Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers
Paper and Code
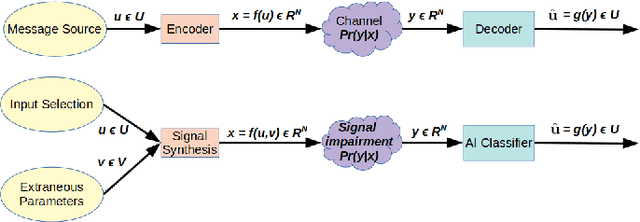
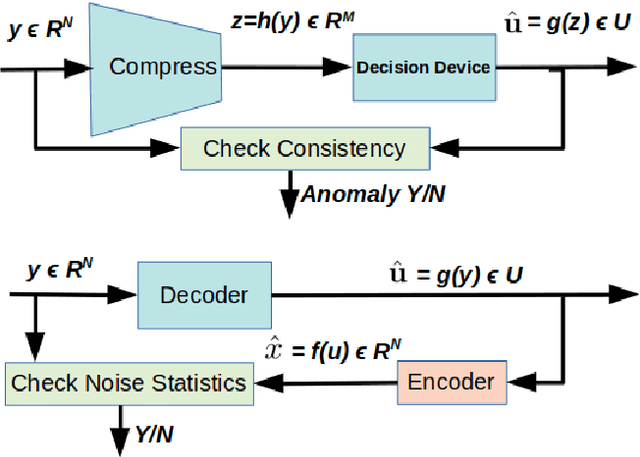
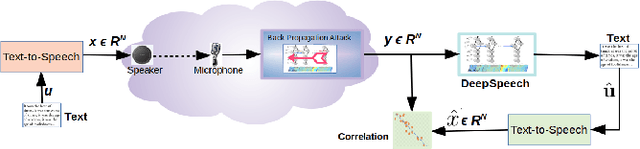
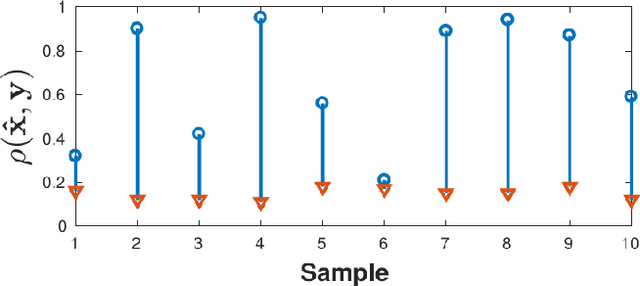
We present a simple hypothesis about a compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. We also propose a new method for detecting when small input perturbations cause classifier errors, and show theoretical guarantees for the performance of this detection method. We present experimental results with a voice recognition system to demonstrate this method. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.
* 5 pages
View paper on