 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fully Automated Decision-Making Systems for Greenhouse Control: Challenges and Opportunities
Mar 27, 2025

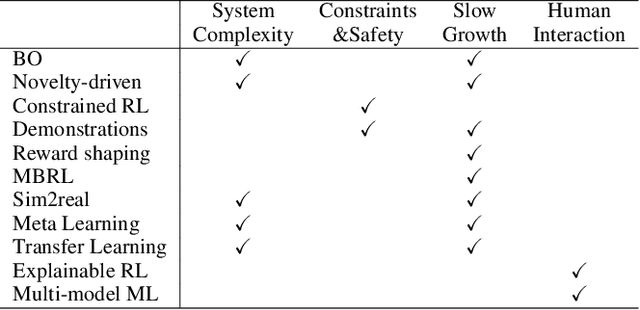

Machine learning has been successful in building control policies to drive a complex system to desired states in various applications (e.g. games, robotics, etc.). To be specific, a number of parameters of policy can be automatically optimized from the observations of environment to be able to generate a sequence of decisions leading to the best performance. In this survey paper, we particularly explore such policy-learning techniques for another unique, practical use-case scenario--farming, in which critical decisions (e.g., water supply, heating, etc.) must be made in a timely manner to minimize risks (e.g., damage to plants) while maximizing the revenue (e.g., healthy crops) in the end. We first provide a broad overview of latest studies on it to identify not only domain-specific challenges but opportunities with potential solutions, some of which are suggested as promising directions for future research. Also, we then introduce our successful approach to being ranked second among 46 teams at the ''3rd Autonomous Greenhouse Challenge'' to use this specific example to discuss the lessons learned about important considerations for design to create autonomous farm-management systems.
Look Before Leap: Look-Ahead Planning with Uncertainty in Reinforcement Learning
Mar 26, 2025


Model-based reinforcement learning (MBRL) has demonstrated superior sample efficiency compared to model-free reinforcement learning (MFRL). However, the presence of inaccurate models can introduce biases during policy learning, resulting in misleading trajectories. The challenge lies in obtaining accurate models due to limited diverse training data, particularly in regions with limited visits (uncertain regions). Existing approaches passively quantify uncertainty after sample generation, failing to actively collect uncertain samples that could enhance state coverage and improve model accuracy. Moreover, MBRL often faces difficulties in making accurate multi-step predictions, thereby impacting overall performance. To address these limitations, we propose a novel framework for uncertainty-aware policy optimization with model-based exploratory planning. In the model-based planning phase, we introduce an uncertainty-aware k-step lookahead planning approach to guide action selection at each step. This process involves a trade-off analysis between model uncertainty and value function approximation error, effectively enhancing policy performance. In the policy optimization phase, we leverage an uncertainty-driven exploratory policy to actively collect diverse training samples, resulting in improved model accuracy and overall performance of the RL agent. Our approach offers flexibility and applicability to tasks with varying state/action spaces and reward structures. We validate its effectiveness through experiments on challenging robotic manipulation tasks and Atari games, surpassing state-of-the-art methods with fewer interactions, thereby leading to significant performance improvements.
Adventurer: Exploration with BiGAN for Deep Reinforcement Learning
Mar 24, 2025Recent developments in deep reinforcement learning have been very successful in learning complex, previously intractable problems. Sample efficiency and local optimality, however, remain significant challenges. To address these challenges, novelty-driven exploration strategies have emerged and shown promising potential. Unfortunately, no single algorithm outperforms all others in all tasks and most of them struggle with tasks with high-dimensional and complex observations. In this work, we propose Adventurer, a novelty-driven exploration algorithm that is based on Bidirectional Generative Adversarial Networks (BiGAN), where BiGAN is trained to estimate state novelty. Intuitively, a generator that has been trained on the distribution of visited states should only be able to generate a state coming from the distribution of visited states. As a result, novel states using the generator to reconstruct input states from certain latent representations would lead to larger reconstruction errors. We show that BiGAN performs well in estimating state novelty for complex observations. This novelty estimation method can be combined with intrinsic-reward-based exploration. Our empirical results show that Adventurer produces competitive results on a range of popular benchmark tasks, including continuous robotic manipulation tasks (e.g. Mujoco robotics) and high-dimensional image-based tasks (e.g. Atari games).
CLARA: A Constrained Reinforcement Learning Based Resource Allocation Framework for Network Slicing
Nov 16, 2021As mobile networks proliferate, we are experiencing a strong diversification of services, which requires greater flexibility from the existing network. Network slicing is proposed as a promising solution for resource utilization in 5G and future networks to address this dire need. In network slicing, dynamic resource orchestration and network slice management are crucial for maximizing resource utilization. Unfortunately, this process is too complex for traditional approaches to be effective due to a lack of accurate models and dynamic hidden structures. We formulate the problem as a Constrained Markov Decision Process (CMDP) without knowing models and hidden structures. Additionally, we propose to solve the problem using CLARA, a Constrained reinforcement LeArning based Resource Allocation algorithm. In particular, we analyze cumulative and instantaneous constraints using adaptive interior-point policy optimization and projection layer, respectively. Evaluations show that CLARA clearly outperforms baselines in resource allocation with service demand guarantees.
IPO: Interior-point Policy Optimization under Constraints
Oct 21, 2019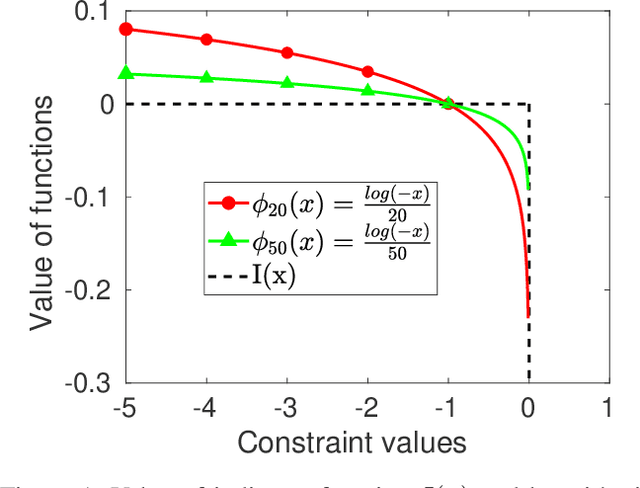
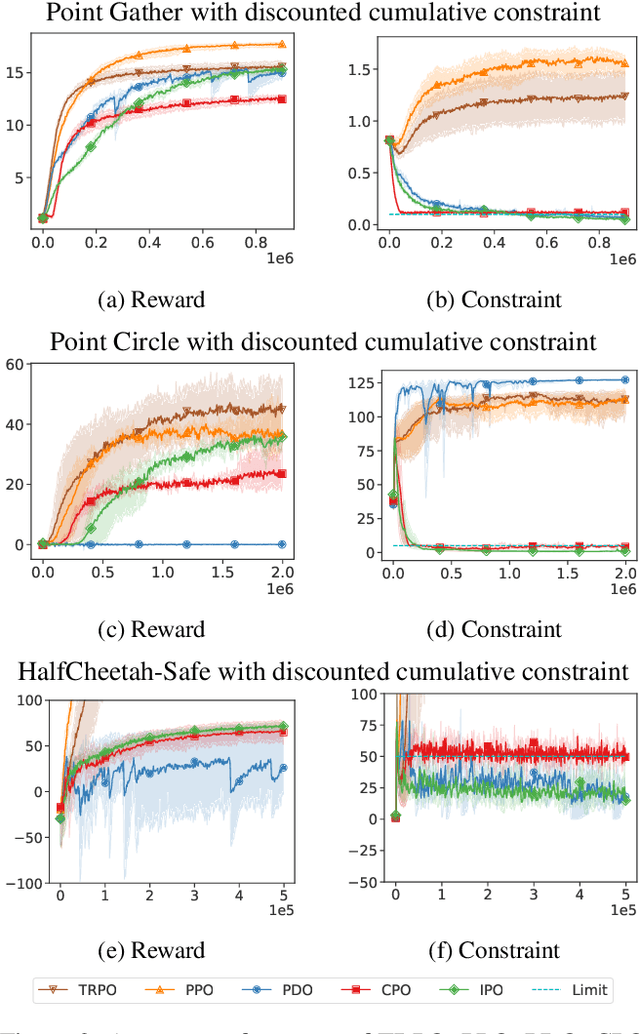
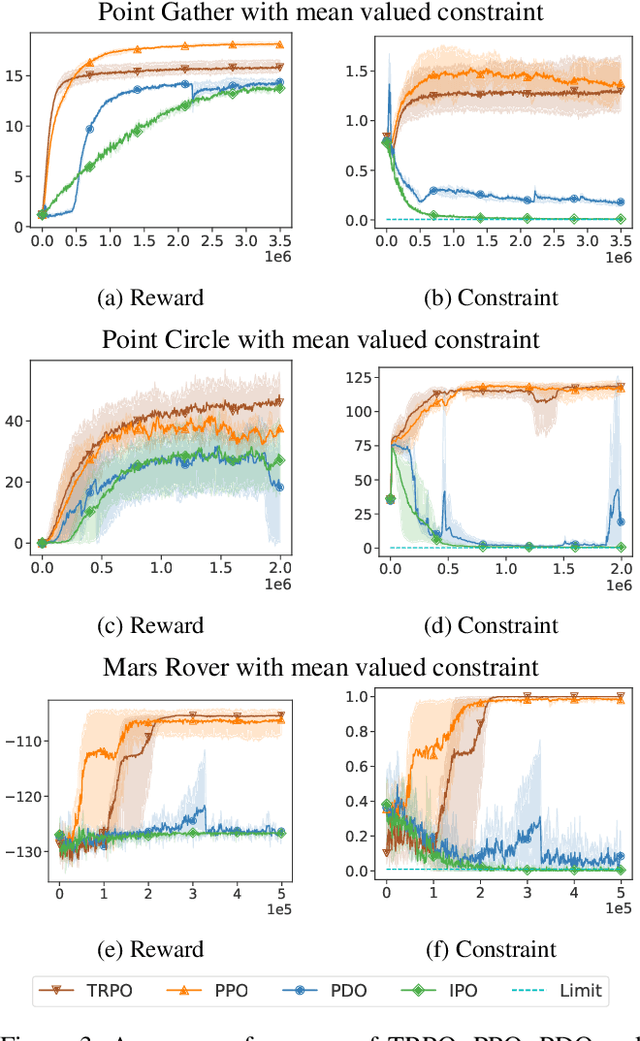
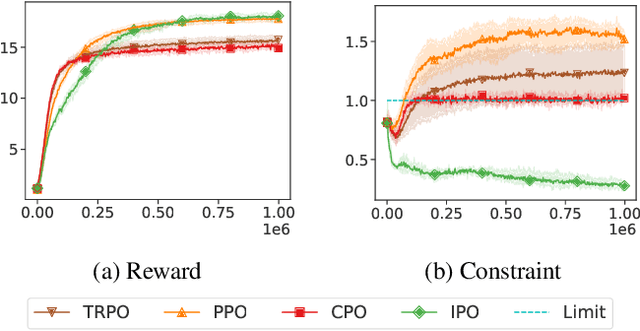
In this paper, we study reinforcement learning (RL) algorithms to solve real-world decision problems with the objective of maximizing the long-term reward as well as satisfying cumulative constraints. We propose a novel first-order policy optimization method, Interior-point Policy Optimization (IPO), which augments the objective with logarithmic barrier functions, inspired by the interior-point method. Our proposed method is easy to implement with performance guarantees and can handle general types of cumulative multiconstraint settings. We conduct extensive evaluations to compare our approach with state-of-the-art baselines. Our algorithm outperforms the baseline algorithms, in terms of reward maximization and constraint satisfaction.
Less is More: Culling the Training Set to Improve Robustness of Deep Neural Networks
Jan 09, 2018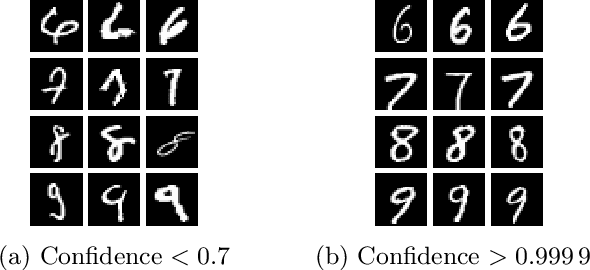

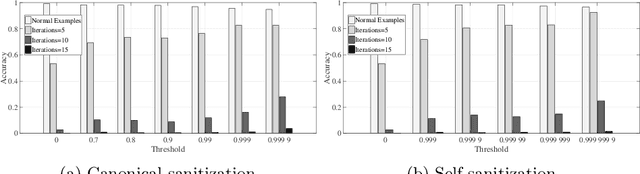
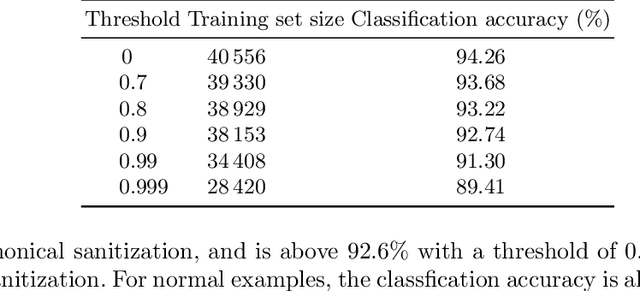
Deep neural networks are vulnerable to adversarial examples. Prior defenses attempted to make deep networks more robust by either improving the network architecture or adding adversarial examples into the training set, with their respective limitations. We propose a new direction. Motivated by recent research that shows that outliers in the training set have a high negative influence on the trained model, our approach makes the model more robust by detecting and removing outliers in the training set without modifying the network architecture or requiring adversarial examples. We propose two methods for detecting outliers based on canonical examples and on training errors, respectively. After removing the outliers, we train the classifier with the remaining examples to obtain a sanitized model. Our evaluation shows that the sanitized model improves classification accuracy and forces the attacks to generate adversarial examples with higher distortions. Moreover, the Kullback-Leibler divergence from the output of the original model to that of the sanitized model allows us to distinguish between normal and adversarial examples reliably.