 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisPCO: Visual Token Pruning Configuration Optimization via Budget-Aware Pareto-Frontier Learning for Vision-Language Models
Apr 16, 2026Visual token pruning methods effectively mitigate the quadratic computational growth caused by processing high-resolution images and video frames in vision-language models (VLMs). However, existing approaches rely on predefined pruning configurations without determining whether they achieve computation-performance optimality. In this work, we introduce , a novel framework that formulates visual token pruning as a Pareto configuration optimization problem to automatically identify optimal configurations. Our approach employs continuous relaxation and straight-through estimators to enable gradient-based search, solved via the Augmented Lagrangian method. Extensive experiments across 8 visual benchmarks demonstrate that effectively approximates the empirical Pareto frontier obtained through grid search and generalizes well across various pruning methods and VLM architectures. Furthermore, through learnable kernel functions, we investigate layer-wise pruning patterns and reveal that multi-step progressive pruning captures VLMs' hierarchical compression structure, achieving superior accuracy-efficiency trade-offs compared to single-layer approaches.
RADAR: Reasoning as Discrimination with Aligned Representations for LLM-based Knowledge Graph Reasoning
Feb 25, 2026Knowledge graph reasoning (KGR) infers missing facts, with recent advances increasingly harnessing the semantic priors and reasoning abilities of Large Language Models (LLMs). However, prevailing generative paradigms are prone to memorizing surface-level co-occurrences rather than learning genuine relational semantics, limiting out-of-distribution generalization. To address this, we propose RADAR, which reformulates KGR from generative pattern matching to discriminative relational reasoning. We recast KGR as discriminative entity selection, where reinforcement learning enforces relative entity separability beyond token-likelihood imitation. Leveraging this separability, inference operates directly in representation space, ensuring consistency with the discriminative optimization and bypassing generation-induced hallucinations. Across four benchmarks, RADAR achieves 5-6% relative gains on link prediction and triple classification over strong LLM baselines, while increasing task-relevant mutual information in intermediate representations by 62.9%, indicating more robust and transferable relational reasoning.
Extreme Value Policy Optimization for Safe Reinforcement Learning
Jan 17, 2026Ensuring safety is a critical challenge in applying Reinforcement Learning (RL) to real-world scenarios. Constrained Reinforcement Learning (CRL) addresses this by maximizing returns under predefined constraints, typically formulated as the expected cumulative cost. However, expectation-based constraints overlook rare but high-impact extreme value events in the tail distribution, such as black swan incidents, which can lead to severe constraint violations. To address this issue, we propose the Extreme Value policy Optimization (EVO) algorithm, leveraging Extreme Value Theory (EVT) to model and exploit extreme reward and cost samples, reducing constraint violations. EVO introduces an extreme quantile optimization objective to explicitly capture extreme samples in the cost tail distribution. Additionally, we propose an extreme prioritization mechanism during replay, amplifying the learning signal from rare but high-impact extreme samples. Theoretically, we establish upper bounds on expected constraint violations during policy updates, guaranteeing strict constraint satisfaction at a zero-violation quantile level. Further, we demonstrate that EVO achieves a lower probability of constraint violations than expectation-based methods and exhibits lower variance than quantile regression methods. Extensive experiments show that EVO significantly reduces constraint violations during training while maintaining competitive policy performance compared to baselines.
Controlling Underestimation Bias in Constrained Reinforcement Learning for Safe Exploration
Jan 17, 2026Constrained Reinforcement Learning (CRL) aims to maximize cumulative rewards while satisfying constraints. However, existing CRL algorithms often encounter significant constraint violations during training, limiting their applicability in safety-critical scenarios. In this paper, we identify the underestimation of the cost value function as a key factor contributing to these violations. To address this issue, we propose the Memory-driven Intrinsic Cost Estimation (MICE) method, which introduces intrinsic costs to mitigate underestimation and control bias to promote safer exploration. Inspired by flashbulb memory, where humans vividly recall dangerous experiences to avoid risks, MICE constructs a memory module that stores previously explored unsafe states to identify high-cost regions. The intrinsic cost is formulated as the pseudo-count of the current state visiting these risk regions. Furthermore, we propose an extrinsic-intrinsic cost value function that incorporates intrinsic costs and adopts a bias correction strategy. Using this function, we formulate an optimization objective within the trust region, along with corresponding optimization methods. Theoretically, we provide convergence guarantees for the proposed cost value function and establish the worst-case constraint violation for the MICE update. Extensive experiments demonstrate that MICE significantly reduces constraint violations while preserving policy performance comparable to baselines.
Improving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
CATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025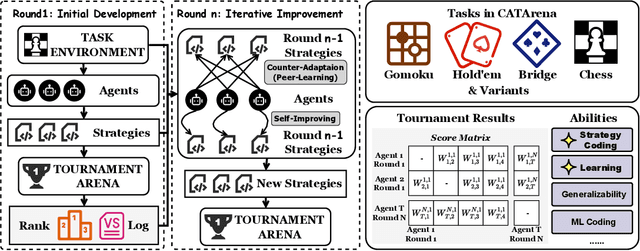

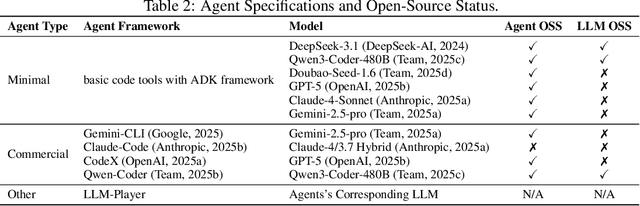
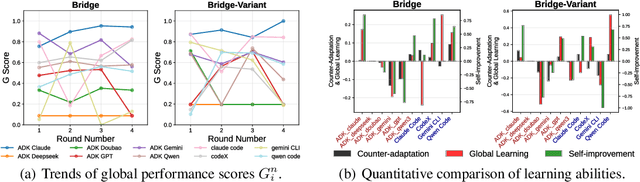
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
TopInG: Topologically Interpretable Graph Learning via Persistent Rationale Filtration
Oct 06, 2025Graph Neural Networks (GNNs) have shown remarkable success across various scientific fields, yet their adoption in critical decision-making is often hindered by a lack of interpretability. Recently, intrinsically interpretable GNNs have been studied to provide insights into model predictions by identifying rationale substructures in graphs. However, existing methods face challenges when the underlying rationale subgraphs are complex and varied. In this work, we propose TopInG: Topologically Interpretable Graph Learning, a novel topological framework that leverages persistent homology to identify persistent rationale subgraphs. TopInG employs a rationale filtration learning approach to model an autoregressive generation process of rationale subgraphs, and introduces a self-adjusted topological constraint, termed topological discrepancy, to enforce a persistent topological distinction between rationale subgraphs and irrelevant counterparts. We provide theoretical guarantees that our loss function is uniquely optimized by the ground truth under specific conditions. Extensive experiments demonstrate TopInG's effectiveness in tackling key challenges, such as handling variform rationale subgraphs, balancing predictive performance with interpretability, and mitigating spurious correlations. Results show that our approach improves upon state-of-the-art methods on both predictive accuracy and interpretation quality.
Way to Specialist: Closing Loop Between Specialized LLM and Evolving Domain Knowledge Graph
Nov 28, 2024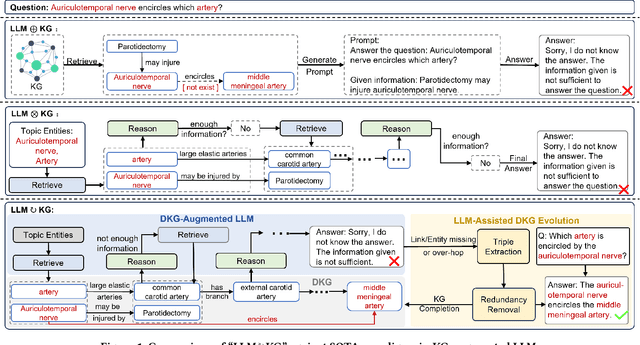
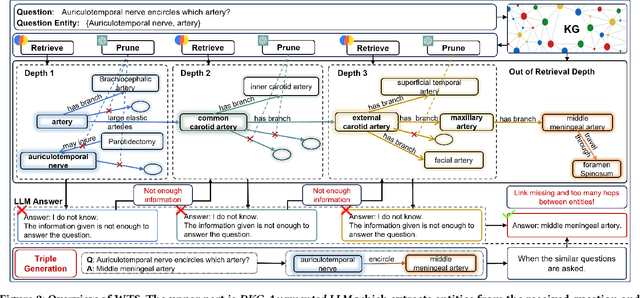
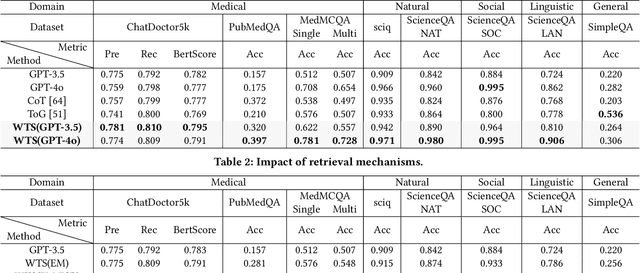
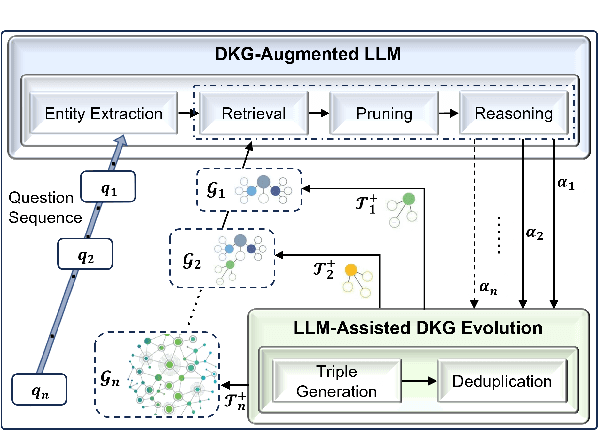
Large language models (LLMs) have demonstrated exceptional performance across a wide variety of domains. Nonetheless, generalist LLMs continue to fall short in reasoning tasks necessitating specialized knowledge. Prior investigations into specialized LLMs focused on domain-specific training, which entails substantial efforts in domain data acquisition and model parameter fine-tuning. To address these challenges, this paper proposes the Way-to-Specialist (WTS) framework, which synergizes retrieval-augmented generation with knowledge graphs (KGs) to enhance the specialized capability of LLMs in the absence of specialized training. In distinction to existing paradigms that merely utilize external knowledge from general KGs or static domain KGs to prompt LLM for enhanced domain-specific reasoning, WTS proposes an innovative "LLM$\circlearrowright$KG" paradigm, which achieves bidirectional enhancement between specialized LLM and domain knowledge graph (DKG). The proposed paradigm encompasses two closely coupled components: the DKG-Augmented LLM and the LLM-Assisted DKG Evolution. The former retrieves question-relevant domain knowledge from DKG and uses it to prompt LLM to enhance the reasoning capability for domain-specific tasks; the latter leverages LLM to generate new domain knowledge from processed tasks and use it to evolve DKG. WTS closes the loop between DKG-Augmented LLM and LLM-Assisted DKG Evolution, enabling continuous improvement in the domain specialization as it progressively answers and learns from domain-specific questions. We validate the performance of WTS on 6 datasets spanning 5 domains. The experimental results show that WTS surpasses the previous SOTA in 4 specialized domains and achieves a maximum performance improvement of 11.3%.
AceParse: A Comprehensive Dataset with Diverse Structured Texts for Academic Literature Parsing
Sep 16, 2024With the development of data-centric AI, the focus has shifted from model-driven approaches to improving data quality. Academic literature, as one of the crucial types, is predominantly stored in PDF formats and needs to be parsed into texts before further processing. However, parsing diverse structured texts in academic literature remains challenging due to the lack of datasets that cover various text structures. In this paper, we introduce AceParse, the first comprehensive dataset designed to support the parsing of a wide range of structured texts, including formulas, tables, lists, algorithms, and sentences with embedded mathematical expressions. Based on AceParse, we fine-tuned a multimodal model, named AceParser, which accurately parses various structured texts within academic literature. This model outperforms the previous state-of-the-art by 4.1% in terms of F1 score and by 5% in Jaccard Similarity, demonstrating the potential of multimodal models in academic literature parsing. Our dataset is available at https://github.com/JHW5981/AceParse.
Unlock the Power of Frozen LLMs in Knowledge Graph Completion
Aug 13, 2024



Classical knowledge graph completion (KGC) methods rely solely on structural information, struggling with the inherent sparsity of knowledge graphs (KGs). Large Language Models (LLMs) learn extensive knowledge from large corpora with powerful context modeling, which is ideal for mitigating the limitations of previous methods. Directly fine-tuning LLMs offers great capability but comes at the cost of huge time and memory consumption, while utilizing frozen LLMs yields suboptimal results. In this work, we aim to leverage LLMs for KGC effectively and efficiently. We capture the context-aware hidden states of knowledge triples by employing prompts to stimulate the intermediate layers of LLMs. We then train a data-efficient classifier on these hidden states to harness the inherent capabilities of frozen LLMs in KGC. We also generate entity descriptions with subgraph sampling on KGs, reducing the ambiguity of triplets and enriching the knowledge representation. Extensive experiments on standard benchmarks showcase the efficiency and effectiveness of our approach. We outperform classical KGC methods on most datasets and match the performance of fine-tuned LLMs. Additionally, compared to fine-tuned LLMs, we boost GPU memory efficiency by \textbf{$188\times$} and speed up training+inference by \textbf{$13.48\times$}.