 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Strokes by Learning Offset Attributes between Strokes for Flexible Sketch Edit at Stroke-Level
Jan 31, 2026Sketch edit at stroke-level aims to transplant source strokes onto a target sketch via stroke expansion or replacement, while preserving semantic consistency and visual fidelity with the target sketch. Recent studies addressed it by relocating source strokes at appropriate canvas positions. However, as source strokes could exhibit significant variations in both size and orientation, we may fail to produce plausible sketch editing results by merely repositioning them without further adjustments. For example, anchoring an oversized source stroke onto the target without proper scaling would fail to produce a semantically coherent outcome. In this paper, we propose SketchMod to refine the source stroke through transformation so as to align it with the target sketch's patterns, further realize flexible sketch edit at stroke-level. As the source stroke refinement is governed by the patterns of the target sketch, we learn three key offset attributes (scale, orientation and position) from the source stroke to another, and align it with the target by: 1) resizing to match spatial proportions by scale, 2) rotating to align with local geometry by orientation, and 3) displacing to meet with semantic layout by position. Besides, a stroke's profiles can be precisely controlled during sketch edit via the exposed captured stroke attributes. Experimental results indicate that SketchMod achieves precise and flexible performances on stroke-level sketch edit.
Reliable Brain Tumor Segmentation Based on Spiking Neural Networks with Efficient Training
Jan 23, 2026We propose a reliable and energy-efficient framework for 3D brain tumor segmentation using spiking neural networks (SNNs). A multi-view ensemble of sagittal, coronal, and axial SNN models provides voxel-wise uncertainty estimation and enhances segmentation robustness. To address the high computational cost in training SNN models for semantic image segmentation, we employ Forward Propagation Through Time (FPTT), which maintains temporal learning efficiency with significantly reduced computational cost. Experiments on the Multimodal Brain Tumor Segmentation Challenges (BraTS 2017 and BraTS 2023) demonstrate competitive accuracy, well-calibrated uncertainty, and an 87% reduction in FLOPs, underscoring the potential of SNNs for reliable, low-power medical IoT and Point-of-Care systems.
Local Gradient Regulation Stabilizes Federated Learning under Client Heterogeneity
Jan 07, 2026Federated learning (FL) enables collaborative model training across distributed clients without sharing raw data, yet its stability is fundamentally challenged by statistical heterogeneity in realistic deployments. Here, we show that client heterogeneity destabilizes FL primarily by distorting local gradient dynamics during client-side optimization, causing systematic drift that accumulates across communication rounds and impedes global convergence. This observation highlights local gradients as a key regulatory lever for stabilizing heterogeneous FL systems. Building on this insight, we develop a general client-side perspective that regulates local gradient contributions without incurring additional communication overhead. Inspired by swarm intelligence, we instantiate this perspective through Exploratory--Convergent Gradient Re-aggregation (ECGR), which balances well-aligned and misaligned gradient components to preserve informative updates while suppressing destabilizing effects. Theoretical analysis and extensive experiments, including evaluations on the LC25000 medical imaging dataset, demonstrate that regulating local gradient dynamics consistently stabilizes federated learning across state-of-the-art methods under heterogeneous data distributions.
Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025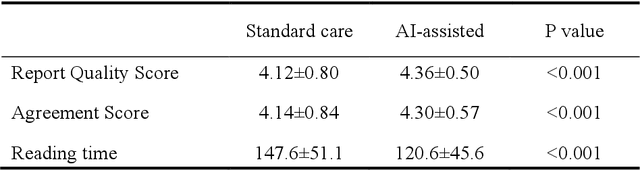
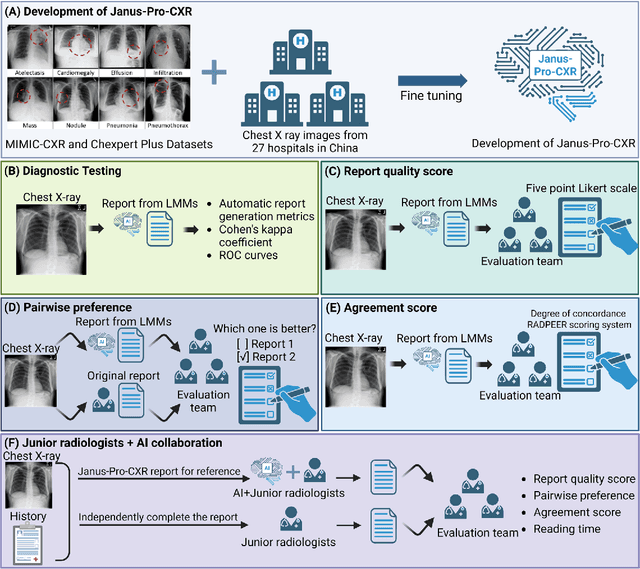
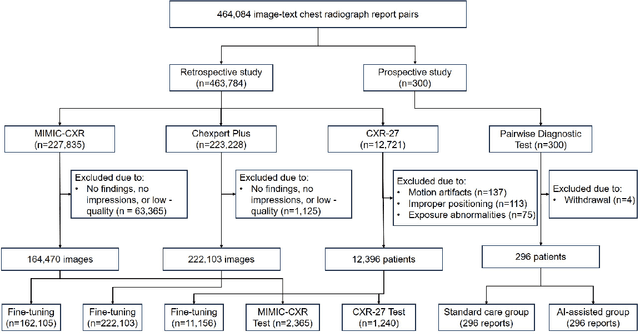
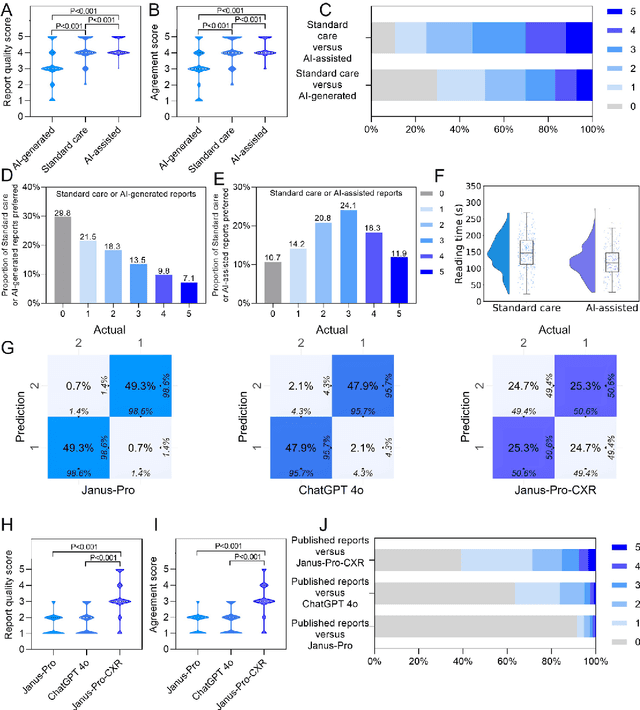
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
A Machine Learning-Based Multimodal Framework for Wearable Sensor-Based Archery Action Recognition and Stress Estimation
Nov 18, 2025In precision sports such as archery, athletes' performance depends on both biomechanical stability and psychological resilience. Traditional motion analysis systems are often expensive and intrusive, limiting their use in natural training environments. To address this limitation, we propose a machine learning-based multimodal framework that integrates wearable sensor data for simultaneous action recognition and stress estimation. Using a self-developed wrist-worn device equipped with an accelerometer and photoplethysmography (PPG) sensor, we collected synchronized motion and physiological data during real archery sessions. For motion recognition, we introduce a novel feature--Smoothed Differential Acceleration (SmoothDiff)--and employ a Long Short-Term Memory (LSTM) model to identify motion phases, achieving 96.8% accuracy and 95.9% F1-score. For stress estimation, we extract heart rate variability (HRV) features from PPG signals and apply a Multi-Layer Perceptron (MLP) classifier, achieving 80% accuracy in distinguishing high- and low-stress levels. The proposed framework demonstrates that integrating motion and physiological sensing can provide meaningful insights into athletes' technical and mental states. This approach offers a foundation for developing intelligent, real-time feedback systems for training optimization in archery and other precision sports.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
APT: Affine Prototype-Timestamp For Time Series Forecasting Under Distribution Shift
Nov 17, 2025Time series forecasting under distribution shift remains challenging, as existing deep learning models often rely on local statistical normalization (e.g., mean and variance) that fails to capture global distribution shift. Methods like RevIN and its variants attempt to decouple distribution and pattern but still struggle with missing values, noisy observations, and invalid channel-wise affine transformation. To address these limitations, we propose Affine Prototype Timestamp (APT), a lightweight and flexible plug-in module that injects global distribution features into the normalization-forecasting pipeline. By leveraging timestamp conditioned prototype learning, APT dynamically generates affine parameters that modulate both input and output series, enabling the backbone to learn from self-supervised, distribution-aware clustered instances. APT is compatible with arbitrary forecasting backbones and normalization strategies while introducing minimal computational overhead. Extensive experiments across six benchmark datasets and multiple backbone-normalization combinations demonstrate that APT significantly improves forecasting performance under distribution shift.
LLaVA-RE: Binary Image-Text Relevancy Evaluation with Multimodal Large Language Model
Aug 07, 2025


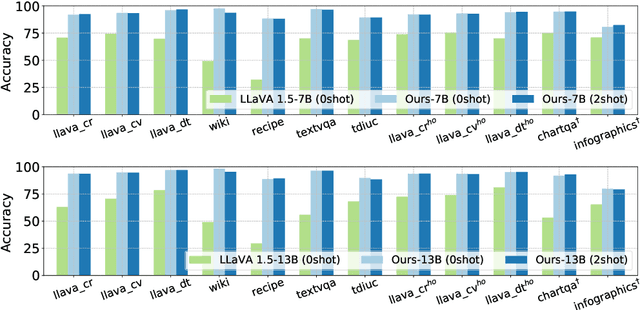
Multimodal generative AI usually involves generating image or text responses given inputs in another modality. The evaluation of image-text relevancy is essential for measuring response quality or ranking candidate responses. In particular, binary relevancy evaluation, i.e., ``Relevant'' vs. ``Not Relevant'', is a fundamental problem. However, this is a challenging task considering that texts have diverse formats and the definition of relevancy varies in different scenarios. We find that Multimodal Large Language Models (MLLMs) are an ideal choice to build such evaluators, as they can flexibly handle complex text formats and take in additional task information. In this paper, we present LLaVA-RE, a first attempt for binary image-text relevancy evaluation with MLLM. It follows the LLaVA architecture and adopts detailed task instructions and multimodal in-context samples. In addition, we propose a novel binary relevancy data set that covers various tasks. Experimental results validate the effectiveness of our framework.
Merlin: Multi-View Representation Learning for Robust Multivariate Time Series Forecasting with Unfixed Missing Rates
Jun 14, 2025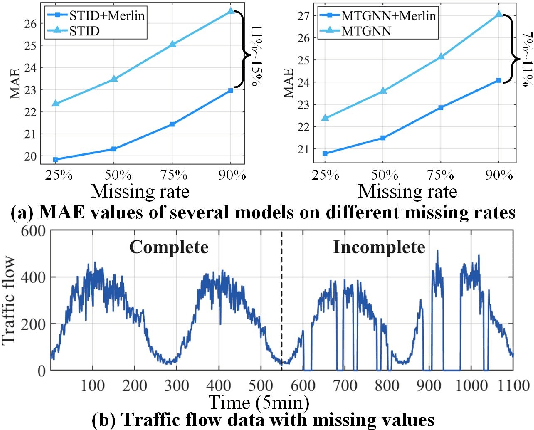
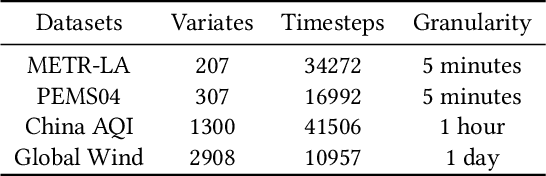
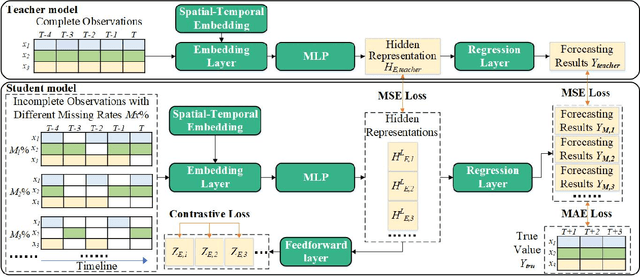
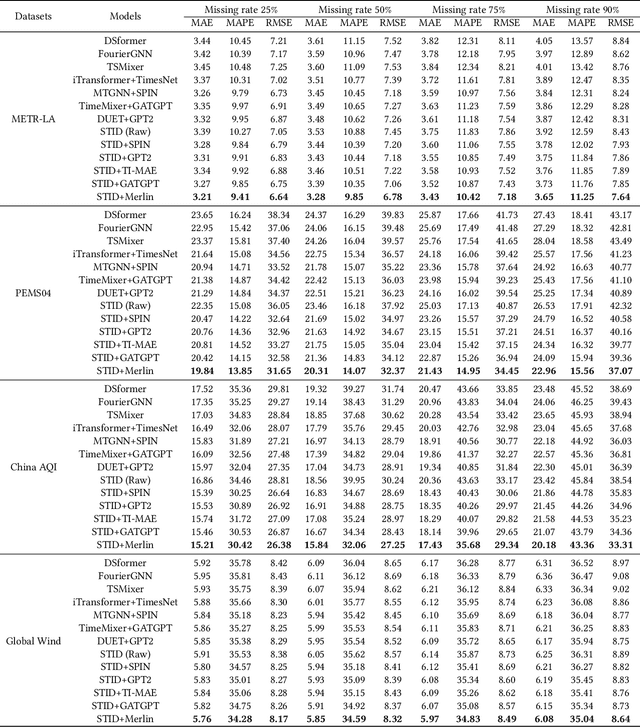
Multivariate Time Series Forecasting (MTSF) involves predicting future values of multiple interrelated time series. Recently, deep learning-based MTSF models have gained significant attention for their promising ability to mine semantics (global and local information) within MTS data. However, these models are pervasively susceptible to missing values caused by malfunctioning data collectors. These missing values not only disrupt the semantics of MTS, but their distribution also changes over time. Nevertheless, existing models lack robustness to such issues, leading to suboptimal forecasting performance. To this end, in this paper, we propose Multi-View Representation Learning (Merlin), which can help existing models achieve semantic alignment between incomplete observations with different missing rates and complete observations in MTS. Specifically, Merlin consists of two key modules: offline knowledge distillation and multi-view contrastive learning. The former utilizes a teacher model to guide a student model in mining semantics from incomplete observations, similar to those obtainable from complete observations. The latter improves the student model's robustness by learning from positive/negative data pairs constructed from incomplete observations with different missing rates, ensuring semantic alignment across different missing rates. Therefore, Merlin is capable of effectively enhancing the robustness of existing models against unfixed missing rates while preserving forecasting accuracy. Experiments on four real-world datasets demonstrate the superiority of Merlin.