 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPWEM: Non-Markovian Visuomotor Policy with Working and Episodic Memory
Mar 05, 2026Imitation learning from human demonstrations has achieved significant success in robotic control, yet most visuomotor policies still condition on single-step observations or short-context histories, making them struggle with non-Markovian tasks that require long-term memory. Simply enlarging the context window incurs substantial computational and memory costs and encourages overfitting to spurious correlations, leading to catastrophic failures under distribution shift and violating real-time constraints in robotic systems. By contrast, humans can compress important past experiences into long-term memories and exploit them to solve tasks throughout their lifetime. In this paper, we propose VPWEM, a non-Markovian visuomotor policy equipped with working and episodic memories. VPWEM retains a sliding window of recent observation tokens as short-term working memory, and introduces a Transformer-based contextual memory compressor that recursively converts out-of-window observations into a fixed number of episodic memory tokens. The compressor uses self-attention over a cache of past summary tokens and cross-attention over a cache of historical observations, and is trained jointly with the policy. We instantiate VPWEM on diffusion policies to exploit both short-term and episode-wide information for action generation with nearly constant memory and computation per step. Experiments demonstrate that VPWEM outperforms state-of-the-art baselines including diffusion policies and vision-language-action (VLA) models by more than 20% on the memory-intensive manipulation tasks in MIKASA and achieves an average 5% improvement on the mobile manipulation benchmark MoMaRT. Code is available at https://github.com/HarryLui98/code_vpwem.
Dynamic Mixture of Progressive Parameter-Efficient Expert Library for Lifelong Robot Learning
Jun 06, 2025A generalist agent must continuously learn and adapt throughout its lifetime, achieving efficient forward transfer while minimizing catastrophic forgetting. Previous work within the dominant pretrain-then-finetune paradigm has explored parameter-efficient fine-tuning for single-task adaptation, effectively steering a frozen pretrained model with a small number of parameters. However, in the context of lifelong learning, these methods rely on the impractical assumption of a test-time task identifier and restrict knowledge sharing among isolated adapters. To address these limitations, we propose Dynamic Mixture of Progressive Parameter-Efficient Expert Library (DMPEL) for lifelong robot learning. DMPEL progressively learn a low-rank expert library and employs a lightweight router to dynamically combine experts into an end-to-end policy, facilitating flexible behavior during lifelong adaptation. Moreover, by leveraging the modular structure of the fine-tuned parameters, we introduce coefficient replay to guide the router in accurately retrieving frozen experts for previously encountered tasks, thereby mitigating catastrophic forgetting. This method is significantly more storage- and computationally-efficient than applying demonstration replay to the entire policy. Extensive experiments on the lifelong manipulation benchmark LIBERO demonstrate that our framework outperforms state-of-the-art lifelong learning methods in success rates across continual adaptation, while utilizing minimal trainable parameters and storage.
Text2World: Benchmarking Large Language Models for Symbolic World Model Generation
Feb 18, 2025


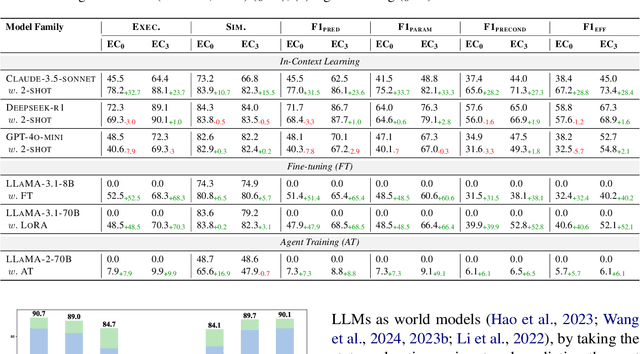
Recently, there has been growing interest in leveraging large language models (LLMs) to generate symbolic world models from textual descriptions. Although LLMs have been extensively explored in the context of world modeling, prior studies encountered several challenges, including evaluation randomness, dependence on indirect metrics, and a limited domain scope. To address these limitations, we introduce a novel benchmark, Text2World, based on planning domain definition language (PDDL), featuring hundreds of diverse domains and employing multi-criteria, execution-based metrics for a more robust evaluation. We benchmark current LLMs using Text2World and find that reasoning models trained with large-scale reinforcement learning outperform others. However, even the best-performing model still demonstrates limited capabilities in world modeling. Building on these insights, we examine several promising strategies to enhance the world modeling capabilities of LLMs, including test-time scaling, agent training, and more. We hope that Text2World can serve as a crucial resource, laying the groundwork for future research in leveraging LLMs as world models. The project page is available at https://text-to-world.github.io/.
FREA: Feasibility-Guided Generation of Safety-Critical Scenarios with Reasonable Adversariality
Jun 05, 2024



Generating safety-critical scenarios, which are essential yet difficult to collect at scale, offers an effective method to evaluate the robustness of autonomous vehicles (AVs). Existing methods focus on optimizing adversariality while preserving the naturalness of scenarios, aiming to achieve a balance through data-driven approaches. However, without an appropriate upper bound for adversariality, the scenarios might exhibit excessive adversariality, potentially leading to unavoidable collisions. In this paper, we introduce FREA, a novel safety-critical scenarios generation method that incorporates the Largest Feasible Region (LFR) of AV as guidance to ensure the reasonableness of the adversarial scenarios. Concretely, FREA initially pre-calculates the LFR of AV from offline datasets. Subsequently, it learns a reasonable adversarial policy that controls critical background vehicles (CBVs) in the scene to generate adversarial yet AV-feasible scenarios by maximizing a novel feasibility-dependent objective function. Extensive experiments illustrate that FREA can effectively generate safety-critical scenarios, yielding considerable near-miss events while ensuring AV's feasibility. Generalization analysis also confirms the robustness of FREA in AV testing across various surrogate AV methods and traffic environments.
Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning
Sep 11, 2022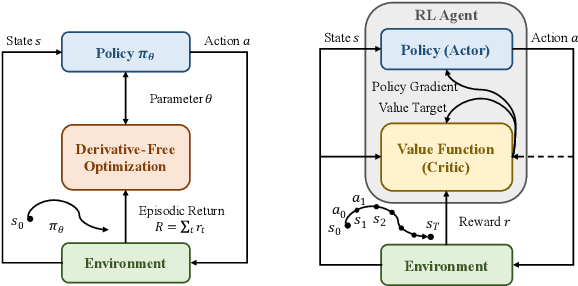
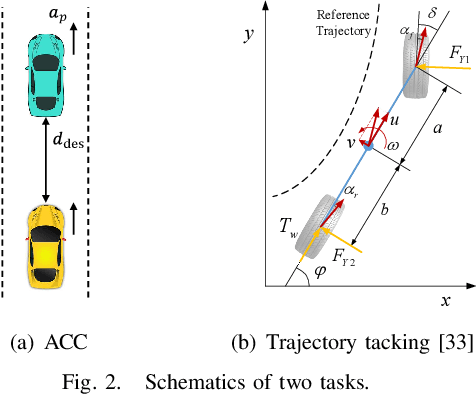
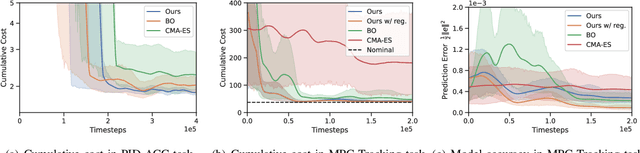
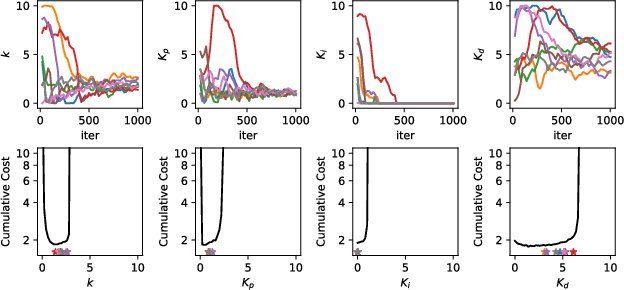
Choosing an appropriate parameter set for the designed controller is critical for the final performance but usually requires a tedious and careful tuning process, which implies a strong need for automatic tuning methods. However, among existing methods, derivative-free ones suffer from poor scalability or low efficiency, while gradient-based ones are often unavailable due to possibly non-differentiable controller structure. To resolve the issues, we tackle the controller tuning problem using a novel derivative-free reinforcement learning (RL) framework, which performs timestep-wise perturbation in parameter space during experience collection and integrates derivative-free policy updates into the advanced actor-critic RL architecture to achieve high versatility and efficiency. To demonstrate the framework's efficacy, we conduct numerical experiments on two concrete examples from autonomous driving, namely, adaptive cruise control with PID controller and trajectory tracking with MPC controller. Experimental results show that the proposed method outperforms popular baselines and highlight its strong potential for controller tuning.
Zeroth-Order Actor-Critic
Jan 29, 2022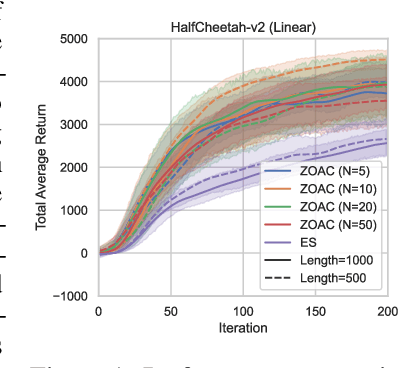

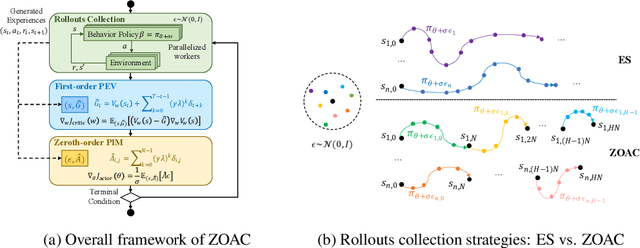
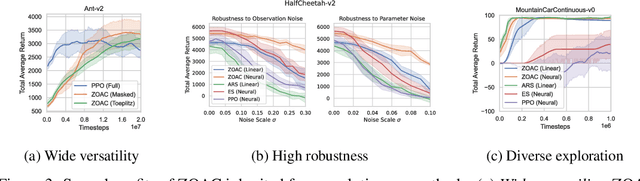
Zeroth-order optimization methods and policy gradient based first-order methods are two promising alternatives to solve reinforcement learning (RL) problems with complementary advantages. The former work with arbitrary policies, drive state-dependent and temporally-extended exploration, possess robustness-seeking property, but suffer from high sample complexity, while the latter are more sample efficient but restricted to differentiable policies and the learned policies are less robust. We propose Zeroth-Order Actor-Critic algorithm (ZOAC) that unifies these two methods into an on-policy actor-critic architecture to preserve the advantages from both. ZOAC conducts rollouts collection with timestep-wise perturbation in parameter space, first-order policy evaluation (PEV) and zeroth-order policy improvement (PIM) alternately in each iteration. We evaluate our proposed method on a range of challenging continuous control benchmarks using different types of policies, where ZOAC outperforms zeroth-order and first-order baseline algorithms.