 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
Jun 10, 2026Vision-Language-Action (VLA) models that couple pretrained Vision-Language Models (VLMs) with continuous action experts have achieved strong manipulation performance, yet generalization to out-of-distribution (OOD) language instructions remains poor. A known challenge is the structural imbalance in VLA data, where language is far less diverse than visual and action content, making policies prone to visual shortcuts. While discrete-action methods mitigate this through vision-language co-training, continuous action experts lack such protection: they start from random initialization and learn entirely from imbalanced data, producing noisy gradients that corrupt the VLM and fail to exploit its language capability. We address this from a Bayesian perspective, factorizing the policy into a language-agnostic Vision-Action (VA) prior and a language-conditioned VLA likelihood, and propose APT, a two-stage training method emphasizing Action expert PreTraining. In Stage 1, the action expert is pretrained as a VA prior on vision-action pairs from a frozen VLM, bypassing the language imbalance. In Stage 2, language tokens are injected through a gated fusion mechanism that integrates VLM features while preserving the learned visuomotor prior. APT applies to mainstream VLA architectures, including the $π$ and GR00T-style architectures. Comprehensive experiments validate that APT achieves consistent gains on unseen instructions and compositional tasks. Project Page: https://xukechun.github.io/papers/APT/
Direction Matters: Learning Force Direction Enables Sim-to-Real Contact-Rich Manipulation
Feb 15, 2026Sim-to-real transfer for contact-rich manipulation remains challenging due to the inherent discrepancy in contact dynamics. While existing methods often rely on costly real-world data or utilize blind compliance through fixed controllers, we propose a framework that leverages expert-designed controller logic for transfer. Inspired by the success of privileged supervision in kinematic tasks, we employ a human-designed finite state machine based position/force controller in simulation to provide privileged guidance. The resulting policy is trained to predict the end-effector pose, contact state, and crucially the desired contact force direction. Unlike force magnitudes, which are highly sensitive to simulation inaccuracies, force directions encode high-level task geometry and remain robust across the sim-to-real gap. At deployment, these predictions configure a force-aware admittance controller. By combining the policy's directional intent with a constant, low-cost manually tuned force magnitude, the system generates adaptive, task-aligned compliance. This tuning is lightweight, typically requiring only a single scalar per contact state. We provide theoretical analysis for stability and robustness to disturbances. Experiments on four real-world tasks, i.e., microwave opening, peg-in-hole, whiteboard wiping, and door opening, demonstrate that our approach significantly outperforms strong baselines in both success rate and robustness. Videos are available at: https://yifei-y.github.io/project-pages/DirectionMatters/.
Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
Dec 12, 2025The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.
Toward Embodiment Equivariant Vision-Language-Action Policy
Sep 18, 2025Vision-language-action policies learn manipulation skills across tasks, environments and embodiments through large-scale pre-training. However, their ability to generalize to novel robot configurations remains limited. Most approaches emphasize model size, dataset scale and diversity while paying less attention to the design of action spaces. This leads to the configuration generalization problem, which requires costly adaptation. We address this challenge by formulating cross-embodiment pre-training as designing policies equivariant to embodiment configuration transformations. Building on this principle, we propose a framework that (i) establishes a embodiment equivariance theory for action space and policy design, (ii) introduces an action decoder that enforces configuration equivariance, and (iii) incorporates a geometry-aware network architecture to enhance embodiment-agnostic spatial reasoning. Extensive experiments in both simulation and real-world settings demonstrate that our approach improves pre-training effectiveness and enables efficient fine-tuning on novel robot embodiments. Our code is available at https://github.com/hhcaz/e2vla
Grounding 3D Object Affordance with Language Instructions, Visual Observations and Interactions
Apr 07, 2025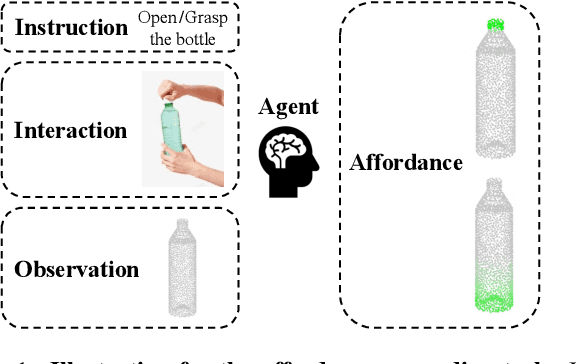

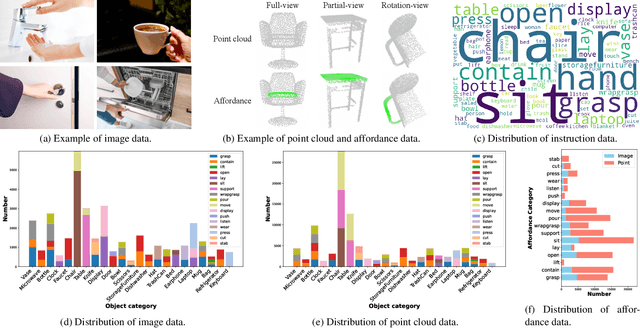

Grounding 3D object affordance is a task that locates objects in 3D space where they can be manipulated, which links perception and action for embodied intelligence. For example, for an intelligent robot, it is necessary to accurately ground the affordance of an object and grasp it according to human instructions. In this paper, we introduce a novel task that grounds 3D object affordance based on language instructions, visual observations and interactions, which is inspired by cognitive science. We collect an Affordance Grounding dataset with Points, Images and Language instructions (AGPIL) to support the proposed task. In the 3D physical world, due to observation orientation, object rotation, or spatial occlusion, we can only get a partial observation of the object. So this dataset includes affordance estimations of objects from full-view, partial-view, and rotation-view perspectives. To accomplish this task, we propose LMAffordance3D, the first multi-modal, language-guided 3D affordance grounding network, which applies a vision-language model to fuse 2D and 3D spatial features with semantic features. Comprehensive experiments on AGPIL demonstrate the effectiveness and superiority of our method on this task, even in unseen experimental settings. Our project is available at https://sites.google.com/view/lmaffordance3d.
Efficient Alignment of Unconditioned Action Prior for Language-conditioned Pick and Place in Clutter
Mar 12, 2025We study the task of language-conditioned pick and place in clutter, where a robot should grasp a target object in open clutter and move it to a specified place. Some approaches learn end-to-end policies with features from vision foundation models, requiring large datasets. Others combine foundation models in a zero-shot setting, suffering from cascading errors. In addition, they primarily leverage vision and language foundation models, focusing less on action priors. In this paper, we aim to develop an effective policy by integrating foundation priors from vision, language, and action. We propose A$^2$, an action prior alignment method that aligns unconditioned action priors with 3D vision-language priors by learning one attention layer. The alignment formulation enables our policy to train with less data and preserve zero-shot generalization capabilities. We show that a shared policy for both pick and place actions enhances the performance for each task, and introduce a policy adaptation scheme to accommodate the multi-modal nature of actions. Extensive experiments in simulation and the real-world show that our policy achieves higher task success rates with fewer steps for both pick and place tasks in clutter, effectively generalizing to unseen objects and language instructions.
Revisit Mixture Models for Multi-Agent Simulation: Experimental Study within a Unified Framework
Jan 28, 2025



Simulation plays a crucial role in assessing autonomous driving systems, where the generation of realistic multi-agent behaviors is a key aspect. In multi-agent simulation, the primary challenges include behavioral multimodality and closed-loop distributional shifts. In this study, we revisit mixture models for generating multimodal agent behaviors, which can cover the mainstream methods including continuous mixture models and GPT-like discrete models. Furthermore, we introduce a closed-loop sample generation approach tailored for mixture models to mitigate distributional shifts. Within the unified mixture model~(UniMM) framework, we recognize critical configurations from both model and data perspectives. We conduct a systematic examination of various model configurations, including positive component matching, continuous regression, prediction horizon, and the number of components. Moreover, our investigation into the data configuration highlights the pivotal role of closed-loop samples in achieving realistic simulations. To extend the benefits of closed-loop samples across a broader range of mixture models, we further address the shortcut learning and off-policy learning issues. Leveraging insights from our exploration, the distinct variants proposed within the UniMM framework, including discrete, anchor-free, and anchor-based models, all achieve state-of-the-art performance on the WOSAC benchmark.
Grasp, See and Place: Efficient Unknown Object Rearrangement with Policy Structure Prior
Feb 23, 2024



We focus on the task of unknown object rearrangement, where a robot is supposed to re-configure the objects into a desired goal configuration specified by an RGB-D image. Recent works explore unknown object rearrangement systems by incorporating learning-based perception modules. However, they are sensitive to perception error, and pay less attention to task-level performance. In this paper, we aim to develop an effective system for unknown object rearrangement amidst perception noise. We theoretically reveal the noisy perception impacts grasp and place in a decoupled way, and show such a decoupled structure is non-trivial to improve task optimality. We propose GSP, a dual-loop system with the decoupled structure as prior. For the inner loop, we learn an active seeing policy for self-confident object matching to improve the perception of place. For the outer loop, we learn a grasp policy aware of object matching and grasp capability guided by task-level rewards. We leverage the foundation model CLIP for object matching, policy learning and self-termination. A series of experiments indicate that GSP can conduct unknown object rearrangement with higher completion rate and less steps.
A Hyper-network Based End-to-end Visual Servoing with Arbitrary Desired Poses
Apr 18, 2023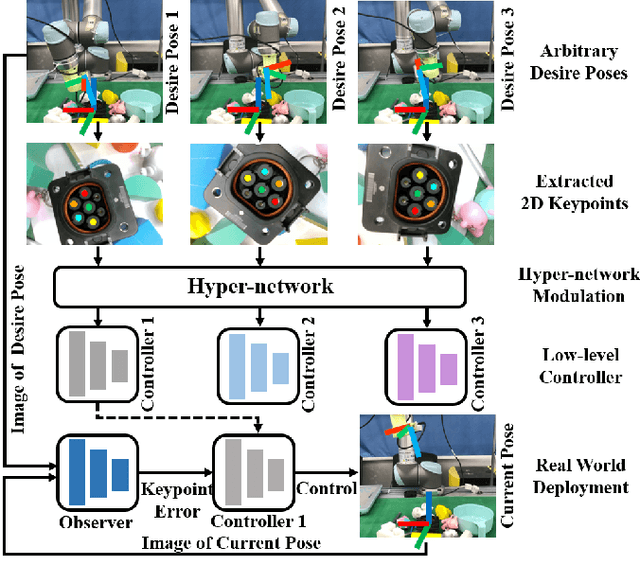
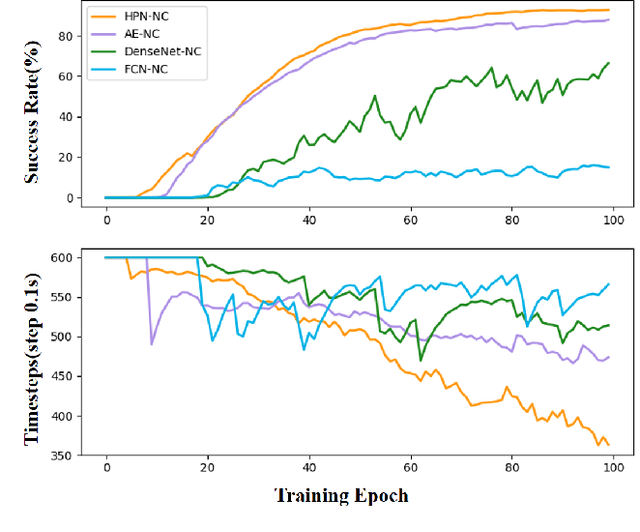
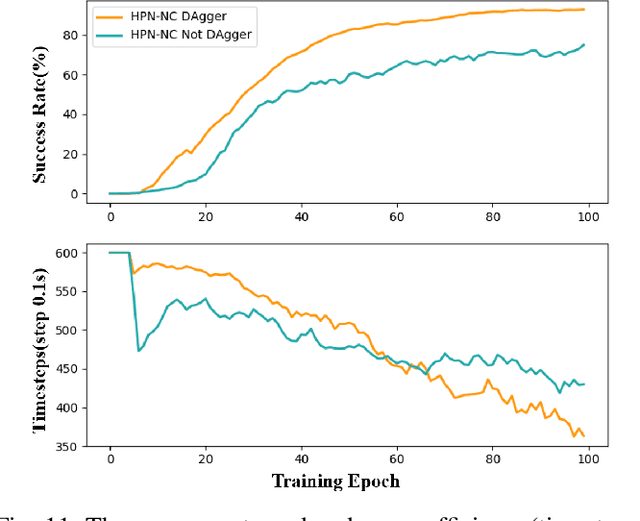
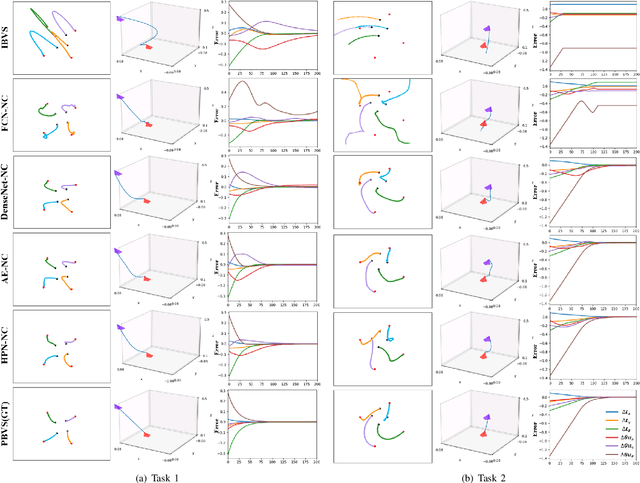
Recently, several works achieve end-to-end visual servoing (VS) for robotic manipulation by replacing traditional controller with differentiable neural networks, but lose the ability to servo arbitrary desired poses. This letter proposes a differentiable architecture for arbitrary pose servoing: a hyper-network based neural controller (HPN-NC). To achieve this, HPN-NC consists of a hyper net and a low-level controller, where the hyper net learns to generate the parameters of the low-level controller and the controller uses the 2D keypoints error for control like traditional image-based visual servoing (IBVS). HPN-NC can complete 6 degree of freedom visual servoing with large initial offset. Taking advantage of the fully differentiable nature of HPN-NC, we provide a three-stage training procedure to servo real world objects. With self-supervised end-to-end training, the performance of the integrated model can be further improved in unseen scenes and the amount of manual annotations can be significantly reduced.
Object-centric Inference for Language Conditioned Placement: A Foundation Model based Approach
Apr 06, 2023



We focus on the task of language-conditioned object placement, in which a robot should generate placements that satisfy all the spatial relational constraints in language instructions. Previous works based on rule-based language parsing or scene-centric visual representation have restrictions on the form of instructions and reference objects or require large amounts of training data. We propose an object-centric framework that leverages foundation models to ground the reference objects and spatial relations for placement, which is more sample efficient and generalizable. Experiments indicate that our model can achieve a 97.75% success rate of placement with only ~0.26M trainable parameters. Besides, our method generalizes better to both unseen objects and instructions. Moreover, with only 25% training data, we still outperform the top competing approach.