 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRefiner: Teaching Pre-trained ViTs to Self-Dispose Dross via Contrastive Register
May 19, 2026Representation learning with Vision Transformers (ViTs) has advanced rapidly, yet the utility of large-scale models in spatially sensitive tasks is hindered by spurious tokens. Prior efforts to mitigate this have been limited, often defining these artifacts narrowly, for example, as simple high-norm outliers. We argue that this scope is insufficient. For dense prediction tasks, we posit that any token failing to encode location-aligned semantics should be treated as a spurious artifact. This broader definition reveals a more complex problem, leading us to systematically categorize and characterize three fundamental types of spurious tokens that corrupt spatial representations. Based on this comprehensive diagnosis, we propose UniRefiner, a universal refinement framework that teaches pre-trained ViTs to self-dispose of these artifacts. UniRefiner uses contrastive registers to explicitly isolate and redistribute spurious tokens via a dual objective: (i) it aligns image tokens with filtered regular tokens to preserve semantics, and (ii) it aligns register tokens with detected spurious tokens to capture the spurious signals. Our method requires only a few epochs of fine-tuning on ~5k images to refine diverse ViTs, including massive models like EVA-CLIP-8B and InternViT-6B. Experiments demonstrate consistent and significant improvements: notably, the refined EVA-CLIP-8B achieves 51.9\% mIoU on ADE20K (+9.4\%), surpassing specialized vision models like DINOv2 (49.1\%), while zero-shot segmentation accuracy improves by up to 22\%. UniRefiner unlocks the latent spatial potential of existing large-scale foundation models, paving the way for their broader application.
Beyond World-Frame Action Heads: Motion-Centric Action Frames for Vision-Language-Action Models
May 12, 2026Vision-Language-Action (VLA) models have advanced rapidly with stronger backbones, broader pre-training, and larger demonstration datasets, yet their action heads remain largely homogeneous: most directly predict action commands in a fixed world coordinate frame. We propose \textbf{MCF-Proto}, a lightweight action head that equips VLA policies with a Motion-Centric Action Frame (MCF) and a prototype-based action parameterization. At each step, the policy predicts a rotation $R_t \in SO(3)$, composes actions in the transformed local frame from a set of prototypes, and maps them back to the world frame for end-to-end training, using only standard demonstrations without auxiliary supervision. This simple design induces stable emergent structure. Without explicit directional labels, the learned local frames develop a stable geometric structure whose axes are strongly compatible with demonstrated end-effector motion. Meanwhile, actions in the learned representation become substantially more compact, with variation captured by fewer dominant directions and more regularly organized by shared prototypes. These structural properties translate into improved robustness, especially under geometric perturbations. Our results suggest that adding lightweight geometric and compositional structure to the action head can materially improve how VLA policies organize and generalize robotic manipulation behavior. An anonymized code repository is provided in the supplementary material.
TSNN: A Non-parametric and Interpretable Framework for Traffic Time Series Forecasting
May 09, 2026Although many complex models were proposed to analyze time series data, some studies have demonstrated remarkable performance with simpler structures. A recent study proposed a non-parametric framework for 3D point cloud classification, which has the potential to be adapted for time series forecasting and enable interpretability. Inspired by the previous works, we present TSNN, a non-parametric and interpretable framework for traffic time series forecasting. TSNN consists of multiple layers that decouple the time series by matching the entries in a memory bank, where the memory bank is constructed using a similar matching process within the training set. It leverages the periodicity in traffic data to enhance forecasting accuracy while maintaining a simple model architecture. The proposed model operates without trainable parameters, preserving its inherent interpretability. In the experiments, TSNN achieves competitive performance compared to the typical deep learning models in four real-world traffic flow datasets. We also visualize the decoupling process to show the effectiveness of the components. Finally, we demonstrate the interpretability of the model and illustrate the contribution of each time step within the memory bank.
Cheers: Decoupling Patch Details from Semantic Representations Enables Unified Multimodal Comprehension and Generation
Mar 13, 2026A recent cutting-edge topic in multimodal modeling is to unify visual comprehension and generation within a single model. However, the two tasks demand mismatched decoding regimes and visual representations, making it non-trivial to jointly optimize within a shared feature space. In this work, we present Cheers, a unified multimodal model that decouples patch-level details from semantic representations, thereby stabilizing semantics for multimodal understanding and improving fidelity for image generation via gated detail residuals. Cheers includes three key components: (i) a unified vision tokenizer that encodes and compresses image latent states into semantic tokens for efficient LLM conditioning, (ii) an LLM-based Transformer that unifies autoregressive decoding for text generation and diffusion decoding for image generation, and (iii) a cascaded flow matching head that decodes visual semantics first and then injects semantically gated detail residuals from the vision tokenizer to refine high-frequency content. Experiments on popular benchmarks demonstrate that Cheers matches or surpasses advanced UMMs in both visual understanding and generation. Cheers also achieves 4x token compression, enabling more efficient high-resolution image encoding and generation. Notably, Cheers outperforms the Tar-1.5B on the popular benchmarks GenEval and MMBench, while requiring only 20% of the training cost, indicating effective and efficient (i.e., 4x token compression) unified multimodal modeling. We will release all code and data for future research.
Unveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
AlignDrive: Aligned Lateral-Longitudinal Planning for End-to-End Autonomous Driving
Jan 05, 2026End-to-end autonomous driving has rapidly progressed, enabling joint perception and planning in complex environments. In the planning stage, state-of-the-art (SOTA) end-to-end autonomous driving models decouple planning into parallel lateral and longitudinal predictions. While effective, this parallel design can lead to i) coordination failures between the planned path and speed, and ii) underutilization of the drive path as a prior for longitudinal planning, thus redundantly encoding static information. To address this, we propose a novel cascaded framework that explicitly conditions longitudinal planning on the drive path, enabling coordinated and collision-aware lateral and longitudinal planning. Specifically, we introduce a path-conditioned formulation that explicitly incorporates the drive path into longitudinal planning. Building on this, the model predicts longitudinal displacements along the drive path rather than full 2D trajectory waypoints. This design simplifies longitudinal reasoning and more tightly couples it with lateral planning. Additionally, we introduce a planning-oriented data augmentation strategy that simulates rare safety-critical events, such as vehicle cut-ins, by adding agents and relabeling longitudinal targets to avoid collision. Evaluated on the challenging Bench2Drive benchmark, our method sets a new SOTA, achieving a driving score of 89.07 and a success rate of 73.18%, demonstrating significantly improved coordination and safety
Head Anchor Enhanced Detection and Association for Crowded Pedestrian Tracking
Aug 07, 2025Visual pedestrian tracking represents a promising research field, with extensive applications in intelligent surveillance, behavior analysis, and human-computer interaction. However, real-world applications face significant occlusion challenges. When multiple pedestrians interact or overlap, the loss of target features severely compromises the tracker's ability to maintain stable trajectories. Traditional tracking methods, which typically rely on full-body bounding box features extracted from {Re-ID} models and linear constant-velocity motion assumptions, often struggle in severe occlusion scenarios. To address these limitations, this work proposes an enhanced tracking framework that leverages richer feature representations and a more robust motion model. Specifically, the proposed method incorporates detection features from both the regression and classification branches of an object detector, embedding spatial and positional information directly into the feature representations. To further mitigate occlusion challenges, a head keypoint detection model is introduced, as the head is less prone to occlusion compared to the full body. In terms of motion modeling, we propose an iterative Kalman filtering approach designed to align with modern detector assumptions, integrating 3D priors to better complete motion trajectories in complex scenes. By combining these advancements in appearance and motion modeling, the proposed method offers a more robust solution for multi-object tracking in crowded environments where occlusions are prevalent.
Multi-tracklet Tracking for Generic Targets with Adaptive Detection Clustering
Aug 07, 2025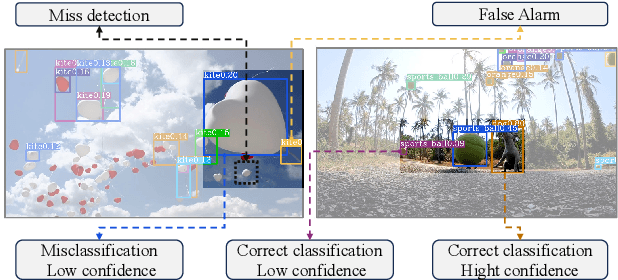
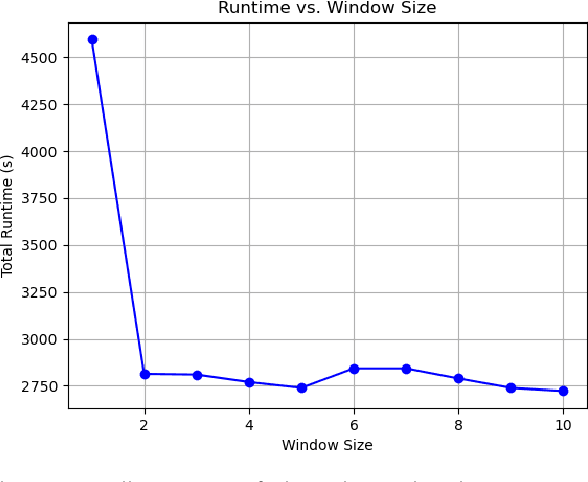
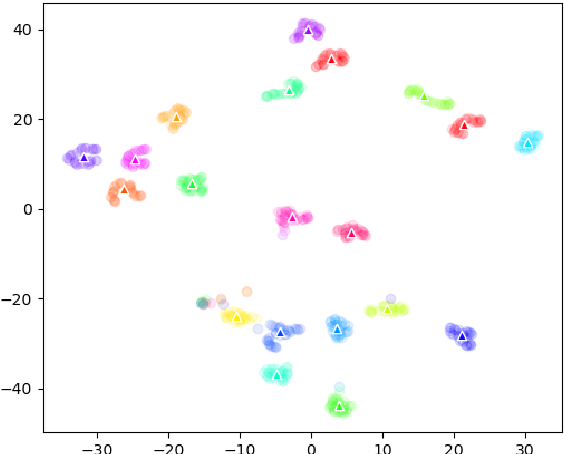
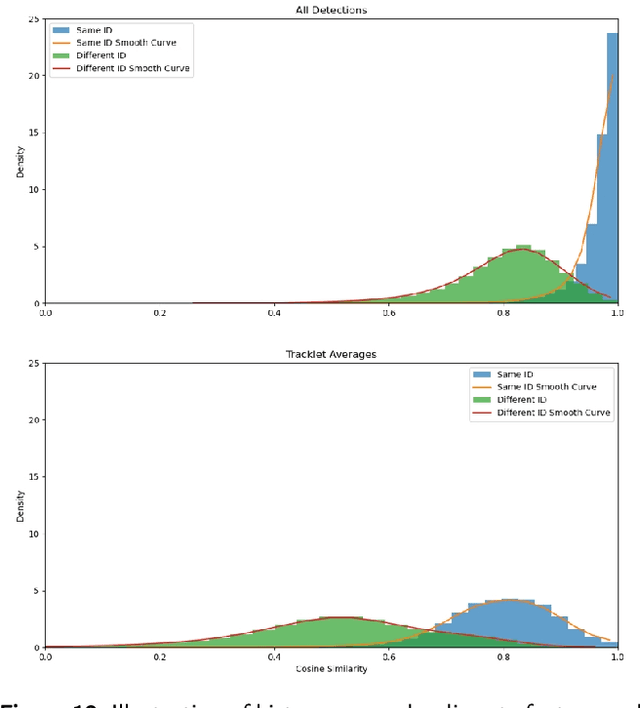
Tracking specific targets, such as pedestrians and vehicles, has been the focus of recent vision-based multitarget tracking studies. However, in some real-world scenarios, unseen categories often challenge existing methods due to low-confidence detections, weak motion and appearance constraints, and long-term occlusions. To address these issues, this article proposes a tracklet-enhanced tracker called Multi-Tracklet Tracking (MTT) that integrates flexible tracklet generation into a multi-tracklet association framework. This framework first adaptively clusters the detection results according to their short-term spatio-temporal correlation into robust tracklets and then estimates the best tracklet partitions using multiple clues, such as location and appearance over time to mitigate error propagation in long-term association. Finally, extensive experiments on the benchmark for generic multiple object tracking demonstrate the competitiveness of the proposed framework.
InstructionBench: An Instructional Video Understanding Benchmark
Apr 07, 2025



Despite progress in video large language models (Video-LLMs), research on instructional video understanding, crucial for enhancing access to instructional content, remains insufficient. To address this, we introduce InstructionBench, an Instructional video understanding Benchmark, which challenges models' advanced temporal reasoning within instructional videos characterized by their strict step-by-step flow. Employing GPT-4, we formulate Q\&A pairs in open-ended and multiple-choice formats to assess both Coarse-Grained event-level and Fine-Grained object-level reasoning. Our filtering strategies exclude questions answerable purely by common-sense knowledge, focusing on visual perception and analysis when evaluating Video-LLM models. The benchmark finally contains 5k questions across over 700 videos. We evaluate the latest Video-LLMs on our InstructionBench, finding that closed-source models outperform open-source ones. However, even the best model, GPT-4o, achieves only 53.42\% accuracy, indicating significant gaps in temporal reasoning. To advance the field, we also develop a comprehensive instructional video dataset with over 19k Q\&A pairs from nearly 2.5k videos, using an automated data generation framework, thereby enriching the community's research resources.
Refining CLIP's Spatial Awareness: A Visual-Centric Perspective
Apr 03, 2025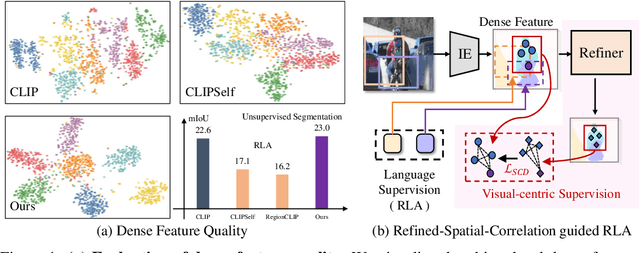
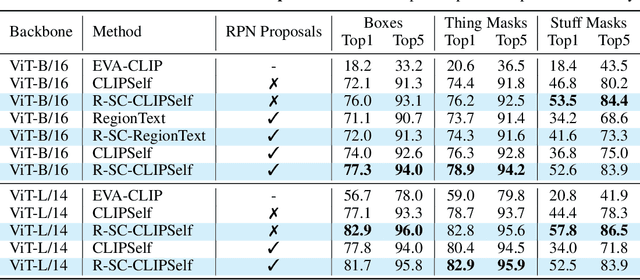
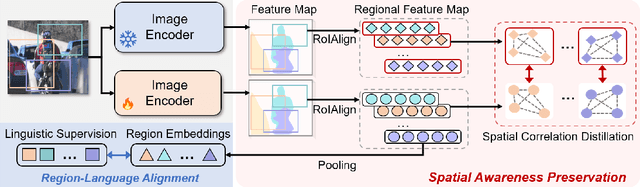
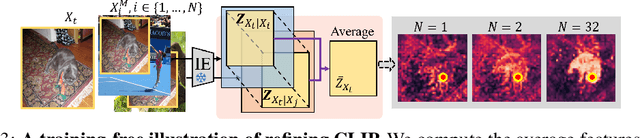
Contrastive Language-Image Pre-training (CLIP) excels in global alignment with language but exhibits limited sensitivity to spatial information, leading to strong performance in zero-shot classification tasks but underperformance in tasks requiring precise spatial understanding. Recent approaches have introduced Region-Language Alignment (RLA) to enhance CLIP's performance in dense multimodal tasks by aligning regional visual representations with corresponding text inputs. However, we find that CLIP ViTs fine-tuned with RLA suffer from notable loss in spatial awareness, which is crucial for dense prediction tasks. To address this, we propose the Spatial Correlation Distillation (SCD) framework, which preserves CLIP's inherent spatial structure and mitigates the above degradation. To further enhance spatial correlations, we introduce a lightweight Refiner that extracts refined correlations directly from CLIP before feeding them into SCD, based on an intriguing finding that CLIP naturally captures high-quality dense features. Together, these components form a robust distillation framework that enables CLIP ViTs to integrate both visual-language and visual-centric improvements, achieving state-of-the-art results across various open-vocabulary dense prediction benchmarks.