 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Performance Gain from Mixing Multiple Partially Labeled Samples in Multi-label Image Classification
May 24, 2024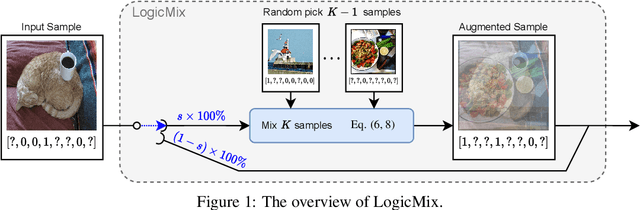

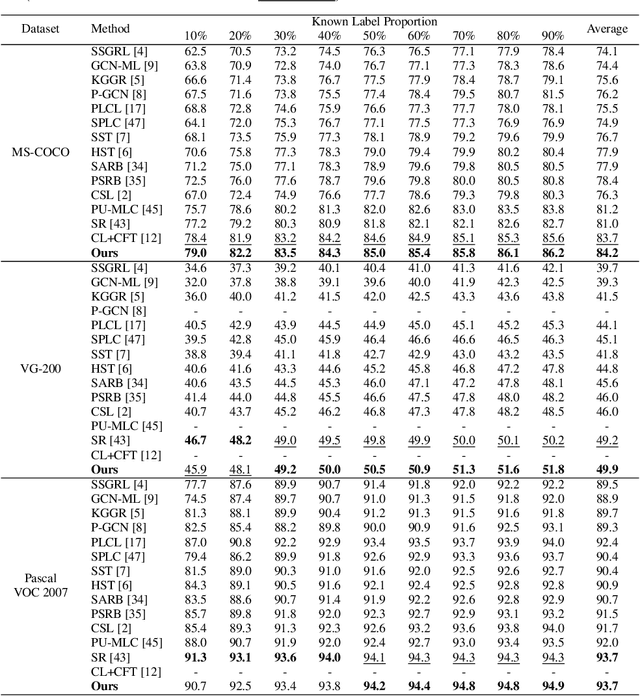
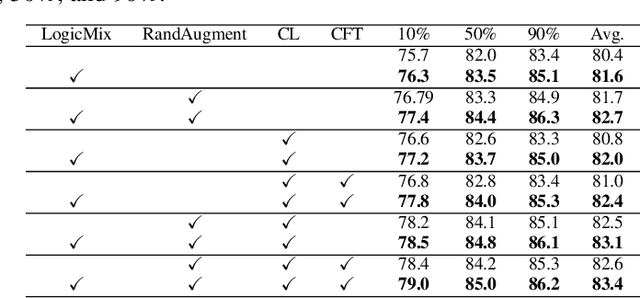
Multi-label image classification datasets are often partially labeled where many labels are missing, posing a significant challenge to training accurate deep classifiers. However, the powerful Mixup sample-mixing data augmentation cannot be well utilized to address this challenge, as it cannot perform linear interpolation on the unknown labels to construct augmented samples. In this paper, we propose LogicMix, a Mixup variant designed for such partially labeled datasets. LogicMix mixes the sample labels by logical OR so that the unknown labels can be correctly mixed by utilizing OR's logical equivalences, including the domination and identity laws. Unlike Mixup, which mixes exactly two samples, LogicMix can mix multiple ($\geq2$) partially labeled samples, constructing visually more confused augmented samples to regularize training. LogicMix is more general and effective than other compared Mixup variants in the experiments on various partially labeled dataset scenarios. Moreover, it is plug-and-play and only requires minimal computation, hence it can be easily inserted into existing frameworks to collaborate with other methods to improve model performance with a negligible impact on training time, as demonstrated through extensive experiments. In particular, through the collaboration of LogicMix, RandAugment, Curriculum Labeling, and Category-wise Fine-Tuning, we attain state-of-the-art performance on MS-COCO, VG-200, and Pascal VOC 2007 benchmarking datasets. The remarkable generality, effectiveness, collaboration, and simplicity suggest that LogicMix promises to be a popular and vital data augmentation method.
Category-wise Fine-Tuning: Resisting Incorrect Pseudo-Labels in Multi-Label Image Classification with Partial Labels
Jan 30, 2024



Large-scale image datasets are often partially labeled, where only a few categories' labels are known for each image. Assigning pseudo-labels to unknown labels to gain additional training signals has become prevalent for training deep classification models. However, some pseudo-labels are inevitably incorrect, leading to a notable decline in the model classification performance. In this paper, we propose a novel method called Category-wise Fine-Tuning (CFT), aiming to reduce model inaccuracies caused by the wrong pseudo-labels. In particular, CFT employs known labels without pseudo-labels to fine-tune the logistic regressions of trained models individually to calibrate each category's model predictions. Genetic Algorithm, seldom used for training deep models, is also utilized in CFT to maximize the classification performance directly. CFT is applied to well-trained models, unlike most existing methods that train models from scratch. Hence, CFT is general and compatible with models trained with different methods and schemes, as demonstrated through extensive experiments. CFT requires only a few seconds for each category for calibration with consumer-grade GPUs. We achieve state-of-the-art results on three benchmarking datasets, including the CheXpert chest X-ray competition dataset (ensemble mAUC 93.33%, single model 91.82%), partially labeled MS-COCO (average mAP 83.69%), and Open Image V3 (mAP 85.31%), outperforming the previous bests by 0.28%, 2.21%, 2.50%, and 0.91%, respectively. The single model on CheXpert has been officially evaluated by the competition server, endorsing the correctness of the result. The outstanding results and generalizability indicate that CFT could be substantial and prevalent for classification model development. Code is available at: https://github.com/maxium0526/category-wise-fine-tuning.
Group Equivariant BEV for 3D Object Detection
Apr 26, 2023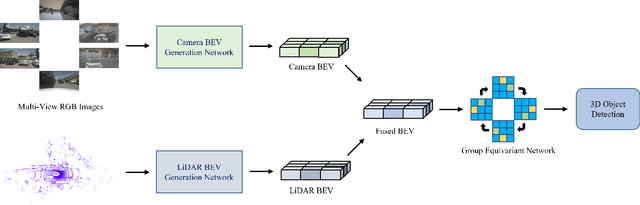
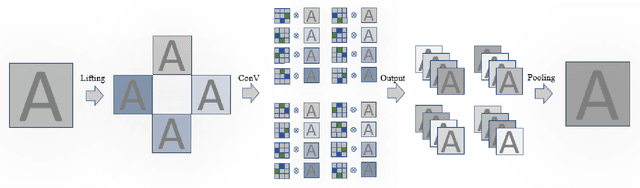

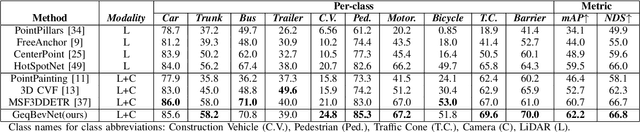
Recently, 3D object detection has attracted significant attention and achieved continuous improvement in real road scenarios. The environmental information is collected from a single sensor or multi-sensor fusion to detect interested objects. However, most of the current 3D object detection approaches focus on developing advanced network architectures to improve the detection precision of the object rather than considering the dynamic driving scenes, where data collected from sensors equipped in the vehicle contain various perturbation features. As a result, existing work cannot still tackle the perturbation issue. In order to solve this problem, we propose a group equivariant bird's eye view network (GeqBevNet) based on the group equivariant theory, which introduces the concept of group equivariant into the BEV fusion object detection network. The group equivariant network is embedded into the fused BEV feature map to facilitate the BEV-level rotational equivariant feature extraction, thus leading to lower average orientation error. In order to demonstrate the effectiveness of the GeqBevNet, the network is verified on the nuScenes validation dataset in which mAOE can be decreased to 0.325. Experimental results demonstrate that GeqBevNet can extract more rotational equivariant features in the 3D object detection of the actual road scene and improve the performance of object orientation prediction.
Autoencoders with Intrinsic Dimension Constraints for Learning Low Dimensional Image Representations
Apr 16, 2023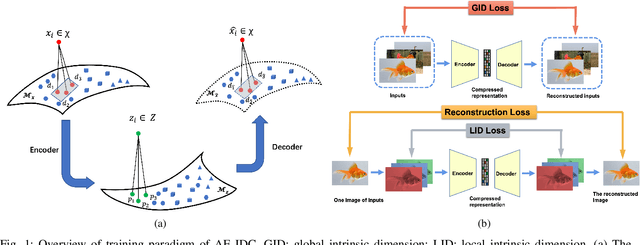
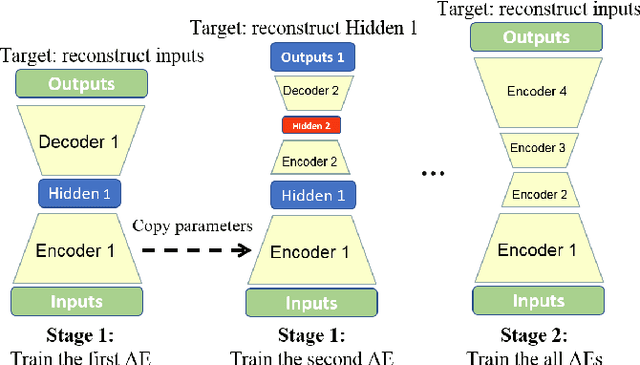
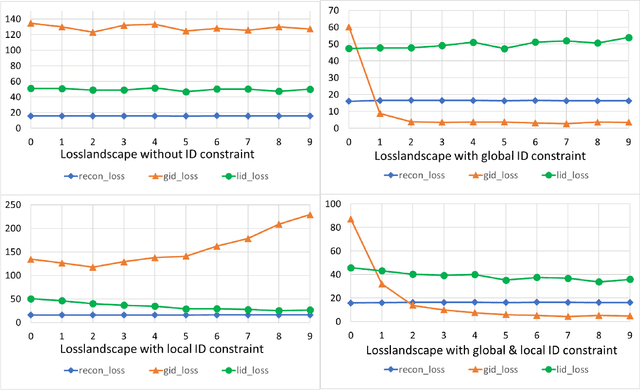

Autoencoders have achieved great success in various computer vision applications. The autoencoder learns appropriate low dimensional image representations through the self-supervised paradigm, i.e., reconstruction. Existing studies mainly focus on the minimizing the reconstruction error on pixel level of image, while ignoring the preservation of Intrinsic Dimension (ID), which is a fundamental geometric property of data representations in Deep Neural Networks (DNNs). Motivated by the important role of ID, in this paper, we propose a novel deep representation learning approach with autoencoder, which incorporates regularization of the global and local ID constraints into the reconstruction of data representations. This approach not only preserves the global manifold structure of the whole dataset, but also maintains the local manifold structure of the feature maps of each point, which makes the learned low-dimensional features more discriminant and improves the performance of the downstream algorithms. To our best knowledge, existing works are rare and limited on exploiting both global and local ID invariant properties on the regularization of autoencoders. Numerical experimental results on benchmark datasets (Extended Yale B, Caltech101 and ImageNet) show that the resulting regularized learning models achieve better discriminative representations for downstream tasks including image classification and clustering.
Hand and Arm Gesture-based Human-Robot Interaction: A Review
Sep 17, 2022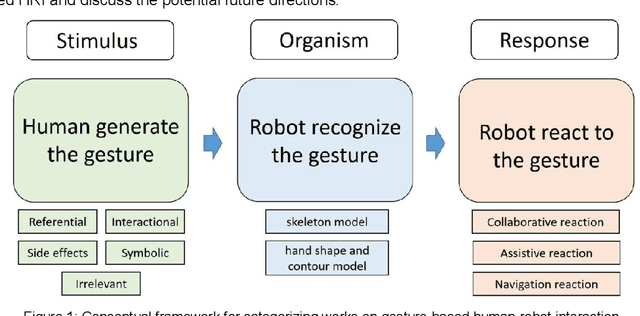
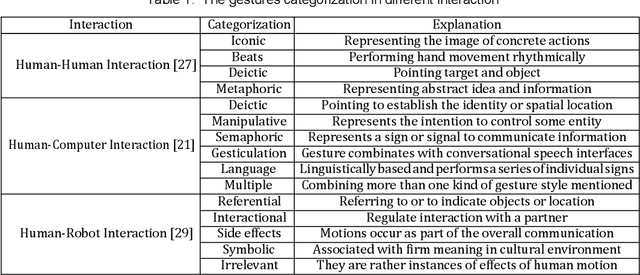
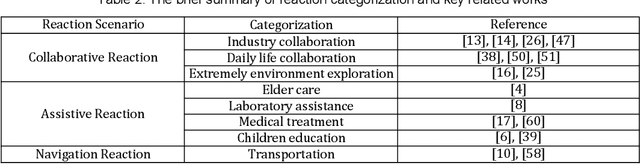
The study of Human-Robot Interaction (HRI) aims to create close and friendly communication between humans and robots. In the human-center HRI, an essential aspect of implementing a successful and effective HRI is building a natural and intuitive interaction, including verbal and nonverbal. As a prevalent nonverbally communication approach, hand and arm gesture communication happen ubiquitously in our daily life. A considerable amount of work on gesture-based HRI is scattered in various research domains. However, a systematic understanding of the works on gesture-based HRI is still lacking. This paper intends to provide a comprehensive review of gesture-based HRI and focus on the advanced finding in this area. Following the stimulus-organism-response framework, this review consists of: (i) Generation of human gesture(stimulus). (ii) Robot recognition of human gesture(organism). (iii) Robot reaction to human gesture(response). Besides, this review summarizes the research status of each element in the framework and analyze the advantages and disadvantages of related works. Toward the last part, this paper discusses the current research challenges on gesture-based HRI and provides possible future directions.