 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
Jan 26, 2026Deep research agents have shown remarkable potential in handling long-horizon tasks. However, state-of-the-art performance typically relies on online reinforcement learning (RL), which is financially expensive due to extensive API calls. While offline training offers a more efficient alternative, its progress is hindered by the scarcity of high-quality research trajectories. In this paper, we demonstrate that expensive online reinforcement learning is not all you need to build powerful research agents. To bridge this gap, we introduce a fully open-source suite designed for effective offline training. Our core contributions include DeepForge, a ready-to-use task synthesis framework that generates large-scale research queries without heavy preprocessing; and a curated collection of 66k QA pairs, 33k SFT trajectories, and 21k DPO pairs. Leveraging these resources, we train OffSeeker (8B), a model developed entirely offline. Extensive evaluations across six benchmarks show that OffSeeker not only leads among similar-sized agents but also remains competitive with 30B-parameter systems trained via heavy online RL.
Agent2World: Learning to Generate Symbolic World Models via Adaptive Multi-Agent Feedback
Dec 26, 2025Symbolic world models (e.g., PDDL domains or executable simulators) are central to model-based planning, but training LLMs to generate such world models is limited by the lack of large-scale verifiable supervision. Current approaches rely primarily on static validation methods that fail to catch behavior-level errors arising from interactive execution. In this paper, we propose Agent2World, a tool-augmented multi-agent framework that achieves strong inference-time world-model generation and also serves as a data engine for supervised fine-tuning, by grounding generation in multi-agent feedback. Agent2World follows a three-stage pipeline: (i) A Deep Researcher agent performs knowledge synthesis by web searching to address specification gaps; (ii) A Model Developer agent implements executable world models; And (iii) a specialized Testing Team conducts adaptive unit testing and simulation-based validation. Agent2World demonstrates superior inference-time performance across three benchmarks spanning both Planning Domain Definition Language (PDDL) and executable code representations, achieving consistent state-of-the-art results. Beyond inference, Testing Team serves as an interactive environment for the Model Developer, providing behavior-aware adaptive feedback that yields multi-turn training trajectories. The model fine-tuned on these trajectories substantially improves world-model generation, yielding an average relative gain of 30.95% over the same model before training. Project page: https://agent2world.github.io.
The Universal Landscape of Human Reasoning
Oct 24, 2025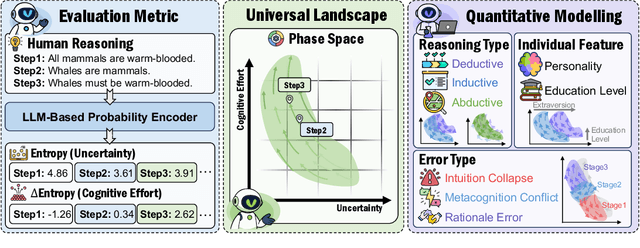
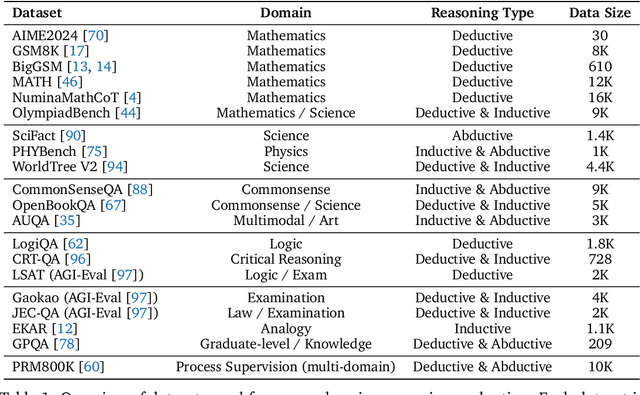
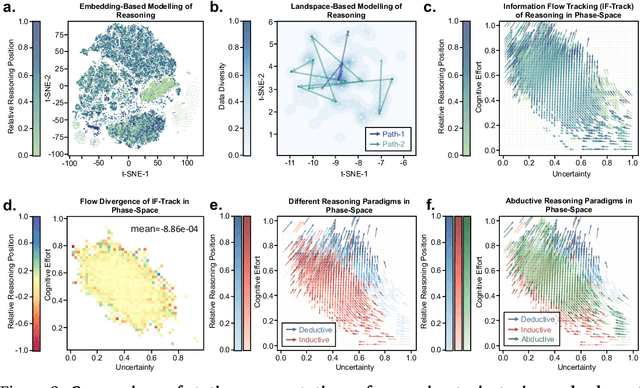
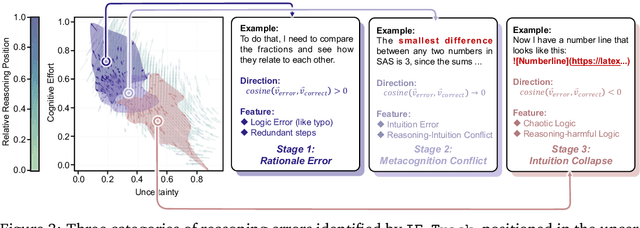
Understanding how information is dynamically accumulated and transformed in human reasoning has long challenged cognitive psychology, philosophy, and artificial intelligence. Existing accounts, from classical logic to probabilistic models, illuminate aspects of output or individual modelling, but do not offer a unified, quantitative description of general human reasoning dynamics. To solve this, we introduce Information Flow Tracking (IF-Track), that uses large language models (LLMs) as probabilistic encoder to quantify information entropy and gain at each reasoning step. Through fine-grained analyses across diverse tasks, our method is the first successfully models the universal landscape of human reasoning behaviors within a single metric space. We show that IF-Track captures essential reasoning features, identifies systematic error patterns, and characterizes individual differences. Applied to discussion of advanced psychological theory, we first reconcile single- versus dual-process theories in IF-Track and discover the alignment of artificial and human cognition and how LLMs reshaping human reasoning process. This approach establishes a quantitative bridge between theory and measurement, offering mechanistic insights into the architecture of reasoning.
AutoPR: Let's Automate Your Academic Promotion!
Oct 10, 2025As the volume of peer-reviewed research surges, scholars increasingly rely on social platforms for discovery, while authors invest considerable effort in promoting their work to ensure visibility and citations. To streamline this process and reduce the reliance on human effort, we introduce Automatic Promotion (AutoPR), a novel task that transforms research papers into accurate, engaging, and timely public content. To enable rigorous evaluation, we release PRBench, a multimodal benchmark that links 512 peer-reviewed articles to high-quality promotional posts, assessing systems along three axes: Fidelity (accuracy and tone), Engagement (audience targeting and appeal), and Alignment (timing and channel optimization). We also introduce PRAgent, a multi-agent framework that automates AutoPR in three stages: content extraction with multimodal preparation, collaborative synthesis for polished outputs, and platform-specific adaptation to optimize norms, tone, and tagging for maximum reach. When compared to direct LLM pipelines on PRBench, PRAgent demonstrates substantial improvements, including a 604% increase in total watch time, a 438% rise in likes, and at least a 2.9x boost in overall engagement. Ablation studies show that platform modeling and targeted promotion contribute the most to these gains. Our results position AutoPR as a tractable, measurable research problem and provide a roadmap for scalable, impactful automated scholarly communication.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025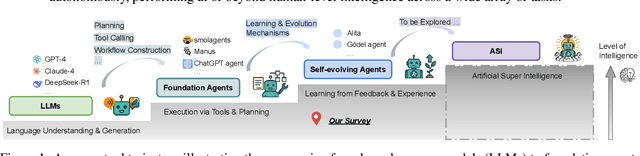

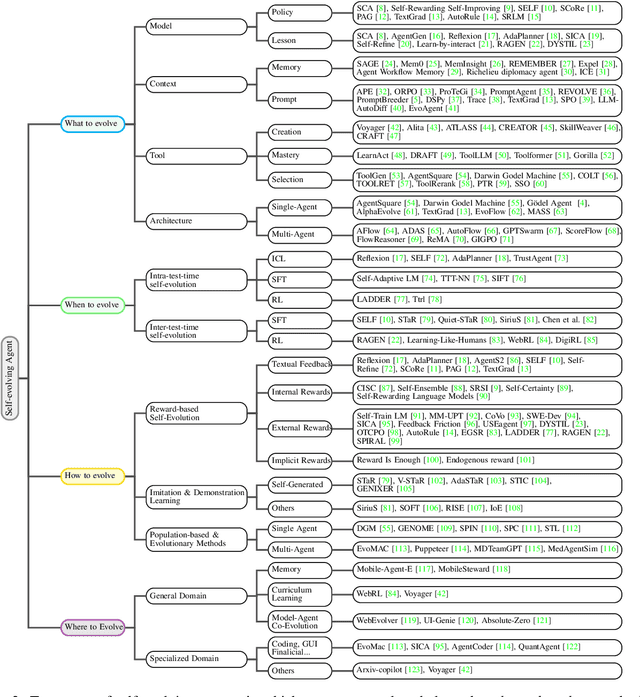
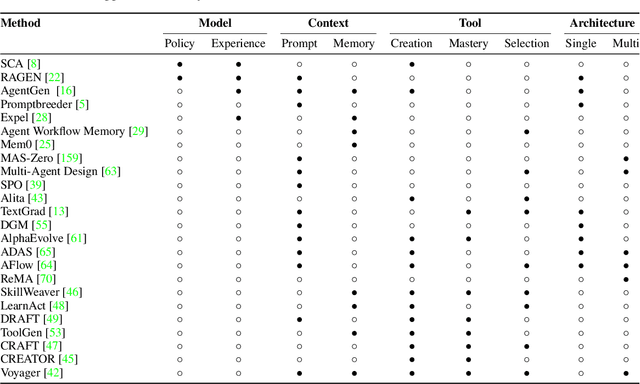
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
AI4Research: A Survey of Artificial Intelligence for Scientific Research
Jul 02, 2025Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs) such as OpenAI-o1 and DeepSeek-R1, have demonstrated remarkable capabilities in complex domains such as logical reasoning and experimental coding. Motivated by these advancements, numerous studies have explored the application of AI in the innovation process, particularly in the context of scientific research. These AI technologies primarily aim to develop systems that can autonomously conduct research processes across a wide range of scientific disciplines. Despite these significant strides, a comprehensive survey on AI for Research (AI4Research) remains absent, which hampers our understanding and impedes further development in this field. To address this gap, we present a comprehensive survey and offer a unified perspective on AI4Research. Specifically, the main contributions of our work are as follows: (1) Systematic taxonomy: We first introduce a systematic taxonomy to classify five mainstream tasks in AI4Research. (2) New frontiers: Then, we identify key research gaps and highlight promising future directions, focusing on the rigor and scalability of automated experiments, as well as the societal impact. (3) Abundant applications and resources: Finally, we compile a wealth of resources, including relevant multidisciplinary applications, data corpora, and tools. We hope our work will provide the research community with quick access to these resources and stimulate innovative breakthroughs in AI4Research.
OWMM-Agent: Open World Mobile Manipulation With Multi-modal Agentic Data Synthesis
Jun 04, 2025The rapid progress of navigation, manipulation, and vision models has made mobile manipulators capable in many specialized tasks. However, the open-world mobile manipulation (OWMM) task remains a challenge due to the need for generalization to open-ended instructions and environments, as well as the systematic complexity to integrate high-level decision making with low-level robot control based on both global scene understanding and current agent state. To address this complexity, we propose a novel multi-modal agent architecture that maintains multi-view scene frames and agent states for decision-making and controls the robot by function calling. A second challenge is the hallucination from domain shift. To enhance the agent performance, we further introduce an agentic data synthesis pipeline for the OWMM task to adapt the VLM model to our task domain with instruction fine-tuning. We highlight our fine-tuned OWMM-VLM as the first dedicated foundation model for mobile manipulators with global scene understanding, robot state tracking, and multi-modal action generation in a unified model. Through experiments, we demonstrate that our model achieves SOTA performance compared to other foundation models including GPT-4o and strong zero-shot generalization in real world. The project page is at https://github.com/HHYHRHY/OWMM-Agent
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
X-WebAgentBench: A Multilingual Interactive Web Benchmark for Evaluating Global Agentic System
May 21, 2025Recently, large language model (LLM)-based agents have achieved significant success in interactive environments, attracting significant academic and industrial attention. Despite these advancements, current research predominantly focuses on English scenarios. In reality, there are over 7,000 languages worldwide, all of which demand access to comparable agentic services. Nevertheless, the development of language agents remains inadequate for meeting the diverse requirements of multilingual agentic applications. To fill this gap, we introduce X-WebAgentBench, a novel multilingual agent benchmark in an interactive web environment, which evaluates the planning and interaction performance of language agents across multiple languages, thereby contributing to the advancement of global agent intelligence. Additionally, we assess the performance of various LLMs and cross-lingual alignment methods, examining their effectiveness in enhancing agents. Our findings reveal that even advanced models like GPT-4o, when combined with cross-lingual techniques, fail to achieve satisfactory results. We hope that X-WebAgentBench can serve as a valuable benchmark for multilingual agent scenario in real-world applications.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.