 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Performance Gain from Mixing Multiple Partially Labeled Samples in Multi-label Image Classification
May 24, 2024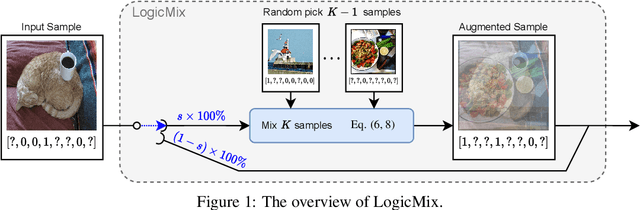

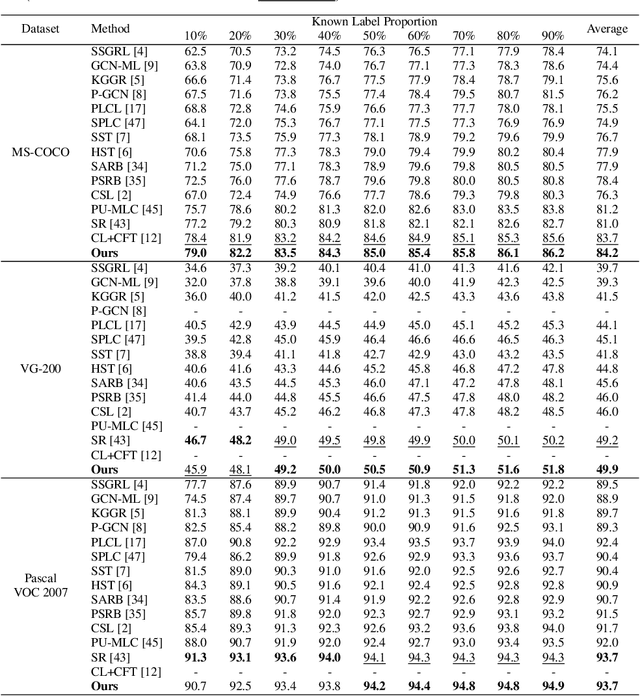
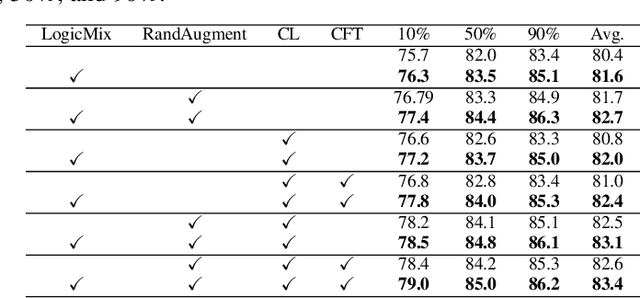
Multi-label image classification datasets are often partially labeled where many labels are missing, posing a significant challenge to training accurate deep classifiers. However, the powerful Mixup sample-mixing data augmentation cannot be well utilized to address this challenge, as it cannot perform linear interpolation on the unknown labels to construct augmented samples. In this paper, we propose LogicMix, a Mixup variant designed for such partially labeled datasets. LogicMix mixes the sample labels by logical OR so that the unknown labels can be correctly mixed by utilizing OR's logical equivalences, including the domination and identity laws. Unlike Mixup, which mixes exactly two samples, LogicMix can mix multiple ($\geq2$) partially labeled samples, constructing visually more confused augmented samples to regularize training. LogicMix is more general and effective than other compared Mixup variants in the experiments on various partially labeled dataset scenarios. Moreover, it is plug-and-play and only requires minimal computation, hence it can be easily inserted into existing frameworks to collaborate with other methods to improve model performance with a negligible impact on training time, as demonstrated through extensive experiments. In particular, through the collaboration of LogicMix, RandAugment, Curriculum Labeling, and Category-wise Fine-Tuning, we attain state-of-the-art performance on MS-COCO, VG-200, and Pascal VOC 2007 benchmarking datasets. The remarkable generality, effectiveness, collaboration, and simplicity suggest that LogicMix promises to be a popular and vital data augmentation method.
Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement
Mar 05, 2024



Transferring features learned from natural to medical images for classification is common. However, challenges arise due to the scarcity of certain medical image types and the feature disparities between natural and medical images. Two-step transfer learning has been recognized as a promising solution for this issue. However, choosing an appropriate intermediate domain would be critical in further improving the classification performance. In this work, we explore the effectiveness of using color fundus photographs of the diabetic retina dataset as an intermediate domain for two-step heterogeneous learning (THTL) to classify laryngeal vascular images with nine deep-learning models. Experiment results confirm that although the images in both the intermediate and target domains share vascularized characteristics, the accuracy is drastically reduced compared to one-step transfer learning, where only the last layer is fine-tuned (e.g., ResNet18 drops 14.7%, ResNet50 drops 14.8%). By analyzing the Layer Class Activation Maps (LayerCAM), we uncover a novel finding that the prevalent radial vascular pattern in the intermediate domain prevents learning the features of twisted and tangled vessels that distinguish the malignant class in the target domain. To address the performance drop, we propose the Step-Wise Fine-Tuning (SWFT) method on ResNet in the second step of THTL, resulting in substantial accuracy improvements. Compared to THTL's second step, where only the last layer is fine-tuned, accuracy increases by 26.1% for ResNet18 and 20.4% for ResNet50. Additionally, compared to training from scratch, using ImageNet as the source domain could slightly improve classification performance for laryngeal vascular, but the differences are insignificant.
Category-wise Fine-Tuning: Resisting Incorrect Pseudo-Labels in Multi-Label Image Classification with Partial Labels
Jan 30, 2024



Large-scale image datasets are often partially labeled, where only a few categories' labels are known for each image. Assigning pseudo-labels to unknown labels to gain additional training signals has become prevalent for training deep classification models. However, some pseudo-labels are inevitably incorrect, leading to a notable decline in the model classification performance. In this paper, we propose a novel method called Category-wise Fine-Tuning (CFT), aiming to reduce model inaccuracies caused by the wrong pseudo-labels. In particular, CFT employs known labels without pseudo-labels to fine-tune the logistic regressions of trained models individually to calibrate each category's model predictions. Genetic Algorithm, seldom used for training deep models, is also utilized in CFT to maximize the classification performance directly. CFT is applied to well-trained models, unlike most existing methods that train models from scratch. Hence, CFT is general and compatible with models trained with different methods and schemes, as demonstrated through extensive experiments. CFT requires only a few seconds for each category for calibration with consumer-grade GPUs. We achieve state-of-the-art results on three benchmarking datasets, including the CheXpert chest X-ray competition dataset (ensemble mAUC 93.33%, single model 91.82%), partially labeled MS-COCO (average mAP 83.69%), and Open Image V3 (mAP 85.31%), outperforming the previous bests by 0.28%, 2.21%, 2.50%, and 0.91%, respectively. The single model on CheXpert has been officially evaluated by the competition server, endorsing the correctness of the result. The outstanding results and generalizability indicate that CFT could be substantial and prevalent for classification model development. Code is available at: https://github.com/maxium0526/category-wise-fine-tuning.
Projective Transformation Rectification for Camera-captured Chest X-ray Photograph Interpretation with Synthetic Data
Oct 12, 2022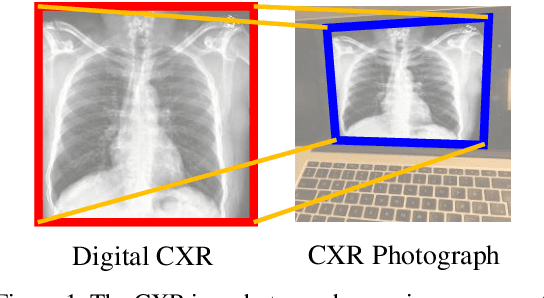


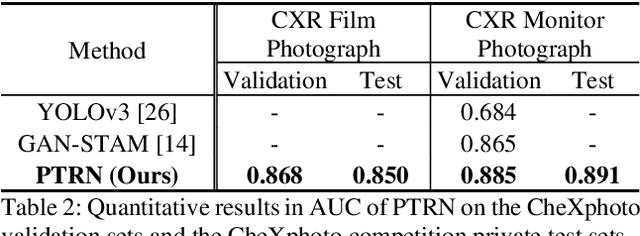
Automatic interpretation on smartphone-captured chest X-ray (CXR) photographs is challenging due to the geometric distortion (projective transformation) caused by the non-ideal camera position. In this paper, we proposed an innovative deep learning-based Projective Transformation Rectification Network (PTRN) to automatically rectify such distortions by predicting the projective transformation matrix. PTRN is trained on synthetic data to avoid the expensive collection of natural data. Therefore, we proposed an innovative synthetic data framework that accounts for the visual attributes of natural photographs including screen, background, illuminations, and visual artifacts, and generate synthetic CXR photographs and projective transformation matrices as the ground-truth labels for training PTRN. Finally, smartphone-captured CXR photographs are automatically rectified by trained PTRN and interpreted by a classifier trained on high-quality digital CXRs to produce final interpretation results. In the CheXphoto CXR photograph interpretation competition released by the Stanford University Machine Learning Group, our approach achieves a huge performance improvement and won first place (ours 0.850, second-best 0.762, in AUC). A deeper analysis demonstrates that the use of PTRN successfully achieves the performance on CXR photographs to the same level as on digital CXRs, indicating PTRN can eliminate all negative impacts of projective transformation to the interpretation performance. Additionally, there are many real-world scenarios where distorted photographs have to be used for image classification, our PTRN can be used to solve those similar problems due to its generality design.