 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Performance Gain from Mixing Multiple Partially Labeled Samples in Multi-label Image Classification
Paper and Code
May 24, 2024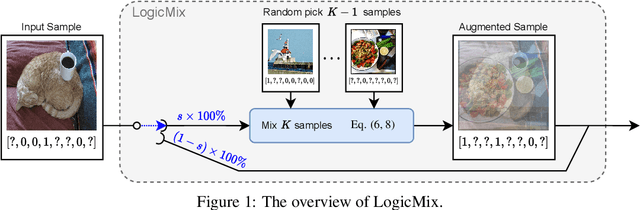

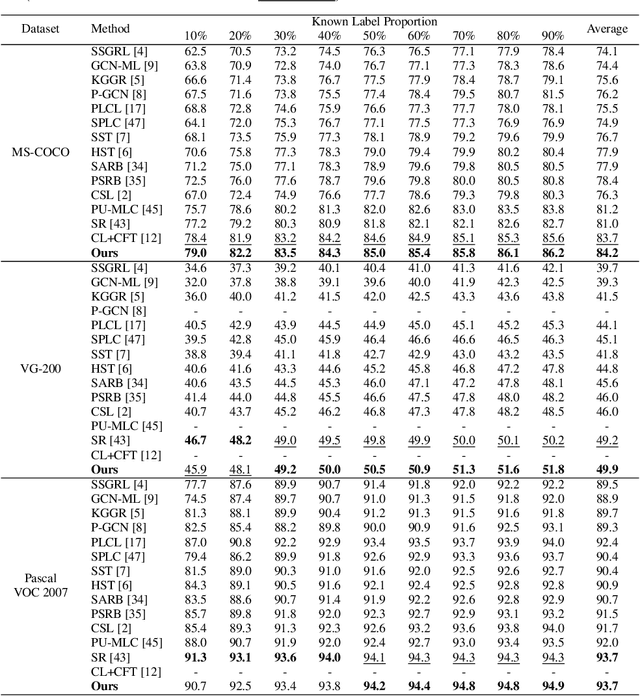
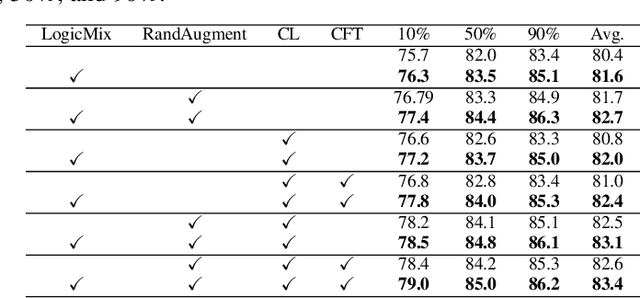
Multi-label image classification datasets are often partially labeled where many labels are missing, posing a significant challenge to training accurate deep classifiers. However, the powerful Mixup sample-mixing data augmentation cannot be well utilized to address this challenge, as it cannot perform linear interpolation on the unknown labels to construct augmented samples. In this paper, we propose LogicMix, a Mixup variant designed for such partially labeled datasets. LogicMix mixes the sample labels by logical OR so that the unknown labels can be correctly mixed by utilizing OR's logical equivalences, including the domination and identity laws. Unlike Mixup, which mixes exactly two samples, LogicMix can mix multiple ($\geq2$) partially labeled samples, constructing visually more confused augmented samples to regularize training. LogicMix is more general and effective than other compared Mixup variants in the experiments on various partially labeled dataset scenarios. Moreover, it is plug-and-play and only requires minimal computation, hence it can be easily inserted into existing frameworks to collaborate with other methods to improve model performance with a negligible impact on training time, as demonstrated through extensive experiments. In particular, through the collaboration of LogicMix, RandAugment, Curriculum Labeling, and Category-wise Fine-Tuning, we attain state-of-the-art performance on MS-COCO, VG-200, and Pascal VOC 2007 benchmarking datasets. The remarkable generality, effectiveness, collaboration, and simplicity suggest that LogicMix promises to be a popular and vital data augmentation method.