 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA-Cut: Crop-Aligned Cutout for Data Augmentation to Learn More Robust Under-Canopy Navigation
Jul 24, 2025State-of-the-art visual under-canopy navigation methods are designed with deep learning-based perception models to distinguish traversable space from crop rows. While these models have demonstrated successful performance, they require large amounts of training data to ensure reliability in real-world field deployment. However, data collection is costly, demanding significant human resources for in-field sampling and annotation. To address this challenge, various data augmentation techniques are commonly employed during model training, such as color jittering, Gaussian blur, and horizontal flip, to diversify training data and enhance model robustness. In this paper, we hypothesize that utilizing only these augmentation techniques may lead to suboptimal performance, particularly in complex under-canopy environments with frequent occlusions, debris, and non-uniform spacing of crops. Instead, we propose a novel augmentation method, so-called Crop-Aligned Cutout (CA-Cut) which masks random regions out in input images that are spatially distributed around crop rows on the sides to encourage trained models to capture high-level contextual features even when fine-grained information is obstructed. Our extensive experiments with a public cornfield dataset demonstrate that masking-based augmentations are effective for simulating occlusions and significantly improving robustness in semantic keypoint predictions for visual navigation. In particular, we show that biasing the mask distribution toward crop rows in CA-Cut is critical for enhancing both prediction accuracy and generalizability across diverse environments achieving up to a 36.9% reduction in prediction error. In addition, we conduct ablation studies to determine the number of masks, the size of each mask, and the spatial distribution of masks to maximize overall performance.
Towards Fully Automated Decision-Making Systems for Greenhouse Control: Challenges and Opportunities
Mar 27, 2025

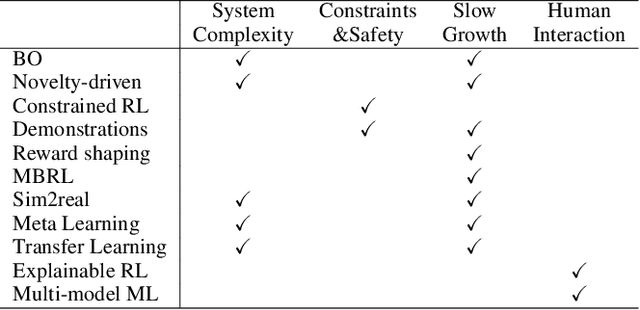

Machine learning has been successful in building control policies to drive a complex system to desired states in various applications (e.g. games, robotics, etc.). To be specific, a number of parameters of policy can be automatically optimized from the observations of environment to be able to generate a sequence of decisions leading to the best performance. In this survey paper, we particularly explore such policy-learning techniques for another unique, practical use-case scenario--farming, in which critical decisions (e.g., water supply, heating, etc.) must be made in a timely manner to minimize risks (e.g., damage to plants) while maximizing the revenue (e.g., healthy crops) in the end. We first provide a broad overview of latest studies on it to identify not only domain-specific challenges but opportunities with potential solutions, some of which are suggested as promising directions for future research. Also, we then introduce our successful approach to being ranked second among 46 teams at the ''3rd Autonomous Greenhouse Challenge'' to use this specific example to discuss the lessons learned about important considerations for design to create autonomous farm-management systems.
DAVIS-Ag: A Synthetic Plant Dataset for Developing Domain-Inspired Active Vision in Agricultural Robots
Mar 10, 2023



In agricultural environments, viewpoint planning can be a critical functionality for a robot with visual sensors to obtain informative observations of objects of interest (e.g., fruits) from complex structures of plant with random occlusions. Although recent studies on active vision have shown some potential for agricultural tasks, each model has been designed and validated on a unique environment that would not easily be replicated for benchmarking novel methods being developed later. In this paper, hence, we introduce a dataset for more extensive research on Domain-inspired Active VISion in Agriculture (DAVIS-Ag). To be specific, we utilized our open-source "AgML" framework and the 3D plant simulator of "Helios" to produce 502K RGB images from 30K dense spatial locations in 632 realistically synthesized orchards of strawberries, tomatoes, and grapes. In addition, useful labels are provided for each image, including (1) bounding boxes and (2) pixel-wise instance segmentations for all identifiable fruits, and also (3) pointers to other images that are reachable by an execution of action so as to simulate the active selection of viewpoint at each time step. Using DAVIS-Ag, we show the motivating examples in which performance of fruit detection for the same plant can significantly vary depending on the position and orientation of camera view primarily due to occlusions by other components such as leaves. Furthermore, we develop several baseline models to showcase the "usage" of data with one of agricultural active vision tasks--fruit search optimization--providing evaluation results against which future studies could benchmark their methodologies. For encouraging relevant research, our dataset is released online to be freely available at: https://github.com/ctyeong/DAVIS-Ag
Self-supervised Representation Learning for Reliable Robotic Monitoring of Fruit Anomalies
Sep 21, 2021



Data augmentation can be a simple yet powerful tool for autonomous robots to fully utilise available data for self-supervised identification of atypical scenes or objects. State-of-the-art augmentation methods arbitrarily embed structural peculiarity in focal objects on typical images so that classifying these artefacts can provide guidance for learning representations for the detection of anomalous visual inputs. In this paper, however, we argue that learning such structure-sensitive representations can be a suboptimal approach to some classes of anomaly (e.g., unhealthy fruits) which are better recognised by a different type of visual element such as "colour". We thus propose Channel Randomisation as a novel data augmentation method for restricting neural network models to learn encoding of "colour irregularity" whilst predicting channel-randomised images to ultimately build reliable fruit-monitoring robots identifying atypical fruit qualities. Our experiments show that (1) the colour-based alternative can better learn representations for consistently accurate identification of fruit anomalies in various fruit species, and (2) validation accuracy can be monitored for early stopping of training due to positive correlation between the colour-learning task and fruit anomaly detection. Moreover, the proposed approach is evaluated on a new anomaly dataset Riseholme-2021, consisting of 3:5K strawberry images collected from a mobile robot, which we share with the community to encourage active agri-robotics research.
Beyond Tracking: Using Deep Learning to Discover Novel Interactions in Biological Swarms
Aug 20, 2021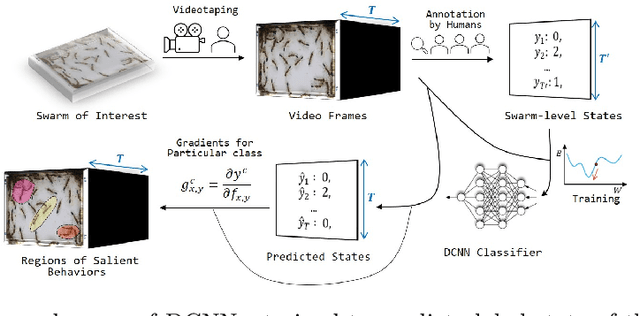



Most deep-learning frameworks for understanding biological swarms are designed to fit perceptive models of group behavior to individual-level data (e.g., spatial coordinates of identified features of individuals) that have been separately gathered from video observations. Despite considerable advances in automated tracking, these methods are still very expensive or unreliable when tracking large numbers of animals simultaneously. Moreover, this approach assumes that the human-chosen features include sufficient features to explain important patterns in collective behavior. To address these issues, we propose training deep network models to predict system-level states directly from generic graphical features from the entire view, which can be relatively inexpensive to gather in a completely automated fashion. Because the resulting predictive models are not based on human-understood predictors, we use explanatory modules (e.g., Grad-CAM) that combine information hidden in the latent variables of the deep-network model with the video data itself to communicate to a human observer which aspects of observed individual behaviors are most informative in predicting group behavior. This represents an example of augmented intelligence in behavioral ecology -- knowledge co-creation in a human-AI team. As proof of concept, we utilize a 20-day video recording of a colony of over 50 Harpegnathos saltator ants to showcase that, without any individual annotations provided, a trained model can generate an "importance map" across the video frames to highlight regions of important behaviors, such as dueling (which the AI has no a priori knowledge of), that play a role in the resolution of reproductive-hierarchy re-formation. Based on the empirical results, we also discuss the potential use and current challenges.
Adaptive Selection of Informative Path Planning Strategies via Reinforcement Learning
Aug 14, 2021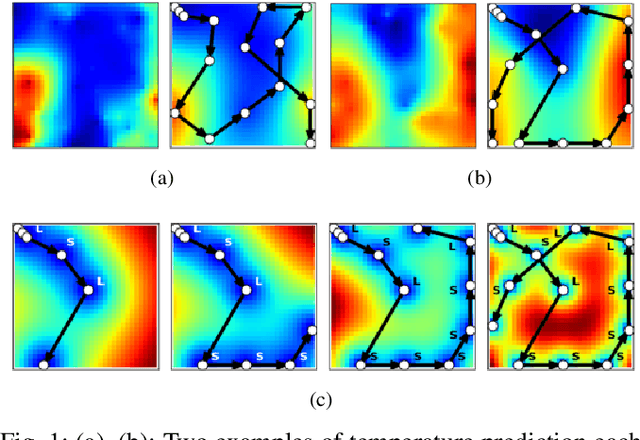
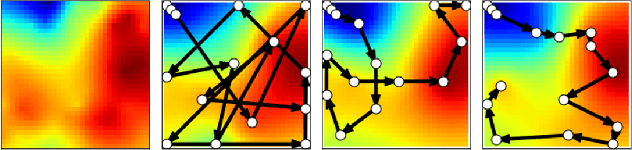
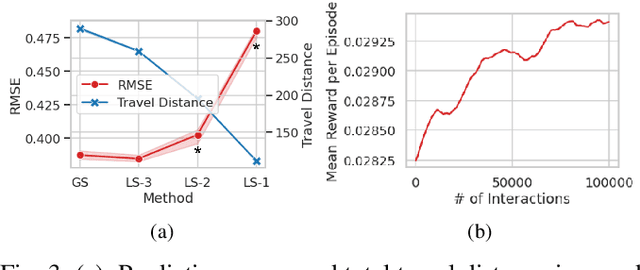
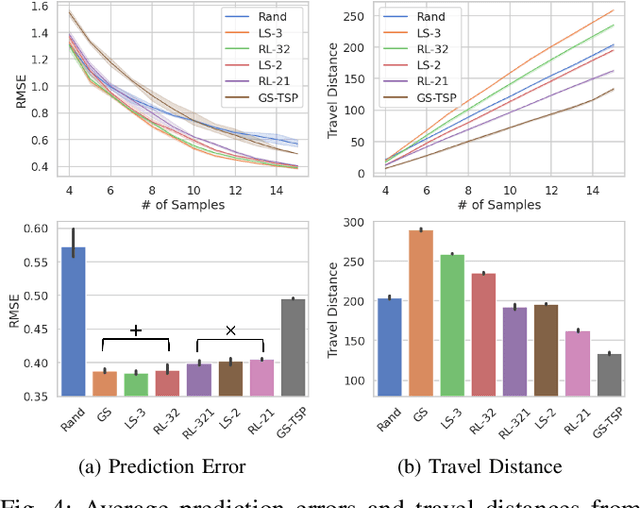
In our previous work, we designed a systematic policy to prioritize sampling locations to lead significant accuracy improvement in spatial interpolation by using the prediction uncertainty of Gaussian Process Regression (GPR) as "attraction force" to deployed robots in path planning. Although the integration with Traveling Salesman Problem (TSP) solvers was also shown to produce relatively short travel distance, we here hypothesise several factors that could decrease the overall prediction precision as well because sub-optimal locations may eventually be included in their paths. To address this issue, in this paper, we first explore "local planning" approaches adopting various spatial ranges within which next sampling locations are prioritized to investigate their effects on the prediction performance as well as incurred travel distance. Also, Reinforcement Learning (RL)-based high-level controllers are trained to adaptively produce blended plans from a particular set of local planners to inherit unique strengths from that selection depending on latest prediction states. Our experiments on use cases of temperature monitoring robots demonstrate that the dynamic mixtures of planners can not only generate sophisticated, informative plans that a single planner could not create alone but also ensure significantly reduced travel distances at no cost of prediction reliability without any assist of additional modules for shortest path calculation.
Identification of Abnormal States in Videos of Ants Undergoing Social Phase Change
Sep 18, 2020



Biology is both an important application area and a source of motivation for development of advanced machine learning techniques. Although much attention has been paid to large and complex data sets resulting from high-throughput sequencing, advances in high-quality video recording technology have begun to generate similarly rich data sets requiring sophisticated techniques from both computer vision and time-series analysis. Moreover, just as studying gene expression patterns in one organism can reveal general principles that apply to other organisms, the study of complex social interactions in an experimentally tractable model system, such as a laboratory ant colony, can provide general principles about the dynamics many other social groups. Here, we focus on one such example from the study of reproductive regulation in small laboratory colonies of $\sim$50 Harpgenathos ants. These ants can be artificially induced to begin a $\sim$20 day process of hierarchy reformation. Although the conclusion of this process is conspicuous to a human observer, it is still unclear which behaviors during the transients are contributing to the process. To address this issue, we explore the potential application of One-class Classification (OC) to the detection of abnormal states in ant colonies for which behavioral data is only available for the normal societal conditions during training. Specifically, we build upon the Deep Support Vector Data Description (DSVDD) and introduce the Inner-Outlier Generator (IO-GEN) that synthesizes fake "inner outlier" observations during training that are near the center of the DSVDD data description. We show that IO-GEN increases the reliability of the final OC classifier relative to other DSVDD baselines. This method can be used to screen video frames for which additional human observation is needed.