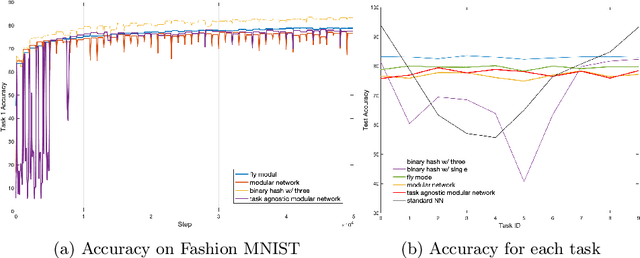
Neural networks are vulnerable to catastrophic forgetting when data distributions are non-stationary during continual online learning; learning of a later task often leads to forgetting of an earlier task. One solution approach is model-agnostic continual meta-learning, whereby both task-specific and meta parameters are trained. Here, we depart from this view and introduce a novel neural-network architecture inspired by neuromodulation in biological nervous systems. Neuromodulation is the biological mechanism that dynamically controls and fine-tunes synaptic dynamics to complement the behavioral context in real-time, which has received limited attention in machine learning. We introduce a single-hidden-layer network that learns only a relatively small context vector per task (task-specific parameters) that neuromodulates unchanging, randomized weights (meta parameters) that transform the input. We show that when task boundaries are available, this approach can eliminate catastrophic forgetting entirely while also drastically reducing the number of learnable parameters relative to other context-vector-based approaches. Furthermore, by combining this model with a simple meta-learning approach for inferring task identity, we demonstrate that the model can be generalized into a framework to perform continual learning without knowledge of task boundaries. Finally, we showcase the framework in a supervised continual online learning scenario and discuss the implications of the proposed formalism.
Representing Prior Knowledge Using Randomly, Weighted Feature Networks for Visual Relationship Detection
Nov 20, 2021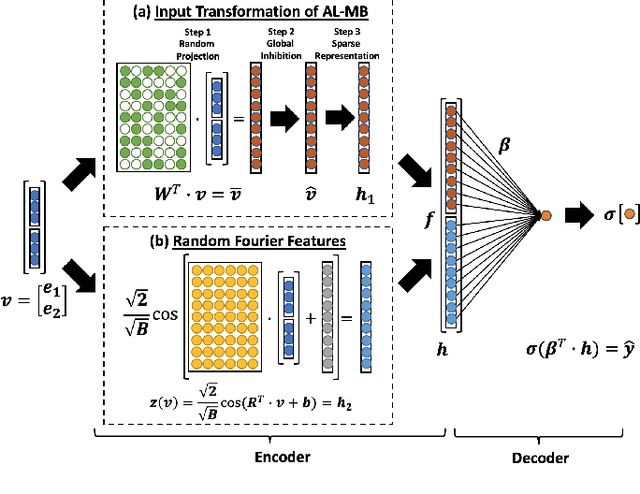
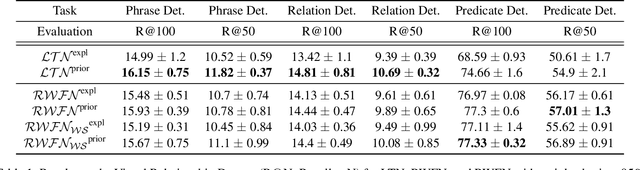
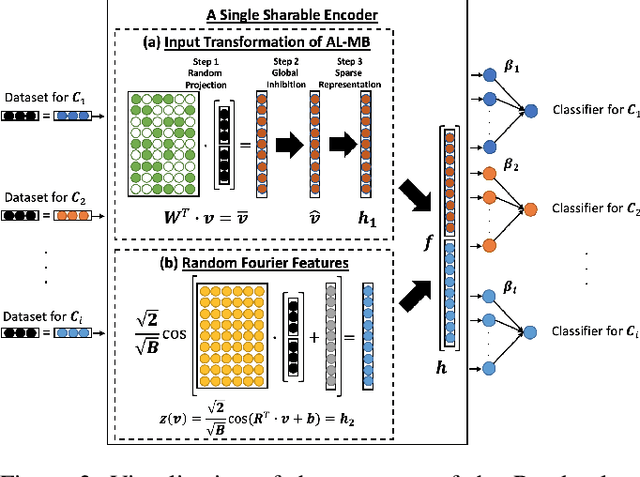
The single-hidden-layer Randomly Weighted Feature Network (RWFN) introduced by Hong and Pavlic (2021) was developed as an alternative to neural tensor network approaches for relational learning tasks. Its relatively small footprint combined with the use of two randomized input projections -- an insect-brain-inspired input representation and random Fourier features -- allow it to achieve rich expressiveness for relational learning with relatively low training cost. In particular, when Hong and Pavlic compared RWFN to Logic Tensor Networks (LTNs) for Semantic Image Interpretation (SII) tasks to extract structured semantic descriptions from images, they showed that the RWFN integration of the two hidden, randomized representations better captures relationships among inputs with a faster training process even though it uses far fewer learnable parameters. In this paper, we use RWFNs to perform Visual Relationship Detection (VRD) tasks, which are more challenging SII tasks. A zero-shot learning approach is used with RWFN that can exploit similarities with other seen relationships and background knowledge -- expressed with logical constraints between subjects, relations, and objects -- to achieve the ability to predict triples that do not appear in the training set. The experiments on the Visual Relationship Dataset to compare the performance between RWFNs and LTNs, one of the leading Statistical Relational Learning frameworks, show that RWFNs outperform LTNs for the predicate-detection task while using fewer number of adaptable parameters (1:56 ratio). Furthermore, background knowledge represented by RWFNs can be used to alleviate the incompleteness of training sets even though the space complexity of RWFNs is much smaller than LTNs (1:27 ratio).
An Insect-Inspired Randomly, Weighted Neural Network with Random Fourier Features For Neuro-Symbolic Relational Learning
Sep 11, 2021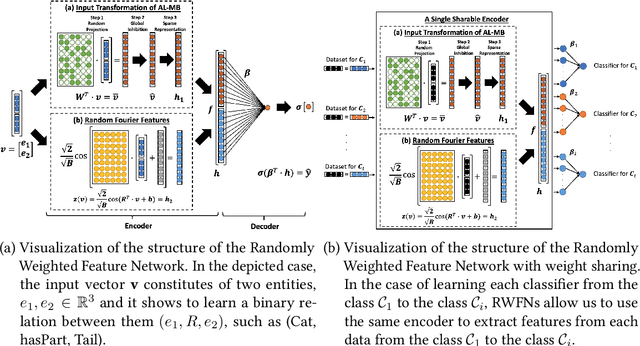
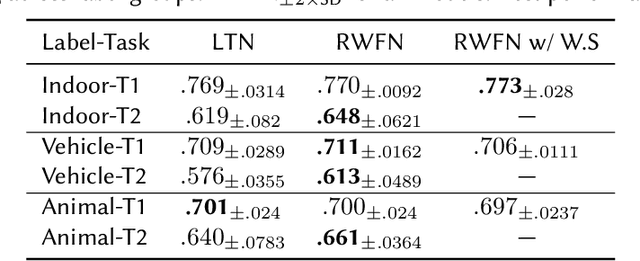
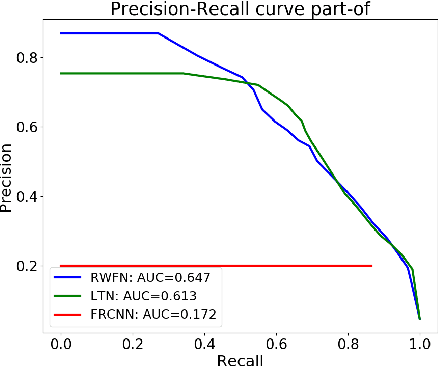
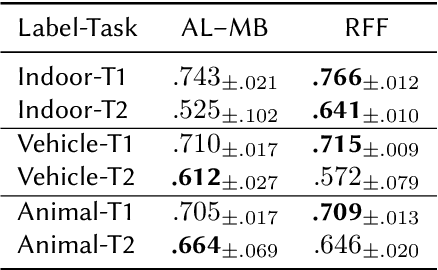
Insects, such as fruit flies and honey bees, can solve simple associative learning tasks and learn abstract concepts such as "sameness" and "difference", which is viewed as a higher-order cognitive function and typically thought to depend on top-down neocortical processing. Empirical research with fruit flies strongly supports that a randomized representational architecture is used in olfactory processing in insect brains. Based on these results, we propose a Randomly Weighted Feature Network (RWFN) that incorporates randomly drawn, untrained weights in an encoder that uses an adapted linear model as a decoder. The randomized projections between input neurons and higher-order processing centers in the input brain is mimicked in RWFN by a single-hidden-layer neural network that specially structures latent representations in the hidden layer using random Fourier features that better represent complex relationships between inputs using kernel approximation. Because of this special representation, RWFNs can effectively learn the degree of relationship among inputs by training only a linear decoder model. We compare the performance of RWFNs to LTNs for Semantic Image Interpretation (SII) tasks that have been used as a representative example of how LTNs utilize reasoning over first-order logic to surpass the performance of solely data-driven methods. We demonstrate that compared to LTNs, RWFNs can achieve better or similar performance for both object classification and detection of the part-of relations between objects in SII tasks while using much far fewer learnable parameters (1:62 ratio) and a faster learning process (1:2 ratio of running speed). Furthermore, we show that because the randomized weights do not depend on the data, several decoders can share a single randomized encoder, giving RWFNs a unique economy of spatial scale for simultaneous classification tasks.
Beyond Tracking: Using Deep Learning to Discover Novel Interactions in Biological Swarms
Aug 20, 2021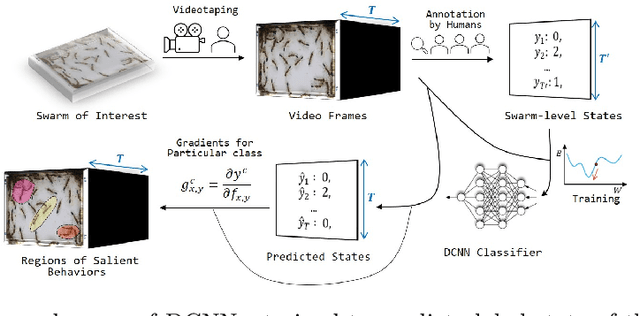



Most deep-learning frameworks for understanding biological swarms are designed to fit perceptive models of group behavior to individual-level data (e.g., spatial coordinates of identified features of individuals) that have been separately gathered from video observations. Despite considerable advances in automated tracking, these methods are still very expensive or unreliable when tracking large numbers of animals simultaneously. Moreover, this approach assumes that the human-chosen features include sufficient features to explain important patterns in collective behavior. To address these issues, we propose training deep network models to predict system-level states directly from generic graphical features from the entire view, which can be relatively inexpensive to gather in a completely automated fashion. Because the resulting predictive models are not based on human-understood predictors, we use explanatory modules (e.g., Grad-CAM) that combine information hidden in the latent variables of the deep-network model with the video data itself to communicate to a human observer which aspects of observed individual behaviors are most informative in predicting group behavior. This represents an example of augmented intelligence in behavioral ecology -- knowledge co-creation in a human-AI team. As proof of concept, we utilize a 20-day video recording of a colony of over 50 Harpegnathos saltator ants to showcase that, without any individual annotations provided, a trained model can generate an "importance map" across the video frames to highlight regions of important behaviors, such as dueling (which the AI has no a priori knowledge of), that play a role in the resolution of reproductive-hierarchy re-formation. Based on the empirical results, we also discuss the potential use and current challenges.
KCNet: An Insect-Inspired Single-Hidden-Layer Neural Network with Randomized Binary Weights for Prediction and Classification Tasks
Aug 17, 2021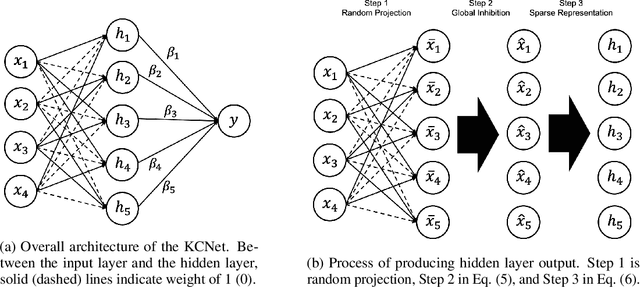
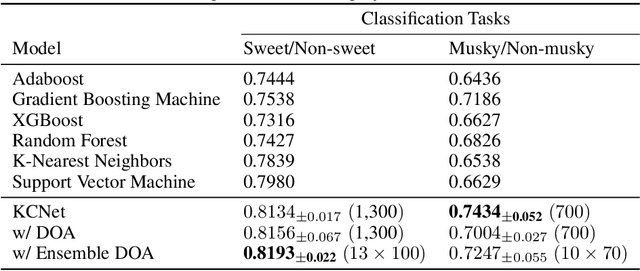
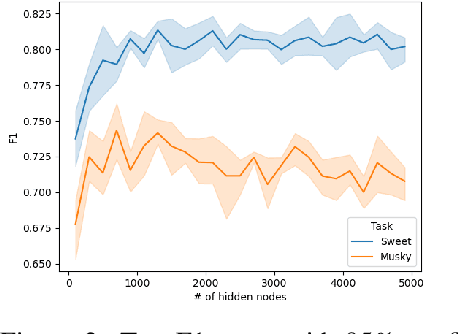
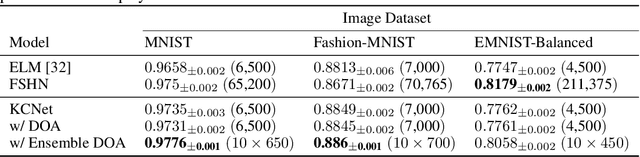
Fruit flies are established model systems for studying olfactory learning as they will readily learn to associate odors with both electric shock or sugar rewards. The mechanisms of the insect brain apparently responsible for odor learning form a relatively shallow neuronal architecture. Olfactory inputs are received by the antennal lobe (AL) of the brain, which produces an encoding of each odor mixture across ~50 sub-units known as glomeruli. Each of these glomeruli then project its component of this feature vector to several of ~2000 so-called Kenyon Cells (KCs) in a region of the brain known as the mushroom body (MB). Fly responses to odors are generated by small downstream neuropils that decode the higher-order representation from the MB. Research has shown that there is no recognizable pattern in the glomeruli--KC connections (and thus the particular higher-order representations); they are akin to fingerprints~-- even isogenic flies have different projections. Leveraging insights from this architecture, we propose KCNet, a single-hidden-layer neural network that contains sparse, randomized, binary weights between the input layer and the hidden layer and analytically learned weights between the hidden layer and the output layer. Furthermore, we also propose a dynamic optimization algorithm that enables the KCNet to increase performance beyond its structural limits by searching a more efficient set of inputs. For odorant-perception tasks that predict perceptual properties of an odorant, we show that KCNet outperforms existing data-driven approaches, such as XGBoost. For image-classification tasks, KCNet achieves reasonable performance on benchmark datasets (MNIST, Fashion-MNIST, and EMNIST) without any data-augmentation methods or convolutional layers and shows particularly fast running time. Thus, neural networks inspired by the insect brain can be both economical and perform well.