 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSNN: A Non-parametric and Interpretable Framework for Traffic Time Series Forecasting
May 09, 2026Although many complex models were proposed to analyze time series data, some studies have demonstrated remarkable performance with simpler structures. A recent study proposed a non-parametric framework for 3D point cloud classification, which has the potential to be adapted for time series forecasting and enable interpretability. Inspired by the previous works, we present TSNN, a non-parametric and interpretable framework for traffic time series forecasting. TSNN consists of multiple layers that decouple the time series by matching the entries in a memory bank, where the memory bank is constructed using a similar matching process within the training set. It leverages the periodicity in traffic data to enhance forecasting accuracy while maintaining a simple model architecture. The proposed model operates without trainable parameters, preserving its inherent interpretability. In the experiments, TSNN achieves competitive performance compared to the typical deep learning models in four real-world traffic flow datasets. We also visualize the decoupling process to show the effectiveness of the components. Finally, we demonstrate the interpretability of the model and illustrate the contribution of each time step within the memory bank.
On the Impact of Phase Errors in Phase-Dependent Amplitudes of Near-Field RISs
Dec 28, 2025This paper investigates mutual coupling between phase-dependent amplitudes (PDAs) and designed phase shifts within pixels of near-field (NF) reconfigurable intelligent surfaces (RISs) in the presence of phase errors (PEs). In contrast to existing research that treats phase shifts with errors (PSEs) and the PDAs separately, we introduce a remaining power (RP) metric to quantify the proportion of power preserved in the signals reflected by the RIS, and we prove its asymptotic convergence to theoretical values by leveraging extended Glivenko-Cantelli theorem. Then, the RP of signals passing through RIS pixels is jointly examined under combined phase and amplitude uncertainties. In addition, we propose four pixel reflection models to capture practical conditions, and we derive approximate polynomial upper bounds for the RP with error terms by applying Taylor expansion. Furthermore, based on Friis transmission formula and projected aperture, we propose a general NF channel model that incorporates the coupling between the PSEs and the PDAs. By using Cauchy-Bunyakovsky-Schwarz inequality and Riemann sums, we derive a closed-form upper bound on spectral efficiency, and the bound becomes tighter as the pixel area decreases. We reveal that as the RIS phase shifts approach the ends of their range, the RP under independent and identically distributed PEs is smaller than that under fully correlated PEs, whereas this relationship reverses when the phase shifts are near the middle of their range. Neglecting the PEs in the PDAs leads to an overestimation of the RIS performance gain, explaining the discrepancies between theoretical and measured results.
RIS-Empowered OTFS Modulation With Faster-than-Nyquist Signaling in High-Mobility Wireless Communications
Dec 23, 2025High-mobility wireless communication systems suffer from severe Doppler spread and multi-path delay, which degrade the reliability and spectral efficiency of conventional modulation schemes. Orthogonal time frequency space (OTFS) modulation offers strong robustness in such environments by representing symbols in the delay-Doppler (DD) domain, while faster-than-Nyquist (FTN) signaling can further enhance spectral efficiency through intentional symbol packing. Meanwhile, reconfigurable intelligent surfaces (RIS) provide a promising means to improve link quality via passive beamforming. Motivated by these advantages, we propose a novel RIS-empowered OTFS modulation with FTN signaling (RIS-OTFS-FTN) scheme. First, we establish a unified DD-domain input-output relationship that jointly accounts for RIS passive beamforming, FTN-induced inter-symbol interference, and DD-domain channel characteristics. Based on this model, we provide comprehensive analytical performance for the frame error rate, spectral efficiency, and peak-to-average power ratio (PAPR), etc. Furthermore, a practical RIS phase adjustment strategy with quantized phase selection is designed to maximize the effective channel gain. Extensive Monte Carlo simulations under a standardized extended vehicular A (EVA) channel model validate the theoretical results and provide key insights into the trade-offs among spectral efficiency, PAPR, input back-off (IBO), and error performance, with some interesting insights.The proposed RIS-OTFS-FTN scheme demonstrates notable performance gains in both reliability and spectral efficiency, offering a viable solution for future high-mobility and spectrum-constrained wireless systems.
Unveiling Hidden Threats: Using Fractal Triggers to Boost Stealthiness of Distributed Backdoor Attacks in Federated Learning
Nov 12, 2025Traditional distributed backdoor attacks (DBA) in federated learning improve stealthiness by decomposing global triggers into sub-triggers, which however requires more poisoned data to maintian the attck strength and hence increases the exposure risk. To overcome this defect, This paper proposes a novel method, namely Fractal-Triggerred Distributed Backdoor Attack (FTDBA), which leverages the self-similarity of fractals to enhance the feature strength of sub-triggers and hence significantly reduce the required poisoning volume for the same attack strength. To address the detectability of fractal structures in the frequency and gradient domains, we introduce a dynamic angular perturbation mechanism that adaptively adjusts perturbation intensity across the training phases to balance efficiency and stealthiness. Experiments show that FTDBA achieves a 92.3\% attack success rate with only 62.4\% of the poisoning volume required by traditional DBA methods, while reducing the detection rate by 22.8\% and KL divergence by 41.2\%. This study presents a low-exposure, high-efficiency paradigm for federated backdoor attacks and expands the application of fractal features in adversarial sample generation.
Hierarchical Split Federated Learning: Convergence Analysis and System Optimization
Dec 10, 2024



As AI models expand in size, it has become increasingly challenging to deploy federated learning (FL) on resource-constrained edge devices. To tackle this issue, split federated learning (SFL) has emerged as an FL framework with reduced workload on edge devices via model splitting; it has received extensive attention from the research community in recent years. Nevertheless, most prior works on SFL focus only on a two-tier architecture without harnessing multi-tier cloudedge computing resources. In this paper, we intend to analyze and optimize the learning performance of SFL under multi-tier systems. Specifically, we propose the hierarchical SFL (HSFL) framework and derive its convergence bound. Based on the theoretical results, we formulate a joint optimization problem for model splitting (MS) and model aggregation (MA). To solve this rather hard problem, we then decompose it into MS and MA subproblems that can be solved via an iterative descending algorithm. Simulation results demonstrate that the tailored algorithm can effectively optimize MS and MA for SFL within virtually any multi-tier system.
What Roles can Spatial Modulation and Space Shift Keying Play in LEO Satellite-Assisted Communication?
Sep 26, 2024



In recent years, the rapid evolution of satellite communications play a pivotal role in addressing the ever-increasing demand for global connectivity, among which the Low Earth Orbit (LEO) satellites attract a great amount of attention due to their low latency and high data throughput capabilities. Based on this, we explore spatial modulation (SM) and space shift keying (SSK) designs as pivotal techniques to enhance spectral efficiency (SE) and bit-error rate (BER) performance in the LEO satellite-assisted multiple-input multiple-output (MIMO) systems. The various performance analysis of these designs are presented in this paper, revealing insightful findings and conclusions through analytical methods and Monte Carlo simulations with perfect and imperfect channel state information (CSI) estimation. The results provide a comprehensive analysis of the merits and trade-offs associated with the investigated schemes, particularly in terms of BER, computational complexity, and SE. This analysis underscores the potential of both schemes as viable candidates for future 6G LEO satellite-assisted wireless communication systems.
Computational Complexity-Constrained Spectral Efficiency Analysis for 6G Waveforms
Jul 08, 2024
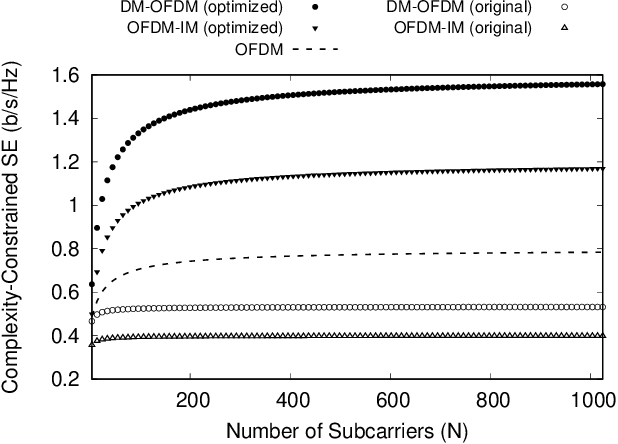
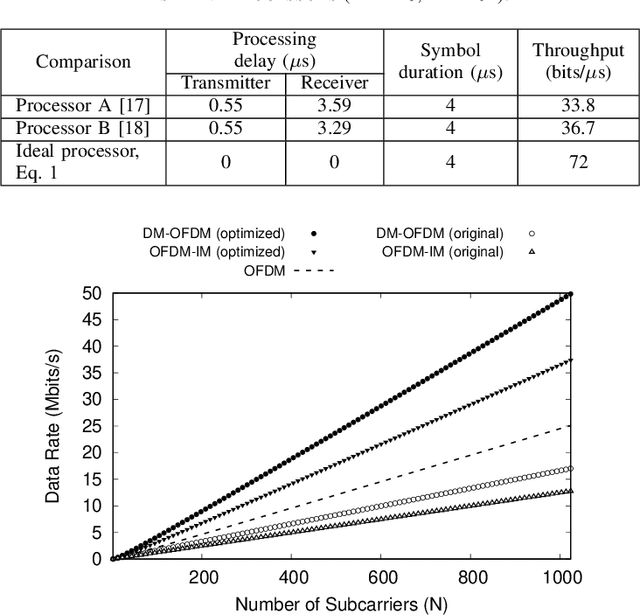
In this work, we present a tutorial on how to account for the computational time complexity overhead of signal processing in the spectral efficiency (SE) analysis of wireless waveforms. Our methodology is particularly relevant in scenarios where achieving higher SE entails a penalty in complexity, a common trade-off present in 6G candidate waveforms. We consider that SE derives from the data rate, which is impacted by time-dependent overheads. Thus, neglecting the computational complexity overhead in the SE analysis grants an unfair advantage to more computationally complex waveforms, as they require larger computational resources to meet a signal processing runtime below the symbol period. We demonstrate our points with two case studies. In the first, we refer to IEEE 802.11a-compliant baseband processors from the literature to show that their runtime significantly impacts the SE perceived by upper layers. In the second case study, we show that waveforms considered less efficient in terms of SE can outperform their more computationally expensive counterparts if provided with equivalent high-performance computational resources. Based on these cases, we believe our tutorial can address the comparative SE analysis of waveforms that operate under different computational resource constraints.
Maximum Channel Coding Rate of Finite Block Length MIMO Faster-Than-Nyquist Signaling
Mar 13, 2024The pursuit of higher data rates and efficient spectrum utilization in modern communication technologies necessitates novel solutions. In order to provide insights into improving spectral efficiency and reducing latency, this study investigates the maximum channel coding rate (MCCR) of finite block length (FBL) multiple-input multiple-output (MIMO) faster-than-Nyquist (FTN) channels. By optimizing power allocation, we derive the system's MCCR expression. Simulation results are compared with the existing literature to reveal the benefits of FTN in FBL transmission.
Category-wise Fine-Tuning: Resisting Incorrect Pseudo-Labels in Multi-Label Image Classification with Partial Labels
Jan 30, 2024



Large-scale image datasets are often partially labeled, where only a few categories' labels are known for each image. Assigning pseudo-labels to unknown labels to gain additional training signals has become prevalent for training deep classification models. However, some pseudo-labels are inevitably incorrect, leading to a notable decline in the model classification performance. In this paper, we propose a novel method called Category-wise Fine-Tuning (CFT), aiming to reduce model inaccuracies caused by the wrong pseudo-labels. In particular, CFT employs known labels without pseudo-labels to fine-tune the logistic regressions of trained models individually to calibrate each category's model predictions. Genetic Algorithm, seldom used for training deep models, is also utilized in CFT to maximize the classification performance directly. CFT is applied to well-trained models, unlike most existing methods that train models from scratch. Hence, CFT is general and compatible with models trained with different methods and schemes, as demonstrated through extensive experiments. CFT requires only a few seconds for each category for calibration with consumer-grade GPUs. We achieve state-of-the-art results on three benchmarking datasets, including the CheXpert chest X-ray competition dataset (ensemble mAUC 93.33%, single model 91.82%), partially labeled MS-COCO (average mAP 83.69%), and Open Image V3 (mAP 85.31%), outperforming the previous bests by 0.28%, 2.21%, 2.50%, and 0.91%, respectively. The single model on CheXpert has been officially evaluated by the competition server, endorsing the correctness of the result. The outstanding results and generalizability indicate that CFT could be substantial and prevalent for classification model development. Code is available at: https://github.com/maxium0526/category-wise-fine-tuning.
Distance Guided Generative Adversarial Network for Explainable Binary Classifications
Dec 29, 2023Despite the potential benefits of data augmentation for mitigating the data insufficiency, traditional augmentation methods primarily rely on the prior intra-domain knowledge. On the other hand, advanced generative adversarial networks (GANs) generate inter-domain samples with limited variety. These previous methods make limited contributions to describing the decision boundaries for binary classification. In this paper, we propose a distance guided GAN (DisGAN) which controls the variation degrees of generated samples in the hyperplane space. Specifically, we instantiate the idea of DisGAN by combining two ways. The first way is vertical distance GAN (VerDisGAN) where the inter-domain generation is conditioned on the vertical distances. The second way is horizontal distance GAN (HorDisGAN) where the intra-domain generation is conditioned on the horizontal distances. Furthermore, VerDisGAN can produce the class-specific regions by mapping the source images to the hyperplane. Experimental results show that DisGAN consistently outperforms the GAN-based augmentation methods with explainable binary classification. The proposed method can apply to different classification architectures and has potential to extend to multi-class classification.