 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Counterfactual-to-Interactive Reinforcement Fine-Tuning for Driving Policies
May 06, 2026Open-loop imitation learning has advanced modern autonomous driving policy architectures, but closed-loop deployment remains vulnerable to policy-induced distribution shift. Existing post-training paradigms exhibit fundamental trade-offs: closed-loop RL fine-tuning provides grounded feedback from executed actions but is constrained by the sparsity of informative events, whereas counterfactual fine-tuning provides dense supervision over candidate futures but inherits bias from imperfect future estimates. We introduce Counterfactual-to-Interactive Reinforcement Fine-Tuning (CRAFT), an on-policy framework that formulates closed-loop post-training as proxy-residual optimization. CRAFT uses group-normalized counterfactual advantages as a dense proxy for real closed-loop advantages and aligns this proxy with the closed-loop world through grounded residual correction from interaction-critical events. To stabilize adaptation, CRAFT regularizes the online policy toward an EMA teacher via asymmetric KL self-distillation. Theoretically, CRAFT decomposes the real closed-loop policy gradient into proxy and residual terms under the same visited-state distribution, reducing residual variance with an aligned proxy while mitigating proxy bias through grounded residual approximation. Empirically, CRAFT achieves the strongest closed-loop gains on Bench2Drive across hierarchical planning, vision-language-action, and vocabulary-scoring architectures. Ablations, scaling behavior, stability analyses, and transfer results further validate the complementary roles of dense counterfactual proxy and grounded residual correction. Project page: https://currychen77.github.io/CRAFT.
Driving risk emerges from the required two-dimensional joint evasive acceleration
Apr 20, 2026Most autonomous driving safety benchmarks use time-to-collision (TTC) to assess risk and guide safe behaviour. However, TTC-based methods treat risk as a one-dimensional closing problem, despite the inherently two-dimensional nature of collision avoidance, and therefore cannot faithfully capture risk or its evolution over time. Here, we report evasive acceleration (EA), a hyperparameter-free and physically interpretable two-dimensional paradigm for risk quantification. By evaluating all possible directions of collision avoidance, EA defines risk as the minimum magnitude of a constant relative acceleration vector required to alter the relative motion and make the interaction collision-free. Using interaction data from five open datasets and more than 600 real crashes, we derive percentile-based warning thresholds and show that EA provides the earliest statistically significant warning across all thresholds. Moreover, EA provides the best discrimination of eventual collision outcomes and improves information retention by 54.2-241.4% over all compared baselines. Adding EA to existing methods yields 17.5-95.5 times more information gain than adding existing methods to EA, indicating that EA captures much of the outcome-relevant information in existing methods while contributing substantial additional nonredundant information. Overall, EA better captures the structure of collision risk and provides a foundation for next-generation autonomous driving systems.
SparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving
Mar 31, 2026End-to-end multi-modal planning has been widely adopted to model the uncertainty of driving behavior, typically by scoring candidate trajectories and selecting the optimal one. Existing approaches generally fall into two categories: scoring a large static trajectory vocabulary, or scoring a small set of dynamically generated proposals. While static vocabularies often suffer from coarse discretization of the action space, dynamic proposals provide finer-grained precision and have shown stronger empirical performance on existing benchmarks. However, it remains unclear whether dynamic generation is fundamentally necessary, or whether static vocabularies can already achieve comparable performance when they are sufficiently dense to cover the action space. In this work, we start with a systematic scaling study of Hydra-MDP, a representative scoring-based method, revealing that performance consistently improves as trajectory anchors become denser, without exhibiting saturation before computational constraints are reached. Motivated by this observation, we propose SparseDriveV2 to push the performance boundary of scoring-based planning through two complementary innovations: (1) a scalable vocabulary representation with a factorized structure that decomposes trajectories into geometric paths and velocity profiles, enabling combinatorial coverage of the action space, and (2) a scalable scoring strategy with coarse factorized scoring over paths and velocity profiles followed by fine-grained scoring on a small set of composed trajectories. By combining these two techniques, SparseDriveV2 achieves 92.0 PDMS and 90.1 EPDMS on NAVSIM, with 89.15 Driving Score and 70.00 Success Rate on Bench2Drive with a lightweight ResNet-34 as backbone. Code and model are released at https://github.com/swc-17/SparseDriveV2.
ForSim: Stepwise Forward Simulation for Traffic Policy Fine-Tuning
Feb 02, 2026As the foundation of closed-loop training and evaluation in autonomous driving, traffic simulation still faces two fundamental challenges: covariate shift introduced by open-loop imitation learning and limited capacity to reflect the multimodal behaviors observed in real-world traffic. Although recent frameworks such as RIFT have partially addressed these issues through group-relative optimization, their forward simulation procedures remain largely non-reactive, leading to unrealistic agent interactions within the virtual domain and ultimately limiting simulation fidelity. To address these issues, we propose ForSim, a stepwise closed-loop forward simulation paradigm. At each virtual timestep, the traffic agent propagates the virtual candidate trajectory that best spatiotemporally matches the reference trajectory through physically grounded motion dynamics, thereby preserving multimodal behavioral diversity while ensuring intra-modality consistency. Other agents are updated with stepwise predictions, yielding coherent and interaction-aware evolution. When incorporated into the RIFT traffic simulation framework, ForSim operates in conjunction with group-relative optimization to fine-tune traffic policy. Extensive experiments confirm that this integration consistently improves safety while maintaining efficiency, realism, and comfort. These results underscore the importance of modeling closed-loop multimodal interactions within forward simulation and enhance the fidelity and reliability of traffic simulation for autonomous driving. Project Page: https://currychen77.github.io/ForSim/
Listen, Look, Drive: Coupling Audio Instructions for User-aware VLA-based Autonomous Driving
Jan 17, 2026Vision Language Action (VLA) models promise an open-vocabulary interface that can translate perceptual ambiguity into semantically grounded driving decisions, yet they still treat language as a static prior fixed at inference time. As a result, the model must infer continuously shifting objectives from pixels alone, yielding delayed or overly conservative maneuvers. We argue that effective VLAs for autonomous driving need an online channel in which users can influence driving with specific intentions. To this end, we present EchoVLA, a user-aware VLA that couples camera streams with in situ audio instructions. We augment the nuScenes dataset with temporally aligned, intent-specific speech commands generated by converting ego-motion descriptions into synthetic audios. Further, we compose emotional speech-trajectory pairs into a multimodal Chain-of-Thought (CoT) for fine-tuning a Multimodal Large Model (MLM) based on Qwen2.5-Omni. Specifically, we synthesize the audio-augmented dataset with different emotion types paired with corresponding driving behaviors, leveraging the emotional cues embedded in tone, pitch, and speech tempo to reflect varying user states, such as urgent or hesitant intentions, thus enabling our EchoVLA to interpret not only the semantic content but also the emotional context of audio commands for more nuanced and emotionally adaptive driving behavior. In open-loop benchmarks, our approach reduces the average L2 error by $59.4\%$ and the collision rate by $74.4\%$ compared to the baseline of vision-only perception. More experiments on nuScenes dataset validate that EchoVLA not only steers the trajectory through audio instructions, but also modulates driving behavior in response to the emotions detected in the user's speech.
Modified-Emergency Index (MEI): A Criticality Metric for Autonomous Driving in Lateral Conflict
Oct 31, 2025Effective, reliable, and efficient evaluation of autonomous driving safety is essential to demonstrate its trustworthiness. Criticality metrics provide an objective means of assessing safety. However, as existing metrics primarily target longitudinal conflicts, accurately quantifying the risks of lateral conflicts - prevalent in urban settings - remains challenging. This paper proposes the Modified-Emergency Index (MEI), a metric designed to quantify evasive effort in lateral conflicts. Compared to the original Emergency Index (EI), MEI refines the estimation of the time available for evasive maneuvers, enabling more precise risk quantification. We validate MEI on a public lateral conflict dataset based on Argoverse-2, from which we extract over 1,500 high-quality AV conflict cases, including more than 500 critical events. MEI is then compared with the well-established ACT and the widely used PET metrics. Results show that MEI consistently outperforms them in accurately quantifying criticality and capturing risk evolution. Overall, these findings highlight MEI as a promising metric for evaluating urban conflicts and enhancing the safety assessment framework for autonomous driving. The open-source implementation is available at https://github.com/AutoChengh/MEI.
DriveCamSim: Generalizable Camera Simulation via Explicit Camera Modeling for Autonomous Driving
May 26, 2025Camera sensor simulation serves as a critical role for autonomous driving (AD), e.g. evaluating vision-based AD algorithms. While existing approaches have leveraged generative models for controllable image/video generation, they remain constrained to generating multi-view video sequences with fixed camera viewpoints and video frequency, significantly limiting their downstream applications. To address this, we present a generalizable camera simulation framework DriveCamSim, whose core innovation lies in the proposed Explicit Camera Modeling (ECM) mechanism. Instead of implicit interaction through vanilla attention, ECM establishes explicit pixel-wise correspondences across multi-view and multi-frame dimensions, decoupling the model from overfitting to the specific camera configurations (intrinsic/extrinsic parameters, number of views) and temporal sampling rates presented in the training data. For controllable generation, we identify the issue of information loss inherent in existing conditional encoding and injection pipelines, proposing an information-preserving control mechanism. This control mechanism not only improves conditional controllability, but also can be extended to be identity-aware to enhance temporal consistency in foreground object rendering. With above designs, our model demonstrates superior performance in both visual quality and controllability, as well as generalization capability across spatial-level (camera parameters variations) and temporal-level (video frame rate variations), enabling flexible user-customizable camera simulation tailored to diverse application scenarios. Code will be avaliable at https://github.com/swc-17/DriveCamSim for facilitating future research.
RIFT: Closed-Loop RL Fine-Tuning for Realistic and Controllable Traffic Simulation
May 06, 2025



Achieving both realism and controllability in interactive closed-loop traffic simulation remains a key challenge in autonomous driving. Data-driven simulation methods reproduce realistic trajectories but suffer from covariate shift in closed-loop deployment, compounded by simplified dynamics models that further reduce reliability. Conversely, physics-based simulation methods enhance reliable and controllable closed-loop interactions but often lack expert demonstrations, compromising realism. To address these challenges, we introduce a dual-stage AV-centered simulation framework that conducts open-loop imitation learning pre-training in a data-driven simulator to capture trajectory-level realism and multimodality, followed by closed-loop reinforcement learning fine-tuning in a physics-based simulator to enhance controllability and mitigate covariate shift. In the fine-tuning stage, we propose RIFT, a simple yet effective closed-loop RL fine-tuning strategy that preserves the trajectory-level multimodality through a GRPO-style group-relative advantage formulation, while enhancing controllability and training stability by replacing KL regularization with the dual-clip mechanism. Extensive experiments demonstrate that RIFT significantly improves the realism and controllability of generated traffic scenarios, providing a robust platform for evaluating autonomous vehicle performance in diverse and interactive scenarios.
Passenger hazard perception based on EEG signals for highly automated driving vehicles
Aug 29, 2024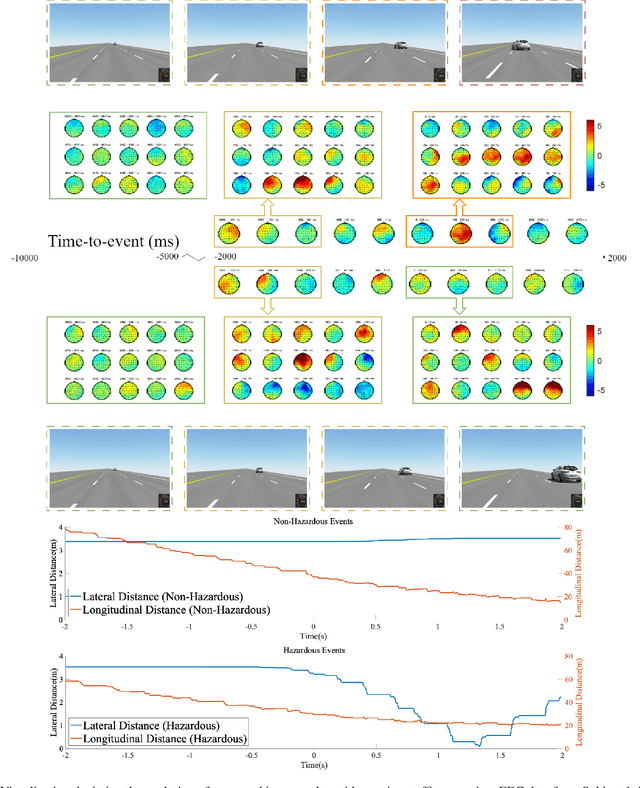
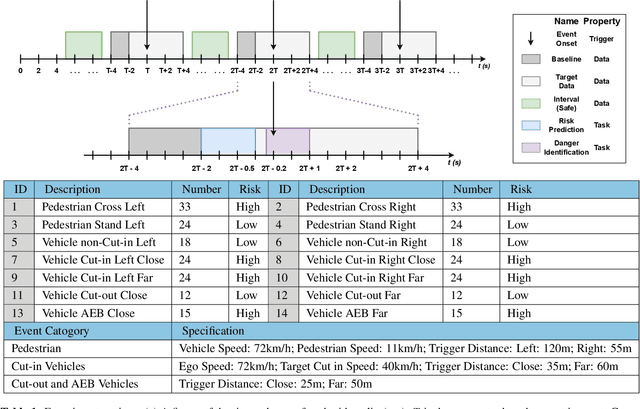
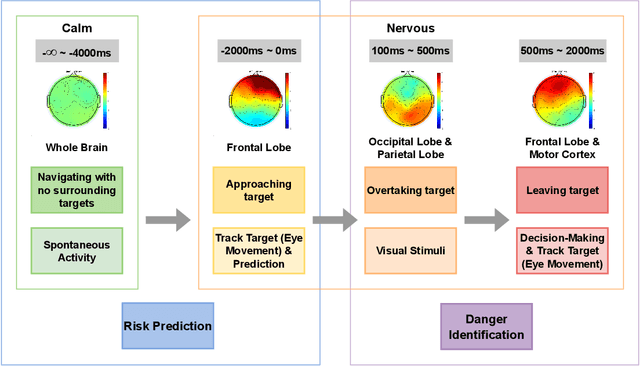
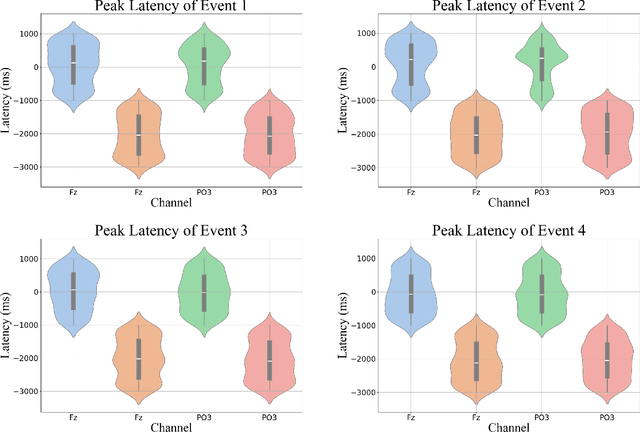
Enhancing the safety of autonomous vehicles is crucial, especially given recent accidents involving automated systems. As passengers in these vehicles, humans' sensory perception and decision-making can be integrated with autonomous systems to improve safety. This study explores neural mechanisms in passenger-vehicle interactions, leading to the development of a Passenger Cognitive Model (PCM) and the Passenger EEG Decoding Strategy (PEDS). Central to PEDS is a novel Convolutional Recurrent Neural Network (CRNN) that captures spatial and temporal EEG data patterns. The CRNN, combined with stacking algorithms, achieves an accuracy of $85.0\% \pm 3.18\%$. Our findings highlight the predictive power of pre-event EEG data, enhancing the detection of hazardous scenarios and offering a network-driven framework for safer autonomous vehicles.
FREA: Feasibility-Guided Generation of Safety-Critical Scenarios with Reasonable Adversariality
Jun 05, 2024



Generating safety-critical scenarios, which are essential yet difficult to collect at scale, offers an effective method to evaluate the robustness of autonomous vehicles (AVs). Existing methods focus on optimizing adversariality while preserving the naturalness of scenarios, aiming to achieve a balance through data-driven approaches. However, without an appropriate upper bound for adversariality, the scenarios might exhibit excessive adversariality, potentially leading to unavoidable collisions. In this paper, we introduce FREA, a novel safety-critical scenarios generation method that incorporates the Largest Feasible Region (LFR) of AV as guidance to ensure the reasonableness of the adversarial scenarios. Concretely, FREA initially pre-calculates the LFR of AV from offline datasets. Subsequently, it learns a reasonable adversarial policy that controls critical background vehicles (CBVs) in the scene to generate adversarial yet AV-feasible scenarios by maximizing a novel feasibility-dependent objective function. Extensive experiments illustrate that FREA can effectively generate safety-critical scenarios, yielding considerable near-miss events while ensuring AV's feasibility. Generalization analysis also confirms the robustness of FREA in AV testing across various surrogate AV methods and traffic environments.