 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffKD-DCIS: Predicting Upgrade of Ductal Carcinoma In Situ with Diffusion Augmentation and Knowledge Distillation
Jan 04, 2026Accurately predicting the upgrade of ductal carcinoma in situ (DCIS) to invasive ductal carcinoma (IDC) is crucial for surgical planning. However, traditional deep learning methods face challenges due to limited ultrasound data and poor generalization ability. This study proposes the DiffKD-DCIS framework, integrating conditional diffusion modeling with teacher-student knowledge distillation. The framework operates in three stages: First, a conditional diffusion model generates high-fidelity ultrasound images using multimodal conditions for data augmentation. Then, a deep teacher network extracts robust features from both original and synthetic data. Finally, a compact student network learns from the teacher via knowledge distillation, balancing generalization and computational efficiency. Evaluated on a multi-center dataset of 1,435 cases, the synthetic images were of good quality. The student network had fewer parameters and faster inference. On external test sets, it outperformed partial combinations, and its accuracy was comparable to senior radiologists and superior to junior ones, showing significant clinical potential.
Towards unlocking the mystery of adversarial fragility of neural networks
Jun 23, 2024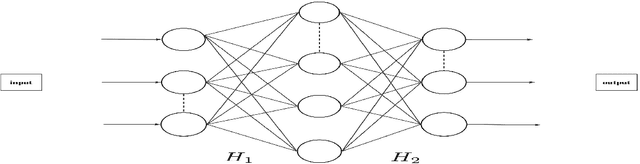
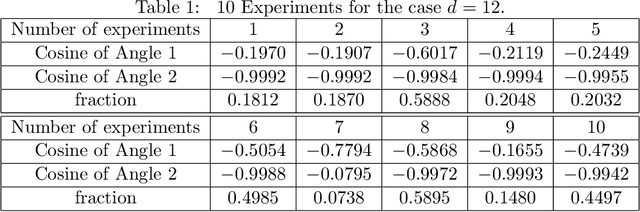
In this paper, we study the adversarial robustness of deep neural networks for classification tasks. We look at the smallest magnitude of possible additive perturbations that can change the output of a classification algorithm. We provide a matrix-theoretic explanation of the adversarial fragility of deep neural network for classification. In particular, our theoretical results show that neural network's adversarial robustness can degrade as the input dimension $d$ increases. Analytically we show that neural networks' adversarial robustness can be only $1/\sqrt{d}$ of the best possible adversarial robustness. Our matrix-theoretic explanation is consistent with an earlier information-theoretic feature-compression-based explanation for the adversarial fragility of neural networks.
Distance Guided Generative Adversarial Network for Explainable Binary Classifications
Dec 29, 2023Despite the potential benefits of data augmentation for mitigating the data insufficiency, traditional augmentation methods primarily rely on the prior intra-domain knowledge. On the other hand, advanced generative adversarial networks (GANs) generate inter-domain samples with limited variety. These previous methods make limited contributions to describing the decision boundaries for binary classification. In this paper, we propose a distance guided GAN (DisGAN) which controls the variation degrees of generated samples in the hyperplane space. Specifically, we instantiate the idea of DisGAN by combining two ways. The first way is vertical distance GAN (VerDisGAN) where the inter-domain generation is conditioned on the vertical distances. The second way is horizontal distance GAN (HorDisGAN) where the intra-domain generation is conditioned on the horizontal distances. Furthermore, VerDisGAN can produce the class-specific regions by mapping the source images to the hyperplane. Experimental results show that DisGAN consistently outperforms the GAN-based augmentation methods with explainable binary classification. The proposed method can apply to different classification architectures and has potential to extend to multi-class classification.
gcDLSeg: Integrating Graph-cut into Deep Learning for Binary Semantic Segmentation
Dec 07, 2023



Binary semantic segmentation in computer vision is a fundamental problem. As a model-based segmentation method, the graph-cut approach was one of the most successful binary segmentation methods thanks to its global optimality guarantee of the solutions and its practical polynomial-time complexity. Recently, many deep learning (DL) based methods have been developed for this task and yielded remarkable performance, resulting in a paradigm shift in this field. To combine the strengths of both approaches, we propose in this study to integrate the graph-cut approach into a deep learning network for end-to-end learning. Unfortunately, backward propagation through the graph-cut module in the DL network is challenging due to the combinatorial nature of the graph-cut algorithm. To tackle this challenge, we propose a novel residual graph-cut loss and a quasi-residual connection, enabling the backward propagation of the gradients of the residual graph-cut loss for effective feature learning guided by the graph-cut segmentation model. In the inference phase, globally optimal segmentation is achieved with respect to the graph-cut energy defined on the optimized image features learned from DL networks. Experiments on the public AZH chronic wound data set and the pancreas cancer data set from the medical segmentation decathlon (MSD) demonstrated promising segmentation accuracy, and improved robustness against adversarial attacks.
A deep learning network with differentiable dynamic programming for retina OCT surface segmentation
Oct 08, 2022
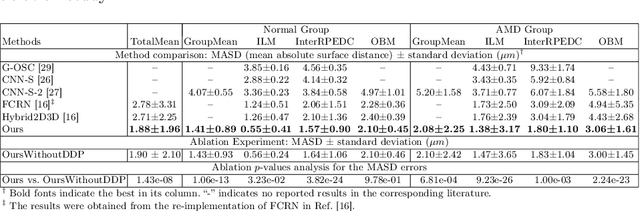
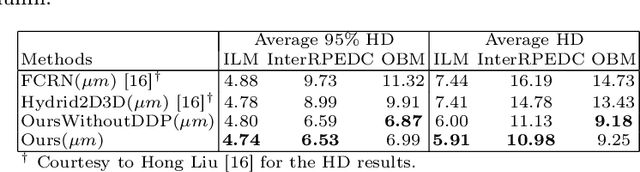
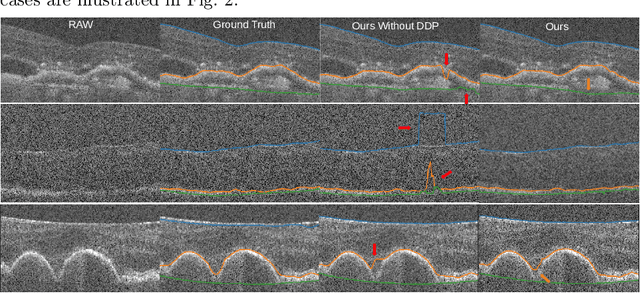
Multiple-surface segmentation in Optical Coherence Tomography (OCT) images is a challenge problem, further complicated by the frequent presence of weak image boundaries. Recently, many deep learning (DL) based methods have been developed for this task and yield remarkable performance. Unfortunately, due to the scarcity of training data in medical imaging, it is challenging for DL networks to learn the global structure of the target surfaces, including surface smoothness. To bridge this gap, this study proposes to seamlessly unify a U-Net for feature learning with a constrained differentiable dynamic programming module to achieve an end-to-end learning for retina OCT surface segmentation to explicitly enforce surface smoothness. It effectively utilizes the feedback from the downstream model optimization module to guide feature learning, yielding a better enforcement of global structures of the target surfaces. Experiments on Duke AMD (age-related macular degeneration) and JHU MS (multiple sclerosis) OCT datasets for retinal layer segmentation demonstrated very promising segmentation accuracy.
End to end hyperspectral imaging system with coded compression imaging process
Sep 06, 2021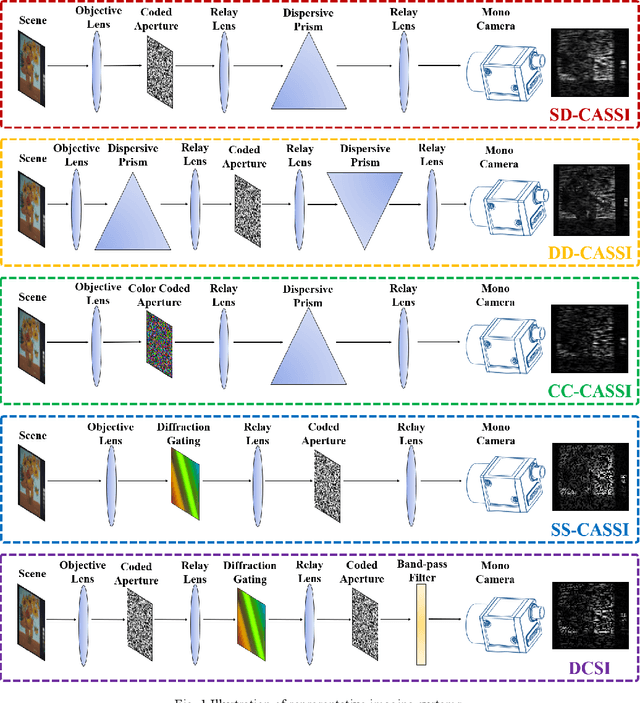

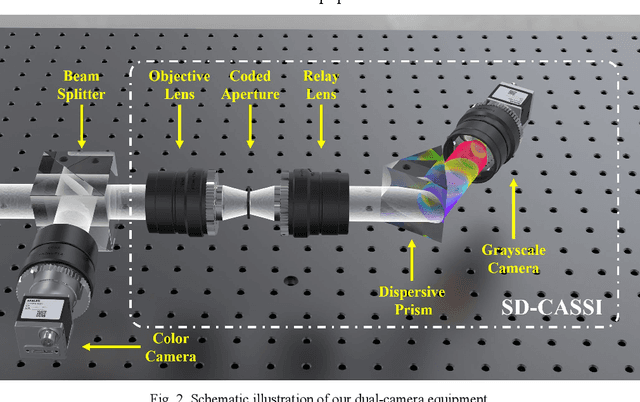

Hyperspectral images (HSIs) can provide rich spatial and spectral information with extensive application prospects. Recently, several methods using convolutional neural networks (CNNs) to reconstruct HSIs have been developed. However, most deep learning methods fit a brute-force mapping relationship between the compressive and standard HSIs. Thus, the learned mapping would be invalid when the observation data deviate from the training data. To recover the three-dimensional HSIs from two-dimensional compressive images, we present dual-camera equipment with a physics-informed self-supervising CNN method based on a coded aperture snapshot spectral imaging system. Our method effectively exploits the spatial-spectral relativization from the coded spectral information and forms a self-supervising system based on the camera quantum effect model. The experimental results show that our method can be adapted to a wide imaging environment with good performance. In addition, compared with most of the network-based methods, our system does not require a dedicated dataset for pre-training. Therefore, it has greater scenario adaptability and better generalization ability. Meanwhile, our system can be constantly fine-tuned and self-improved in real-life scenarios.
Globally Optimal Segmentation of Mutually Interacting Surfaces using Deep Learning
Jul 15, 2020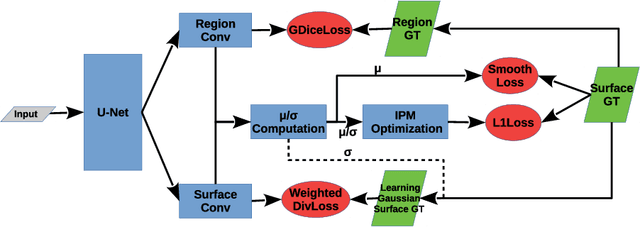
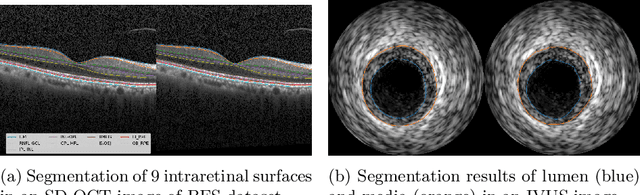
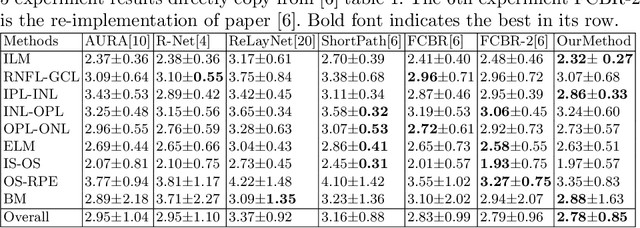

Segmentation of multiple surfaces in medical images is a challenging problem, further complicated by the frequent presence of weak boundary and mutual influence between adjacent objects. The traditional graph-based optimal surface segmentation method has proven its effectiveness with its ability of capturing various surface priors in a uniform graph model. However, its efficacy heavily relies on handcrafted features that are used to define the surface cost for the "goodness" of a surface. Recently, deep learning (DL) is emerging as powerful tools for medical image segmentation thanks to its superior feature learning capability. Unfortunately, due to the scarcity of training data in medical imaging, it is nontrivial for DL networks to implicitly learn the global structure of the target surfaces, including surface interactions. In this work, we propose to parameterize the surface cost functions in the graph model and leverage DL to learn those parameters. The multiple optimal surfaces are then simultaneously detected by minimizing the total surface cost while explicitly enforcing the mutual surface interaction constraints. The optimization problem is solved by the primal-dual Internal Point Method, which can be implemented by a layer of neural networks, enabling efficient end-to-end training of the whole network. Experiments on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results. All source code is public to facilitate further research at this direction.
Trust but Verify: An Information-Theoretic Explanation for the Adversarial Fragility of Machine Learning Systems, and a General Defense against Adversarial Attacks
May 25, 2019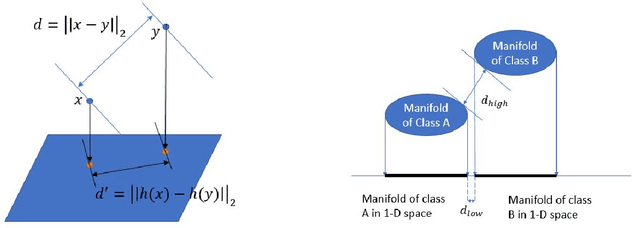
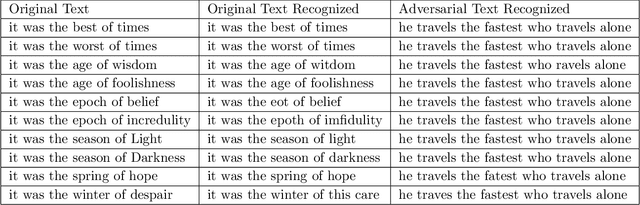
Deep-learning based classification algorithms have been shown to be susceptible to adversarial attacks: minor changes to the input of classifiers can dramatically change their outputs, while being imperceptible to humans. In this paper, we present a simple hypothesis about a feature compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. Drawing on ideas from information and coding theory, we propose a general class of defenses for detecting classifier errors caused by abnormally small input perturbations. We further show theoretical guarantees for the performance of this detection method. We present experimental results with (a) a voice recognition system, and (b) a digit recognition system using the MNIST database, to demonstrate the effectiveness of the proposed defense methods. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.
An Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers
Jan 27, 2019
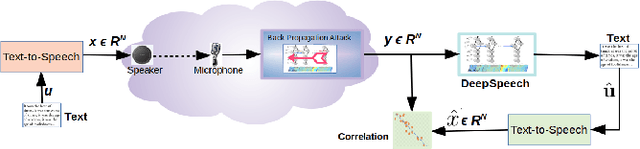
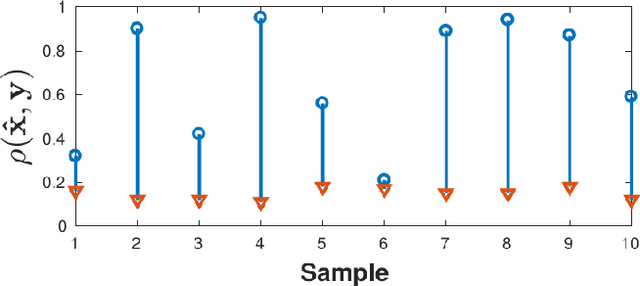
We present a simple hypothesis about a compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. We also propose a new method for detecting when small input perturbations cause classifier errors, and show theoretical guarantees for the performance of this detection method. We present experimental results with a voice recognition system to demonstrate this method. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.