 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving
Mar 31, 2026End-to-end multi-modal planning has been widely adopted to model the uncertainty of driving behavior, typically by scoring candidate trajectories and selecting the optimal one. Existing approaches generally fall into two categories: scoring a large static trajectory vocabulary, or scoring a small set of dynamically generated proposals. While static vocabularies often suffer from coarse discretization of the action space, dynamic proposals provide finer-grained precision and have shown stronger empirical performance on existing benchmarks. However, it remains unclear whether dynamic generation is fundamentally necessary, or whether static vocabularies can already achieve comparable performance when they are sufficiently dense to cover the action space. In this work, we start with a systematic scaling study of Hydra-MDP, a representative scoring-based method, revealing that performance consistently improves as trajectory anchors become denser, without exhibiting saturation before computational constraints are reached. Motivated by this observation, we propose SparseDriveV2 to push the performance boundary of scoring-based planning through two complementary innovations: (1) a scalable vocabulary representation with a factorized structure that decomposes trajectories into geometric paths and velocity profiles, enabling combinatorial coverage of the action space, and (2) a scalable scoring strategy with coarse factorized scoring over paths and velocity profiles followed by fine-grained scoring on a small set of composed trajectories. By combining these two techniques, SparseDriveV2 achieves 92.0 PDMS and 90.1 EPDMS on NAVSIM, with 89.15 Driving Score and 70.00 Success Rate on Bench2Drive with a lightweight ResNet-34 as backbone. Code and model are released at https://github.com/swc-17/SparseDriveV2.
HoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
DriveCamSim: Generalizable Camera Simulation via Explicit Camera Modeling for Autonomous Driving
May 26, 2025Camera sensor simulation serves as a critical role for autonomous driving (AD), e.g. evaluating vision-based AD algorithms. While existing approaches have leveraged generative models for controllable image/video generation, they remain constrained to generating multi-view video sequences with fixed camera viewpoints and video frequency, significantly limiting their downstream applications. To address this, we present a generalizable camera simulation framework DriveCamSim, whose core innovation lies in the proposed Explicit Camera Modeling (ECM) mechanism. Instead of implicit interaction through vanilla attention, ECM establishes explicit pixel-wise correspondences across multi-view and multi-frame dimensions, decoupling the model from overfitting to the specific camera configurations (intrinsic/extrinsic parameters, number of views) and temporal sampling rates presented in the training data. For controllable generation, we identify the issue of information loss inherent in existing conditional encoding and injection pipelines, proposing an information-preserving control mechanism. This control mechanism not only improves conditional controllability, but also can be extended to be identity-aware to enhance temporal consistency in foreground object rendering. With above designs, our model demonstrates superior performance in both visual quality and controllability, as well as generalization capability across spatial-level (camera parameters variations) and temporal-level (video frame rate variations), enabling flexible user-customizable camera simulation tailored to diverse application scenarios. Code will be avaliable at https://github.com/swc-17/DriveCamSim for facilitating future research.
SEM: Enhancing Spatial Understanding for Robust Robot Manipulation
May 22, 2025A key challenge in robot manipulation lies in developing policy models with strong spatial understanding, the ability to reason about 3D geometry, object relations, and robot embodiment. Existing methods often fall short: 3D point cloud models lack semantic abstraction, while 2D image encoders struggle with spatial reasoning. To address this, we propose SEM (Spatial Enhanced Manipulation model), a novel diffusion-based policy framework that explicitly enhances spatial understanding from two complementary perspectives. A spatial enhancer augments visual representations with 3D geometric context, while a robot state encoder captures embodiment-aware structure through graphbased modeling of joint dependencies. By integrating these modules, SEM significantly improves spatial understanding, leading to robust and generalizable manipulation across diverse tasks that outperform existing baselines.
Revisit Mixture Models for Multi-Agent Simulation: Experimental Study within a Unified Framework
Jan 28, 2025



Simulation plays a crucial role in assessing autonomous driving systems, where the generation of realistic multi-agent behaviors is a key aspect. In multi-agent simulation, the primary challenges include behavioral multimodality and closed-loop distributional shifts. In this study, we revisit mixture models for generating multimodal agent behaviors, which can cover the mainstream methods including continuous mixture models and GPT-like discrete models. Furthermore, we introduce a closed-loop sample generation approach tailored for mixture models to mitigate distributional shifts. Within the unified mixture model~(UniMM) framework, we recognize critical configurations from both model and data perspectives. We conduct a systematic examination of various model configurations, including positive component matching, continuous regression, prediction horizon, and the number of components. Moreover, our investigation into the data configuration highlights the pivotal role of closed-loop samples in achieving realistic simulations. To extend the benefits of closed-loop samples across a broader range of mixture models, we further address the shortcut learning and off-policy learning issues. Leveraging insights from our exploration, the distinct variants proposed within the UniMM framework, including discrete, anchor-free, and anchor-based models, all achieve state-of-the-art performance on the WOSAC benchmark.
BIP3D: Bridging 2D Images and 3D Perception for Embodied Intelligence
Nov 22, 2024



In embodied intelligence systems, a key component is 3D perception algorithm, which enables agents to understand their surrounding environments. Previous algorithms primarily rely on point cloud, which, despite offering precise geometric information, still constrain perception performance due to inherent sparsity, noise, and data scarcity. In this work, we introduce a novel image-centric 3D perception model, BIP3D, which leverages expressive image features with explicit 3D position encoding to overcome the limitations of point-centric methods. Specifically, we leverage pre-trained 2D vision foundation models to enhance semantic understanding, and introduce a spatial enhancer module to improve spatial understanding. Together, these modules enable BIP3D to achieve multi-view, multi-modal feature fusion and end-to-end 3D perception. In our experiments, BIP3D outperforms current state-of-the-art results on the EmbodiedScan benchmark, achieving improvements of 5.69% in the 3D detection task and 15.25% in the 3D visual grounding task.
SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation
May 31, 2024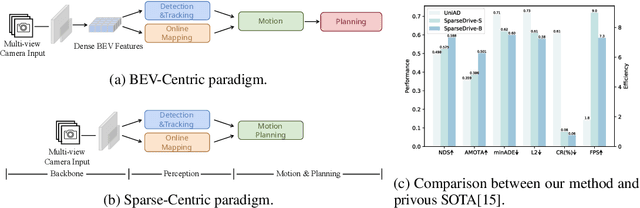
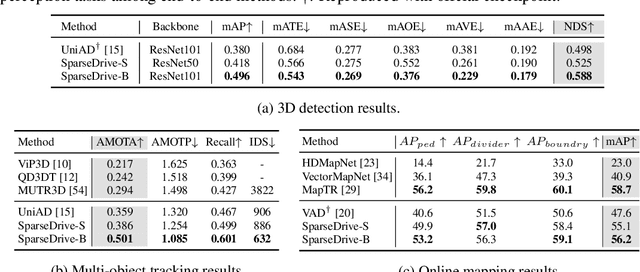
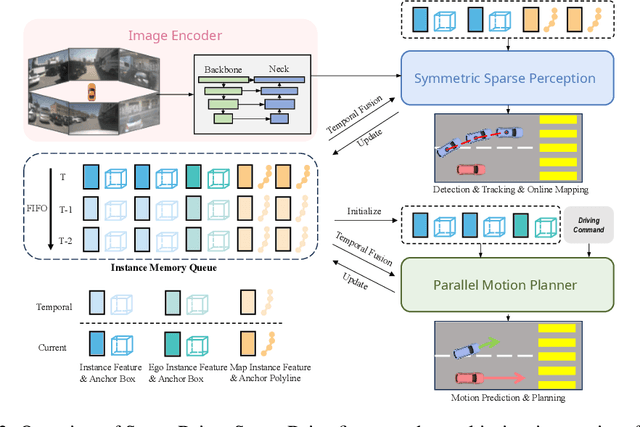
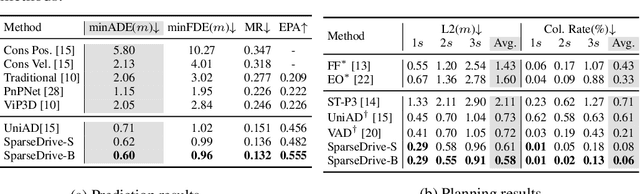
The well-established modular autonomous driving system is decoupled into different standalone tasks, e.g. perception, prediction and planning, suffering from information loss and error accumulation across modules. In contrast, end-to-end paradigms unify multi-tasks into a fully differentiable framework, allowing for optimization in a planning-oriented spirit. Despite the great potential of end-to-end paradigms, both the performance and efficiency of existing methods are not satisfactory, particularly in terms of planning safety. We attribute this to the computationally expensive BEV (bird's eye view) features and the straightforward design for prediction and planning. To this end, we explore the sparse representation and review the task design for end-to-end autonomous driving, proposing a new paradigm named SparseDrive. Concretely, SparseDrive consists of a symmetric sparse perception module and a parallel motion planner. The sparse perception module unifies detection, tracking and online mapping with a symmetric model architecture, learning a fully sparse representation of the driving scene. For motion prediction and planning, we review the great similarity between these two tasks, leading to a parallel design for motion planner. Based on this parallel design, which models planning as a multi-modal problem, we propose a hierarchical planning selection strategy , which incorporates a collision-aware rescore module, to select a rational and safe trajectory as the final planning output. With such effective designs, SparseDrive surpasses previous state-of-the-arts by a large margin in performance of all tasks, while achieving much higher training and inference efficiency. Code will be avaliable at https://github.com/swc-17/SparseDrive for facilitating future research.
EDA: Evolving and Distinct Anchors for Multimodal Motion Prediction
Dec 15, 2023



Motion prediction is a crucial task in autonomous driving, and one of its major challenges lands in the multimodality of future behaviors. Many successful works have utilized mixture models which require identification of positive mixture components, and correspondingly fall into two main lines: prediction-based and anchor-based matching. The prediction clustering phenomenon in prediction-based matching makes it difficult to pick representative trajectories for downstream tasks, while the anchor-based matching suffers from a limited regression capability. In this paper, we introduce a novel paradigm, named Evolving and Distinct Anchors (EDA), to define the positive and negative components for multimodal motion prediction based on mixture models. We enable anchors to evolve and redistribute themselves under specific scenes for an enlarged regression capacity. Furthermore, we select distinct anchors before matching them with the ground truth, which results in impressive scoring performance. Our approach enhances all metrics compared to the baseline MTR, particularly with a notable relative reduction of 13.5% in Miss Rate, resulting in state-of-the-art performance on the Waymo Open Motion Dataset. Code is available at https://github.com/Longzhong-Lin/EDA.
Sparse4D v3: Advancing End-to-End 3D Detection and Tracking
Nov 20, 2023



In autonomous driving perception systems, 3D detection and tracking are the two fundamental tasks. This paper delves deeper into this field, building upon the Sparse4D framework. We introduce two auxiliary training tasks (Temporal Instance Denoising and Quality Estimation) and propose decoupled attention to make structural improvements, leading to significant enhancements in detection performance. Additionally, we extend the detector into a tracker using a straightforward approach that assigns instance ID during inference, further highlighting the advantages of query-based algorithms. Extensive experiments conducted on the nuScenes benchmark validate the effectiveness of the proposed improvements. With ResNet50 as the backbone, we witnessed enhancements of 3.0\%, 2.2\%, and 7.6\% in mAP, NDS, and AMOTA, achieving 46.9\%, 56.1\%, and 49.0\%, respectively. Our best model achieved 71.9\% NDS and 67.7\% AMOTA on the nuScenes test set. Code will be released at \url{https://github.com/linxuewu/Sparse4D}.
Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
May 24, 2023



Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.