 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
Refining CLIP's Spatial Awareness: A Visual-Centric Perspective
Apr 03, 2025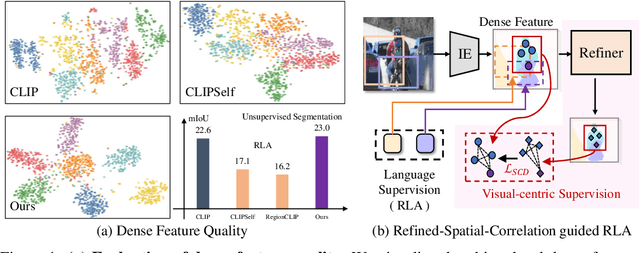
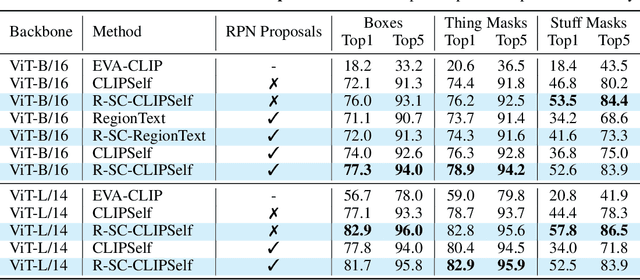
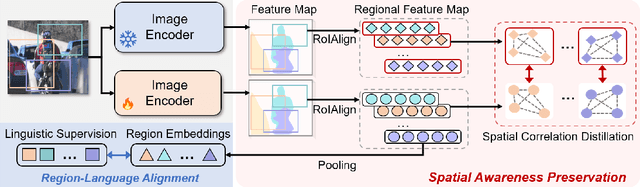
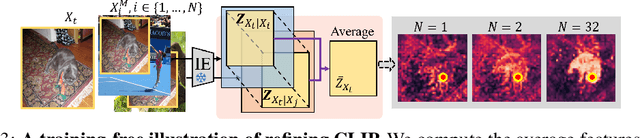
Contrastive Language-Image Pre-training (CLIP) excels in global alignment with language but exhibits limited sensitivity to spatial information, leading to strong performance in zero-shot classification tasks but underperformance in tasks requiring precise spatial understanding. Recent approaches have introduced Region-Language Alignment (RLA) to enhance CLIP's performance in dense multimodal tasks by aligning regional visual representations with corresponding text inputs. However, we find that CLIP ViTs fine-tuned with RLA suffer from notable loss in spatial awareness, which is crucial for dense prediction tasks. To address this, we propose the Spatial Correlation Distillation (SCD) framework, which preserves CLIP's inherent spatial structure and mitigates the above degradation. To further enhance spatial correlations, we introduce a lightweight Refiner that extracts refined correlations directly from CLIP before feeding them into SCD, based on an intriguing finding that CLIP naturally captures high-quality dense features. Together, these components form a robust distillation framework that enables CLIP ViTs to integrate both visual-language and visual-centric improvements, achieving state-of-the-art results across various open-vocabulary dense prediction benchmarks.
Generating Multimodal Driving Scenes via Next-Scene Prediction
Mar 19, 2025Generative models in Autonomous Driving (AD) enable diverse scene creation, yet existing methods fall short by only capturing a limited range of modalities, restricting the capability of generating controllable scenes for comprehensive evaluation of AD systems. In this paper, we introduce a multimodal generation framework that incorporates four major data modalities, including a novel addition of map modality. With tokenized modalities, our scene sequence generation framework autoregressively predicts each scene while managing computational demands through a two-stage approach. The Temporal AutoRegressive (TAR) component captures inter-frame dynamics for each modality while the Ordered AutoRegressive (OAR) component aligns modalities within each scene by sequentially predicting tokens in a fixed order. To maintain coherence between map and ego-action modalities, we introduce the Action-aware Map Alignment (AMA) module, which applies a transformation based on the ego-action to maintain coherence between these modalities. Our framework effectively generates complex, realistic driving scenes over extended sequences, ensuring multimodal consistency and offering fine-grained control over scene elements.
Mitigating Object Dependencies: Improving Point Cloud Self-Supervised Learning through Object Exchange
Apr 11, 2024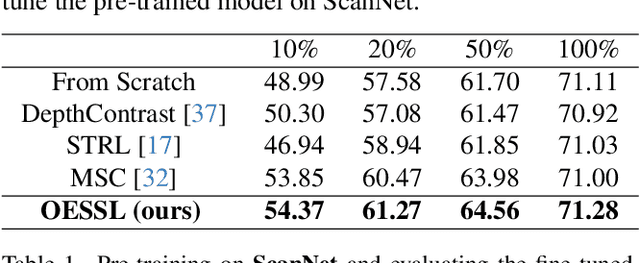
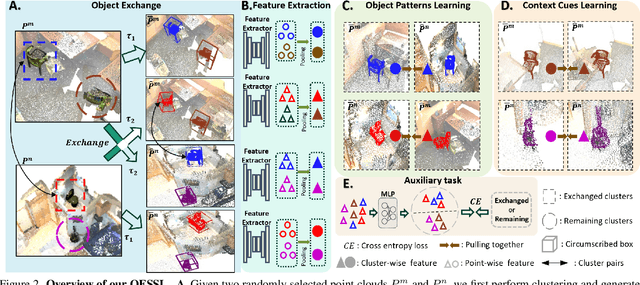

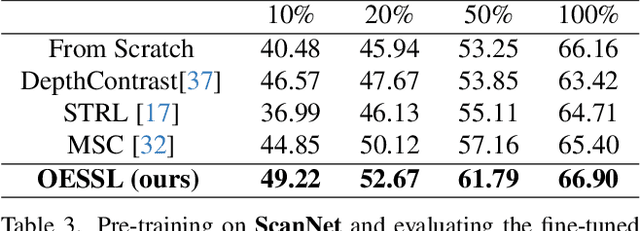
In the realm of point cloud scene understanding, particularly in indoor scenes, objects are arranged following human habits, resulting in objects of certain semantics being closely positioned and displaying notable inter-object correlations. This can create a tendency for neural networks to exploit these strong dependencies, bypassing the individual object patterns. To address this challenge, we introduce a novel self-supervised learning (SSL) strategy. Our approach leverages both object patterns and contextual cues to produce robust features. It begins with the formulation of an object-exchanging strategy, where pairs of objects with comparable sizes are exchanged across different scenes, effectively disentangling the strong contextual dependencies. Subsequently, we introduce a context-aware feature learning strategy, which encodes object patterns without relying on their specific context by aggregating object features across various scenes. Our extensive experiments demonstrate the superiority of our method over existing SSL techniques, further showing its better robustness to environmental changes. Moreover, we showcase the applicability of our approach by transferring pre-trained models to diverse point cloud datasets.
Spatiotemporal Self-supervised Learning for Point Clouds in the Wild
Mar 28, 2023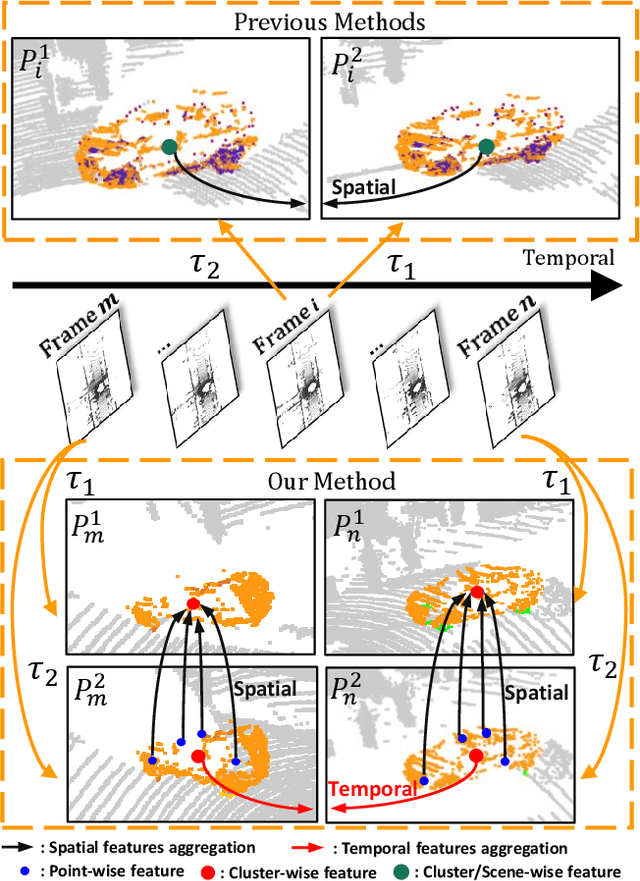
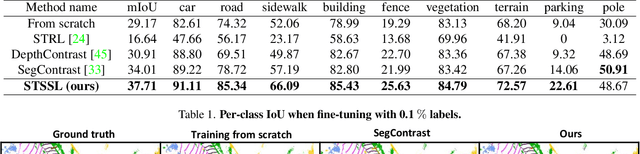
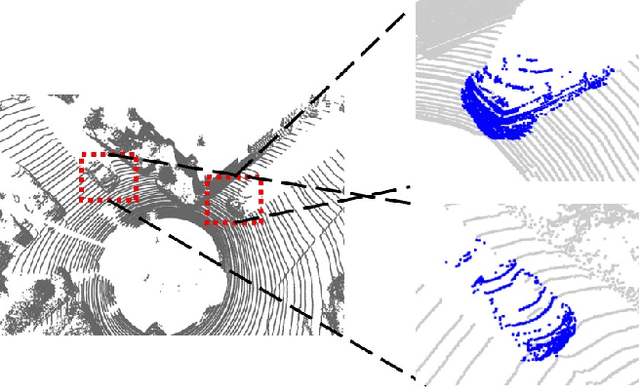
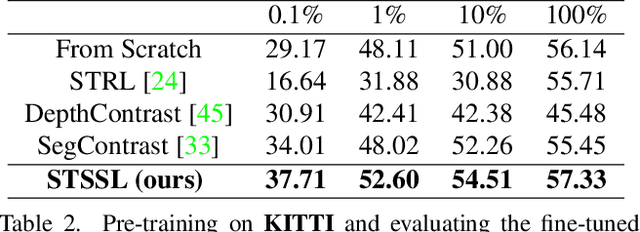
Self-supervised learning (SSL) has the potential to benefit many applications, particularly those where manually annotating data is cumbersome. One such situation is the semantic segmentation of point clouds. In this context, existing methods employ contrastive learning strategies and define positive pairs by performing various augmentation of point clusters in a single frame. As such, these methods do not exploit the temporal nature of LiDAR data. In this paper, we introduce an SSL strategy that leverages positive pairs in both the spatial and temporal domain. To this end, we design (i) a point-to-cluster learning strategy that aggregates spatial information to distinguish objects; and (ii) a cluster-to-cluster learning strategy based on unsupervised object tracking that exploits temporal correspondences. We demonstrate the benefits of our approach via extensive experiments performed by self-supervised training on two large-scale LiDAR datasets and transferring the resulting models to other point cloud segmentation benchmarks. Our results evidence that our method outperforms the state-of-the-art point cloud SSL methods.