 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoloBrain-0 Technical Report
Feb 12, 2026In this work, we introduce HoloBrain-0, a comprehensive Vision-Language-Action (VLA) framework that bridges the gap between foundation model research and reliable real-world robot deployment. The core of our system is a novel VLA architecture that explicitly incorporates robot embodiment priors, including multi-view camera parameters and kinematic descriptions (URDF), to enhance 3D spatial reasoning and support diverse embodiments. We validate this design through a scalable ``pre-train then post-train" paradigm, achieving state-of-the-art results on simulation benchmarks such as RoboTwin 2.0, LIBERO, and GenieSim, as well as strong results on challenging long-horizon real-world manipulation tasks. Notably, our efficient 0.2B-parameter variant rivals significantly larger baselines, enabling low-latency on-device deployment. To further accelerate research and practical adoption, we fully open-source the entire HoloBrain ecosystem, which includes: (1) powerful pre-trained VLA foundations; (2) post-trained checkpoints for multiple simulation suites and real-world tasks; and (3) RoboOrchard, a full-stack VLA infrastructure for data curation, model training and deployment. Together with standardized data collection protocols, this release provides the community with a complete, reproducible path toward high-performance robotic manipulation.
DIPO: Dual-State Images Controlled Articulated Object Generation Powered by Diverse Data
May 28, 2025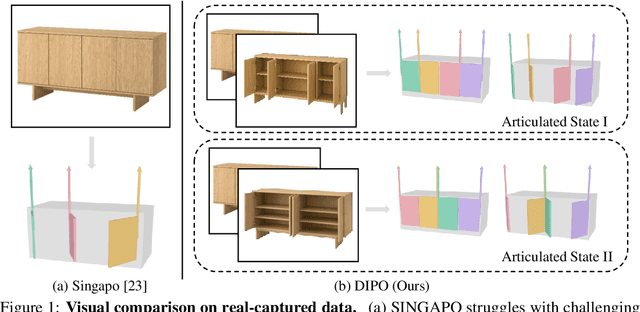
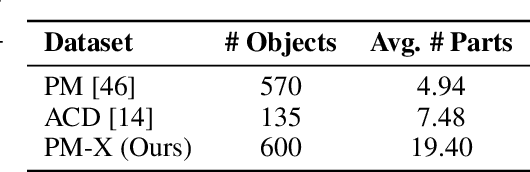
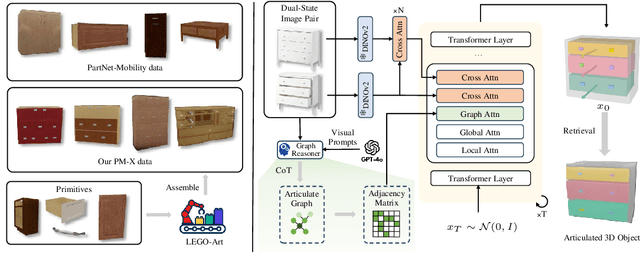
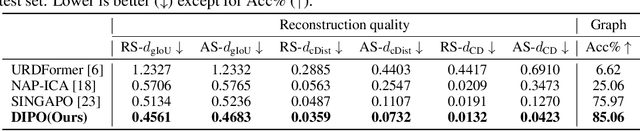
We present DIPO, a novel framework for the controllable generation of articulated 3D objects from a pair of images: one depicting the object in a resting state and the other in an articulated state. Compared to the single-image approach, our dual-image input imposes only a modest overhead for data collection, but at the same time provides important motion information, which is a reliable guide for predicting kinematic relationships between parts. Specifically, we propose a dual-image diffusion model that captures relationships between the image pair to generate part layouts and joint parameters. In addition, we introduce a Chain-of-Thought (CoT) based graph reasoner that explicitly infers part connectivity relationships. To further improve robustness and generalization on complex articulated objects, we develop a fully automated dataset expansion pipeline, name LEGO-Art, that enriches the diversity and complexity of PartNet-Mobility dataset. We propose PM-X, a large-scale dataset of complex articulated 3D objects, accompanied by rendered images, URDF annotations, and textual descriptions. Extensive experiments demonstrate that DIPO significantly outperforms existing baselines in both the resting state and the articulated state, while the proposed PM-X dataset further enhances generalization to diverse and structurally complex articulated objects. Our code and dataset will be released to the community upon publication.
SEM: Enhancing Spatial Understanding for Robust Robot Manipulation
May 22, 2025A key challenge in robot manipulation lies in developing policy models with strong spatial understanding, the ability to reason about 3D geometry, object relations, and robot embodiment. Existing methods often fall short: 3D point cloud models lack semantic abstraction, while 2D image encoders struggle with spatial reasoning. To address this, we propose SEM (Spatial Enhanced Manipulation model), a novel diffusion-based policy framework that explicitly enhances spatial understanding from two complementary perspectives. A spatial enhancer augments visual representations with 3D geometric context, while a robot state encoder captures embodiment-aware structure through graphbased modeling of joint dependencies. By integrating these modules, SEM significantly improves spatial understanding, leading to robust and generalizable manipulation across diverse tasks that outperform existing baselines.
Generating Multimodal Driving Scenes via Next-Scene Prediction
Mar 19, 2025Generative models in Autonomous Driving (AD) enable diverse scene creation, yet existing methods fall short by only capturing a limited range of modalities, restricting the capability of generating controllable scenes for comprehensive evaluation of AD systems. In this paper, we introduce a multimodal generation framework that incorporates four major data modalities, including a novel addition of map modality. With tokenized modalities, our scene sequence generation framework autoregressively predicts each scene while managing computational demands through a two-stage approach. The Temporal AutoRegressive (TAR) component captures inter-frame dynamics for each modality while the Ordered AutoRegressive (OAR) component aligns modalities within each scene by sequentially predicting tokens in a fixed order. To maintain coherence between map and ego-action modalities, we introduce the Action-aware Map Alignment (AMA) module, which applies a transformation based on the ego-action to maintain coherence between these modalities. Our framework effectively generates complex, realistic driving scenes over extended sequences, ensuring multimodal consistency and offering fine-grained control over scene elements.
Revisit Mixture Models for Multi-Agent Simulation: Experimental Study within a Unified Framework
Jan 28, 2025



Simulation plays a crucial role in assessing autonomous driving systems, where the generation of realistic multi-agent behaviors is a key aspect. In multi-agent simulation, the primary challenges include behavioral multimodality and closed-loop distributional shifts. In this study, we revisit mixture models for generating multimodal agent behaviors, which can cover the mainstream methods including continuous mixture models and GPT-like discrete models. Furthermore, we introduce a closed-loop sample generation approach tailored for mixture models to mitigate distributional shifts. Within the unified mixture model~(UniMM) framework, we recognize critical configurations from both model and data perspectives. We conduct a systematic examination of various model configurations, including positive component matching, continuous regression, prediction horizon, and the number of components. Moreover, our investigation into the data configuration highlights the pivotal role of closed-loop samples in achieving realistic simulations. To extend the benefits of closed-loop samples across a broader range of mixture models, we further address the shortcut learning and off-policy learning issues. Leveraging insights from our exploration, the distinct variants proposed within the UniMM framework, including discrete, anchor-free, and anchor-based models, all achieve state-of-the-art performance on the WOSAC benchmark.
BIP3D: Bridging 2D Images and 3D Perception for Embodied Intelligence
Nov 22, 2024



In embodied intelligence systems, a key component is 3D perception algorithm, which enables agents to understand their surrounding environments. Previous algorithms primarily rely on point cloud, which, despite offering precise geometric information, still constrain perception performance due to inherent sparsity, noise, and data scarcity. In this work, we introduce a novel image-centric 3D perception model, BIP3D, which leverages expressive image features with explicit 3D position encoding to overcome the limitations of point-centric methods. Specifically, we leverage pre-trained 2D vision foundation models to enhance semantic understanding, and introduce a spatial enhancer module to improve spatial understanding. Together, these modules enable BIP3D to achieve multi-view, multi-modal feature fusion and end-to-end 3D perception. In our experiments, BIP3D outperforms current state-of-the-art results on the EmbodiedScan benchmark, achieving improvements of 5.69% in the 3D detection task and 15.25% in the 3D visual grounding task.
WidthFormer: Toward Efficient Transformer-based BEV View Transformation
Jan 15, 2024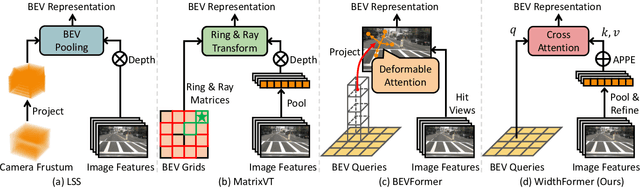



In this work, we present WidthFormer, a novel transformer-based Bird's-Eye-View (BEV) 3D detection method tailored for real-time autonomous-driving applications. WidthFormer is computationally efficient, robust and does not require any special engineering effort to deploy. In this work, we propose a novel 3D positional encoding mechanism capable of accurately encapsulating 3D geometric information, which enables our model to generate high-quality BEV representations with only a single transformer decoder layer. This mechanism is also beneficial for existing sparse 3D object detectors. Inspired by the recently-proposed works, we further improve our model's efficiency by vertically compressing the image features when serving as attention keys and values. We also introduce two modules to compensate for potential information loss due to feature compression. Experimental evaluation on the widely-used nuScenes 3D object detection benchmark demonstrates that our method outperforms previous approaches across different 3D detection architectures. More importantly, our model is highly efficient. For example, when using $256\times 704$ input images, it achieves 1.5 ms and 2.8 ms latency on NVIDIA 3090 GPU and Horizon Journey-5 computation solutions, respectively. Furthermore, WidthFormer also exhibits strong robustness to different degrees of camera perturbations. Our study offers valuable insights into the deployment of BEV transformation methods in real-world, complex road environments. Code is available at https://github.com/ChenhongyiYang/WidthFormer .
EDA: Evolving and Distinct Anchors for Multimodal Motion Prediction
Dec 15, 2023



Motion prediction is a crucial task in autonomous driving, and one of its major challenges lands in the multimodality of future behaviors. Many successful works have utilized mixture models which require identification of positive mixture components, and correspondingly fall into two main lines: prediction-based and anchor-based matching. The prediction clustering phenomenon in prediction-based matching makes it difficult to pick representative trajectories for downstream tasks, while the anchor-based matching suffers from a limited regression capability. In this paper, we introduce a novel paradigm, named Evolving and Distinct Anchors (EDA), to define the positive and negative components for multimodal motion prediction based on mixture models. We enable anchors to evolve and redistribute themselves under specific scenes for an enlarged regression capacity. Furthermore, we select distinct anchors before matching them with the ground truth, which results in impressive scoring performance. Our approach enhances all metrics compared to the baseline MTR, particularly with a notable relative reduction of 13.5% in Miss Rate, resulting in state-of-the-art performance on the Waymo Open Motion Dataset. Code is available at https://github.com/Longzhong-Lin/EDA.
Sparse4D v3: Advancing End-to-End 3D Detection and Tracking
Nov 20, 2023



In autonomous driving perception systems, 3D detection and tracking are the two fundamental tasks. This paper delves deeper into this field, building upon the Sparse4D framework. We introduce two auxiliary training tasks (Temporal Instance Denoising and Quality Estimation) and propose decoupled attention to make structural improvements, leading to significant enhancements in detection performance. Additionally, we extend the detector into a tracker using a straightforward approach that assigns instance ID during inference, further highlighting the advantages of query-based algorithms. Extensive experiments conducted on the nuScenes benchmark validate the effectiveness of the proposed improvements. With ResNet50 as the backbone, we witnessed enhancements of 3.0\%, 2.2\%, and 7.6\% in mAP, NDS, and AMOTA, achieving 46.9\%, 56.1\%, and 49.0\%, respectively. Our best model achieved 71.9\% NDS and 67.7\% AMOTA on the nuScenes test set. Code will be released at \url{https://github.com/linxuewu/Sparse4D}.
Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
May 24, 2023



Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.