 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Object Dependencies: Improving Point Cloud Self-Supervised Learning through Object Exchange
Apr 11, 2024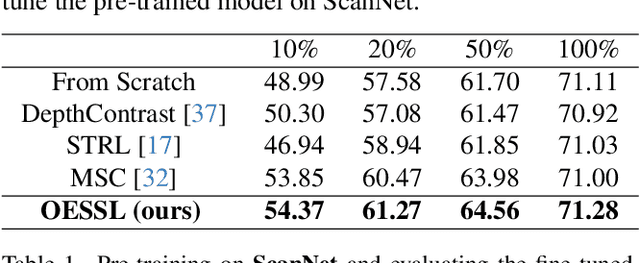
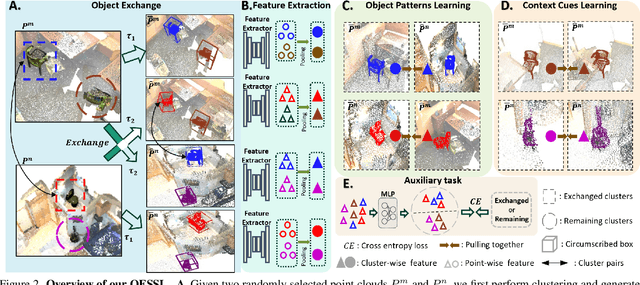

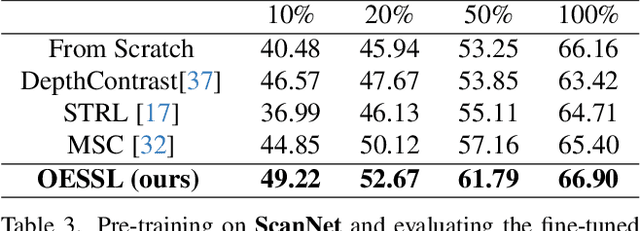
In the realm of point cloud scene understanding, particularly in indoor scenes, objects are arranged following human habits, resulting in objects of certain semantics being closely positioned and displaying notable inter-object correlations. This can create a tendency for neural networks to exploit these strong dependencies, bypassing the individual object patterns. To address this challenge, we introduce a novel self-supervised learning (SSL) strategy. Our approach leverages both object patterns and contextual cues to produce robust features. It begins with the formulation of an object-exchanging strategy, where pairs of objects with comparable sizes are exchanged across different scenes, effectively disentangling the strong contextual dependencies. Subsequently, we introduce a context-aware feature learning strategy, which encodes object patterns without relying on their specific context by aggregating object features across various scenes. Our extensive experiments demonstrate the superiority of our method over existing SSL techniques, further showing its better robustness to environmental changes. Moreover, we showcase the applicability of our approach by transferring pre-trained models to diverse point cloud datasets.
NTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021



Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
Blind Universal Bayesian Image Denoising with Gaussian Noise Level Learning
Jul 05, 2019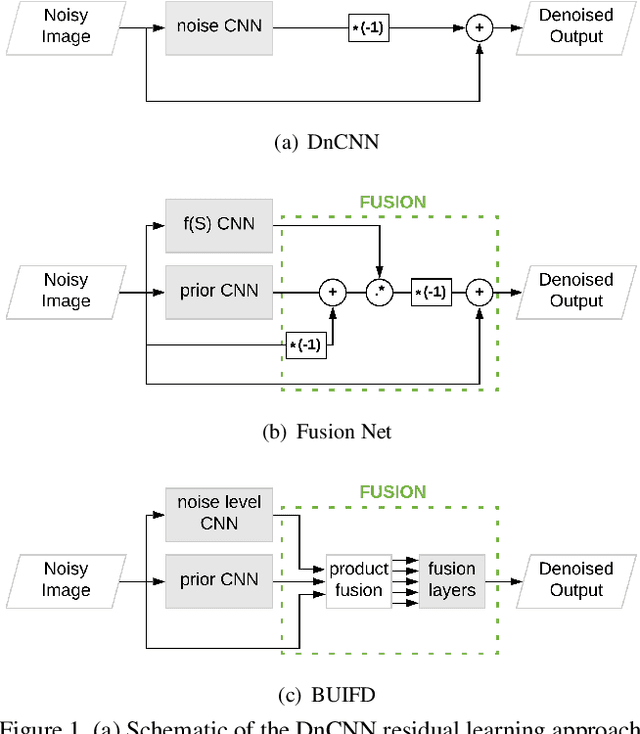



Blind and universal image denoising consists of a unique model that denoises images with any level of noise. It is especially practical as noise levels do not need to be known when the model is developed or at test time. We propose a theoretically-grounded blind and universal deep learning image denoiser for Gaussian noise. Our network is based on an optimal denoising solution, which we call fusion denoising. It is derived theoretically with a Gaussian image prior assumption. Synthetic experiments show our network's generalization strength to unseen noise levels. We also adapt the fusion denoising network architecture for real image denoising. Our approach improves real-world grayscale image denoising PSNR results by up to $0.7dB$ for training noise levels and by up to $2.82dB$ on noise levels not seen during training. It also improves state-of-the-art color image denoising performance on every single noise level, by an average of $0.1dB$, whether trained on or not.