 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLakeMLB: Data Lake Machine Learning Benchmark
Feb 11, 2026Modern data lakes have emerged as foundational platforms for large-scale machine learning, enabling flexible storage of heterogeneous data and structured analytics through table-oriented abstractions. Despite their growing importance, standardized benchmarks for evaluating machine learning performance in data lake environments remain scarce. To address this gap, we present LakeMLB (Data Lake Machine Learning Benchmark), designed for the most common multi-source, multi-table scenarios in data lakes. LakeMLB focuses on two representative multi-table scenarios, Union and Join, and provides three real-world datasets for each scenario, covering government open data, finance, Wikipedia, and online marketplaces. The benchmark supports three representative integration strategies: pre-training-based, data augmentation-based, and feature augmentation-based approaches. We conduct extensive experiments with state-of-the-art tabular learning methods, offering insights into their performance under complex data lake scenarios. We release both datasets and code to facilitate rigorous research on machine learning in data lake ecosystems; the benchmark is available at https://github.com/zhengwang100/LakeMLB.
Fre-CW: Targeted Attack on Time Series Forecasting using Frequency Domain Loss
Aug 12, 2025Transformer-based models have made significant progress in time series forecasting. However, a key limitation of deep learning models is their susceptibility to adversarial attacks, which has not been studied enough in the context of time series prediction. In contrast to areas such as computer vision, where adversarial robustness has been extensively studied, frequency domain features of time series data play an important role in the prediction task but have not been sufficiently explored in terms of adversarial attacks. This paper proposes a time series prediction attack algorithm based on frequency domain loss. Specifically, we adapt an attack method originally designed for classification tasks to the prediction field and optimize the adversarial samples using both time-domain and frequency-domain losses. To the best of our knowledge, there is no relevant research on using frequency information for time-series adversarial attacks. Our experimental results show that these current time series prediction models are vulnerable to adversarial attacks, and our approach achieves excellent performance on major time series forecasting datasets.
Automating Safety Enhancement for LLM-based Agents with Synthetic Risk Scenarios
May 23, 2025



Large Language Model (LLM)-based agents are increasingly deployed in real-world applications such as "digital assistants, autonomous customer service, and decision-support systems", where their ability to "interact in multi-turn, tool-augmented environments" makes them indispensable. However, ensuring the safety of these agents remains a significant challenge due to the diverse and complex risks arising from dynamic user interactions, external tool usage, and the potential for unintended harmful behaviors. To address this critical issue, we propose AutoSafe, the first framework that systematically enhances agent safety through fully automated synthetic data generation. Concretely, 1) we introduce an open and extensible threat model, OTS, which formalizes how unsafe behaviors emerge from the interplay of user instructions, interaction contexts, and agent actions. This enables precise modeling of safety risks across diverse scenarios. 2) we develop a fully automated data generation pipeline that simulates unsafe user behaviors, applies self-reflective reasoning to generate safe responses, and constructs a large-scale, diverse, and high-quality safety training dataset-eliminating the need for hazardous real-world data collection. To evaluate the effectiveness of our framework, we design comprehensive experiments on both synthetic and real-world safety benchmarks. Results demonstrate that AutoSafe boosts safety scores by 45% on average and achieves a 28.91% improvement on real-world tasks, validating the generalization ability of our learned safety strategies. These results highlight the practical advancement and scalability of AutoSafe in building safer LLM-based agents for real-world deployment. We have released the project page at https://auto-safe.github.io/.
Multimodal Online Federated Learning with Modality Missing in Internet of Things
May 22, 2025The Internet of Things (IoT) ecosystem generates vast amounts of multimodal data from heterogeneous sources such as sensors, cameras, and microphones. As edge intelligence continues to evolve, IoT devices have progressed from simple data collection units to nodes capable of executing complex computational tasks. This evolution necessitates the adoption of distributed learning strategies to effectively handle multimodal data in an IoT environment. Furthermore, the real-time nature of data collection and limited local storage on edge devices in IoT call for an online learning paradigm. To address these challenges, we introduce the concept of Multimodal Online Federated Learning (MMO-FL), a novel framework designed for dynamic and decentralized multimodal learning in IoT environments. Building on this framework, we further account for the inherent instability of edge devices, which frequently results in missing modalities during the learning process. We conduct a comprehensive theoretical analysis under both complete and missing modality scenarios, providing insights into the performance degradation caused by missing modalities. To mitigate the impact of modality missing, we propose the Prototypical Modality Mitigation (PMM) algorithm, which leverages prototype learning to effectively compensate for missing modalities. Experimental results on two multimodal datasets further demonstrate the superior performance of PMM compared to benchmarks.
How Does the Smoothness Approximation Method Facilitate Generalization for Federated Adversarial Learning?
Dec 11, 2024
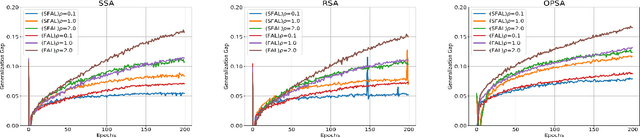
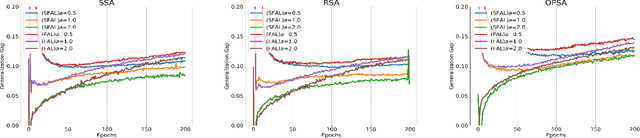
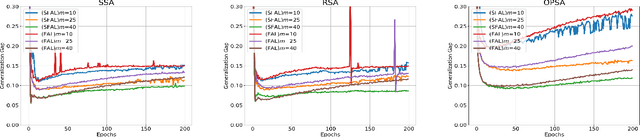
Federated Adversarial Learning (FAL) is a robust framework for resisting adversarial attacks on federated learning. Although some FAL studies have developed efficient algorithms, they primarily focus on convergence performance and overlook generalization. Generalization is crucial for evaluating algorithm performance on unseen data. However, generalization analysis is more challenging due to non-smooth adversarial loss functions. A common approach to addressing this issue is to leverage smoothness approximation. In this paper, we develop algorithm stability measures to evaluate the generalization performance of two popular FAL algorithms: \textit{Vanilla FAL (VFAL)} and {\it Slack FAL (SFAL)}, using three different smooth approximation methods: 1) \textit{Surrogate Smoothness Approximation (SSA)}, (2) \textit{Randomized Smoothness Approximation (RSA)}, and (3) \textit{Over-Parameterized Smoothness Approximation (OPSA)}. Based on our in-depth analysis, we answer the question of how to properly set the smoothness approximation method to mitigate generalization error in FAL. Moreover, we identify RSA as the most effective method for reducing generalization error. In highly data-heterogeneous scenarios, we also recommend employing SFAL to mitigate the deterioration of generalization performance caused by heterogeneity. Based on our theoretical results, we provide insights to help develop more efficient FAL algorithms, such as designing new metrics and dynamic aggregation rules to mitigate heterogeneity.
Way to Specialist: Closing Loop Between Specialized LLM and Evolving Domain Knowledge Graph
Nov 28, 2024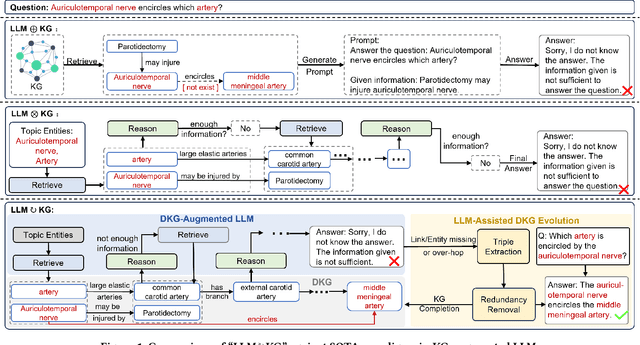
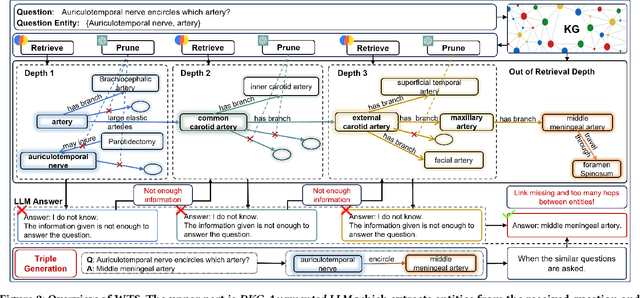
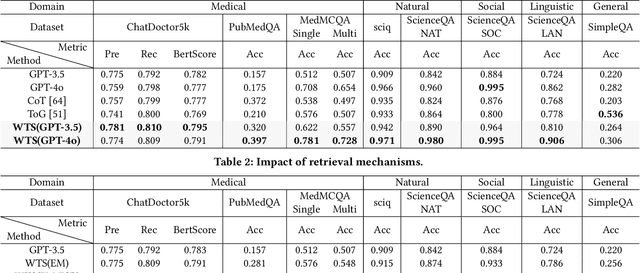
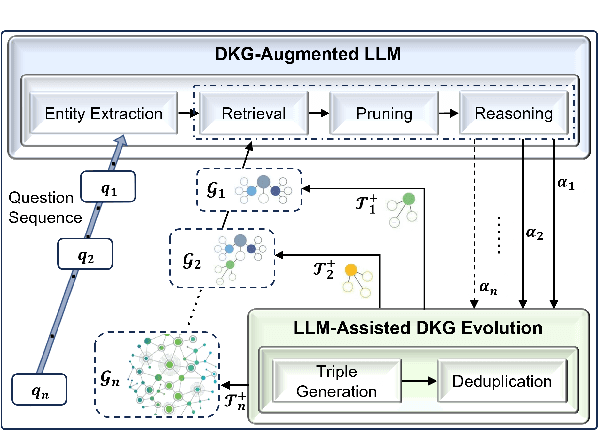
Large language models (LLMs) have demonstrated exceptional performance across a wide variety of domains. Nonetheless, generalist LLMs continue to fall short in reasoning tasks necessitating specialized knowledge. Prior investigations into specialized LLMs focused on domain-specific training, which entails substantial efforts in domain data acquisition and model parameter fine-tuning. To address these challenges, this paper proposes the Way-to-Specialist (WTS) framework, which synergizes retrieval-augmented generation with knowledge graphs (KGs) to enhance the specialized capability of LLMs in the absence of specialized training. In distinction to existing paradigms that merely utilize external knowledge from general KGs or static domain KGs to prompt LLM for enhanced domain-specific reasoning, WTS proposes an innovative "LLM$\circlearrowright$KG" paradigm, which achieves bidirectional enhancement between specialized LLM and domain knowledge graph (DKG). The proposed paradigm encompasses two closely coupled components: the DKG-Augmented LLM and the LLM-Assisted DKG Evolution. The former retrieves question-relevant domain knowledge from DKG and uses it to prompt LLM to enhance the reasoning capability for domain-specific tasks; the latter leverages LLM to generate new domain knowledge from processed tasks and use it to evolve DKG. WTS closes the loop between DKG-Augmented LLM and LLM-Assisted DKG Evolution, enabling continuous improvement in the domain specialization as it progressively answers and learns from domain-specific questions. We validate the performance of WTS on 6 datasets spanning 5 domains. The experimental results show that WTS surpasses the previous SOTA in 4 specialized domains and achieves a maximum performance improvement of 11.3%.
Stability and Generalization for Stochastic Recursive Momentum-based Algorithms for (Strongly-)Convex One to $K$-Level Stochastic Optimizations
Jul 07, 2024


STOchastic Recursive Momentum (STORM)-based algorithms have been widely developed to solve one to $K$-level ($K \geq 3$) stochastic optimization problems. Specifically, they use estimators to mitigate the biased gradient issue and achieve near-optimal convergence results. However, there is relatively little work on understanding their generalization performance, particularly evident during the transition from one to $K$-level optimization contexts. This paper provides a comprehensive generalization analysis of three representative STORM-based algorithms: STORM, COVER, and SVMR, for one, two, and $K$-level stochastic optimizations under both convex and strongly convex settings based on algorithmic stability. Firstly, we define stability for $K$-level optimizations and link it to generalization. Then, we detail the stability results for three prominent STORM-based algorithms. Finally, we derive their excess risk bounds by balancing stability results with optimization errors. Our theoretical results provide strong evidence to complete STORM-based algorithms: (1) Each estimator may decrease their stability due to variance with its estimation target. (2) Every additional level might escalate the generalization error, influenced by the stability and the variance between its cumulative stochastic gradient and the true gradient. (3) Increasing the batch size for the initial computation of estimators presents a favorable trade-off, enhancing the generalization performance.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024



Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
Automated Customization of On-Thing Inference for Quality-of-Experience Enhancement
Dec 11, 2021
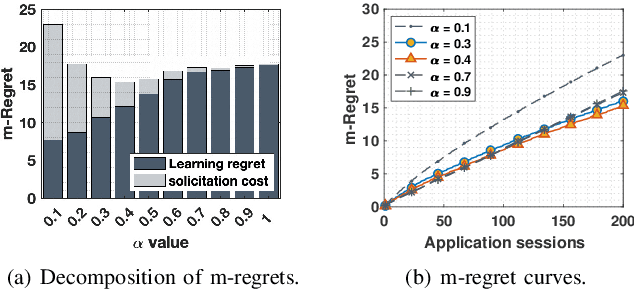
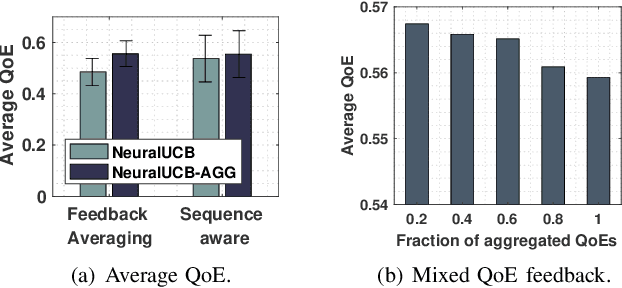
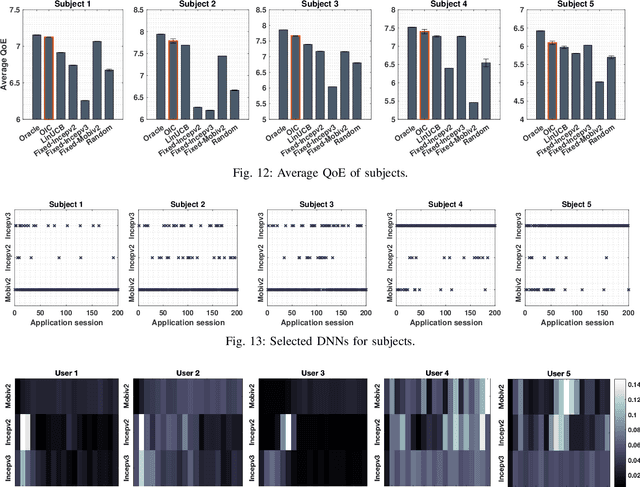
The rapid uptake of intelligent applications is pushing deep learning (DL) capabilities to Internet-of-Things (IoT). Despite the emergence of new tools for embedding deep neural networks (DNNs) into IoT devices, providing satisfactory Quality of Experience (QoE) to users is still challenging due to the heterogeneity in DNN architectures, IoT devices, and user preferences. This paper studies automated customization for DL inference on IoT devices (termed as on-thing inference), and our goal is to enhance user QoE by configuring the on-thing inference with an appropriate DNN for users under different usage scenarios. The core of our method is a DNN selection module that learns user QoE patterns on-the-fly and identifies the best-fit DNN for on-thing inference with the learned knowledge. It leverages a novel online learning algorithm, NeuralUCB, that has excellent generalization ability for handling various user QoE patterns. We also embed the knowledge transfer technique in NeuralUCB to expedite the learning process. However, NeuralUCB frequently solicits QoE ratings from users, which incurs non-negligible inconvenience. To address this problem, we design feedback solicitation schemes to reduce the number of QoE solicitations while maintaining the learning efficiency of NeuralUCB. A pragmatic problem, aggregated QoE, is further investigated to improve the practicality of our framework. We conduct experiments on both synthetic and real-world data. The results indicate that our method efficiently learns the user QoE pattern with few solicitations and provides drastic QoE enhancement for IoT devices.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 03, 2021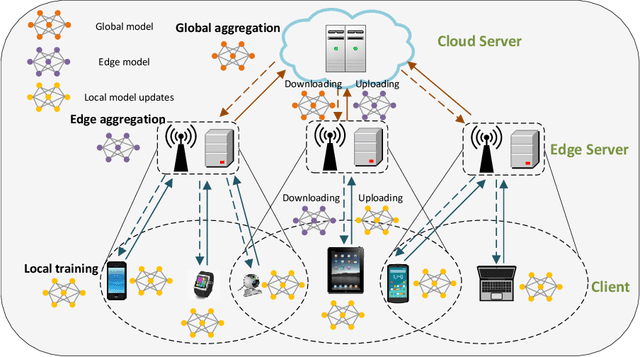
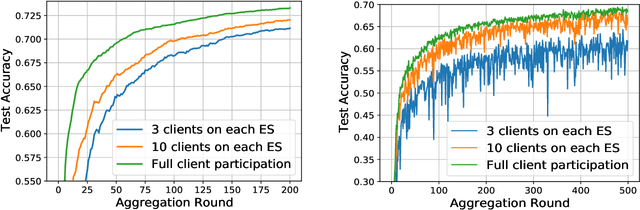
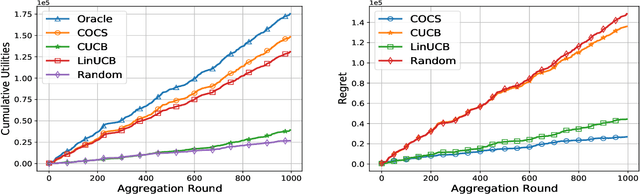
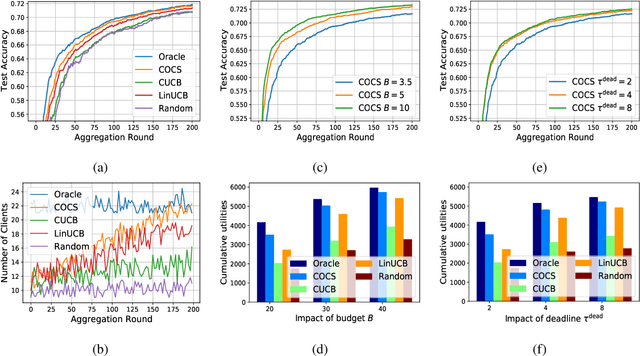
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.