 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards unlocking the mystery of adversarial fragility of neural networks
Jun 23, 2024
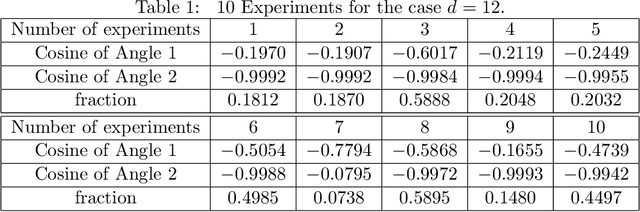
In this paper, we study the adversarial robustness of deep neural networks for classification tasks. We look at the smallest magnitude of possible additive perturbations that can change the output of a classification algorithm. We provide a matrix-theoretic explanation of the adversarial fragility of deep neural network for classification. In particular, our theoretical results show that neural network's adversarial robustness can degrade as the input dimension $d$ increases. Analytically we show that neural networks' adversarial robustness can be only $1/\sqrt{d}$ of the best possible adversarial robustness. Our matrix-theoretic explanation is consistent with an earlier information-theoretic feature-compression-based explanation for the adversarial fragility of neural networks.
gcDLSeg: Integrating Graph-cut into Deep Learning for Binary Semantic Segmentation
Dec 07, 2023



Binary semantic segmentation in computer vision is a fundamental problem. As a model-based segmentation method, the graph-cut approach was one of the most successful binary segmentation methods thanks to its global optimality guarantee of the solutions and its practical polynomial-time complexity. Recently, many deep learning (DL) based methods have been developed for this task and yielded remarkable performance, resulting in a paradigm shift in this field. To combine the strengths of both approaches, we propose in this study to integrate the graph-cut approach into a deep learning network for end-to-end learning. Unfortunately, backward propagation through the graph-cut module in the DL network is challenging due to the combinatorial nature of the graph-cut algorithm. To tackle this challenge, we propose a novel residual graph-cut loss and a quasi-residual connection, enabling the backward propagation of the gradients of the residual graph-cut loss for effective feature learning guided by the graph-cut segmentation model. In the inference phase, globally optimal segmentation is achieved with respect to the graph-cut energy defined on the optimized image features learned from DL networks. Experiments on the public AZH chronic wound data set and the pancreas cancer data set from the medical segmentation decathlon (MSD) demonstrated promising segmentation accuracy, and improved robustness against adversarial attacks.
Optimal Cost Constrained Adversarial Attacks For Multiple Agent Systems
Nov 01, 2023


Finding optimal adversarial attack strategies is an important topic in reinforcement learning and the Markov decision process. Previous studies usually assume one all-knowing coordinator (attacker) for whom attacking different recipient (victim) agents incurs uniform costs. However, in reality, instead of using one limitless central attacker, the attacks often need to be performed by distributed attack agents. We formulate the problem of performing optimal adversarial agent-to-agent attacks using distributed attack agents, in which we impose distinct cost constraints on each different attacker-victim pair. We propose an optimal method integrating within-step static constrained attack-resource allocation optimization and between-step dynamic programming to achieve the optimal adversarial attack in a multi-agent system. Our numerical results show that the proposed attacks can significantly reduce the rewards received by the attacked agents.
Trust, but Verify: Robust Image Segmentation using Deep Learning
Oct 29, 2023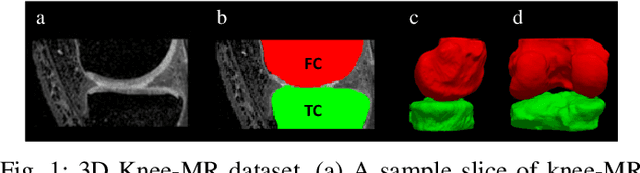
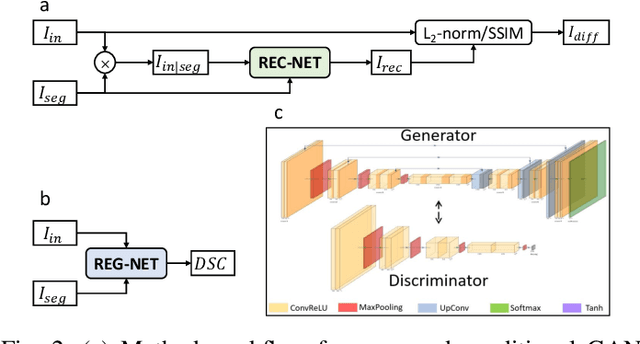
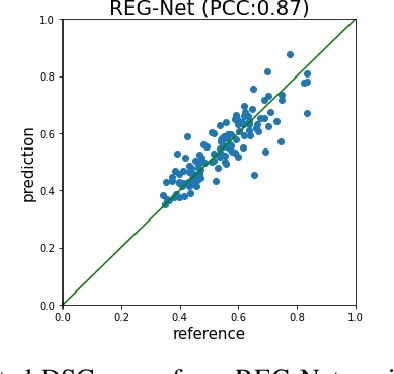

We describe a method for verifying the output of a deep neural network for medical image segmentation that is robust to several classes of random as well as worst-case perturbations i.e. adversarial attacks. This method is based on a general approach recently developed by the authors called "Trust, but Verify" wherein an auxiliary verification network produces predictions about certain masked features in the input image using the segmentation as an input. A well-designed auxiliary network will produce high-quality predictions when the input segmentations are accurate, but will produce low-quality predictions when the segmentations are incorrect. Checking the predictions of such a network with the original image allows us to detect bad segmentations. However, to ensure the verification method is truly robust, we need a method for checking the quality of the predictions that does not itself rely on a black-box neural network. Indeed, we show that previous methods for segmentation evaluation that do use deep neural regression networks are vulnerable to false negatives i.e. can inaccurately label bad segmentations as good. We describe the design of a verification network that avoids such vulnerability and present results to demonstrate its robustness compared to previous methods.
Outlier Detection Using Generative Models with Theoretical Performance Guarantees
Oct 16, 2023

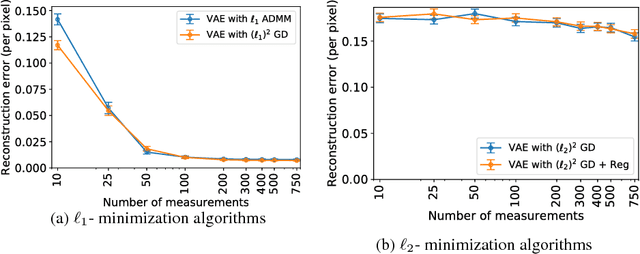
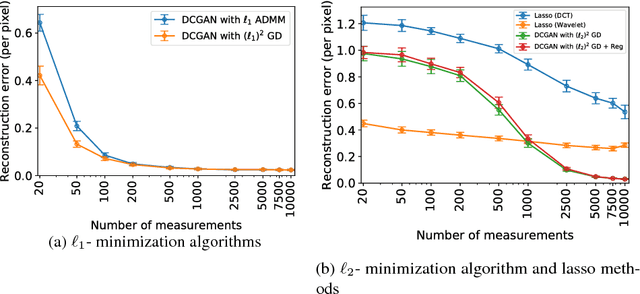
This paper considers the problem of recovering signals modeled by generative models from linear measurements contaminated with sparse outliers. We propose an outlier detection approach for reconstructing the ground-truth signals modeled by generative models under sparse outliers. We establish theoretical recovery guarantees for reconstruction of signals using generative models in the presence of outliers, giving lower bounds on the number of correctable outliers. Our results are applicable to both linear generator neural networks and the nonlinear generator neural networks with an arbitrary number of layers. We propose an iterative alternating direction method of multipliers (ADMM) algorithm for solving the outlier detection problem via $\ell_1$ norm minimization, and a gradient descent algorithm for solving the outlier detection problem via squared $\ell_1$ norm minimization. We conduct extensive experiments using variational auto-encoder and deep convolutional generative adversarial networks, and the experimental results show that the signals can be successfully reconstructed under outliers using our approach. Our approach outperforms the traditional Lasso and $\ell_2$ minimization approach.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023

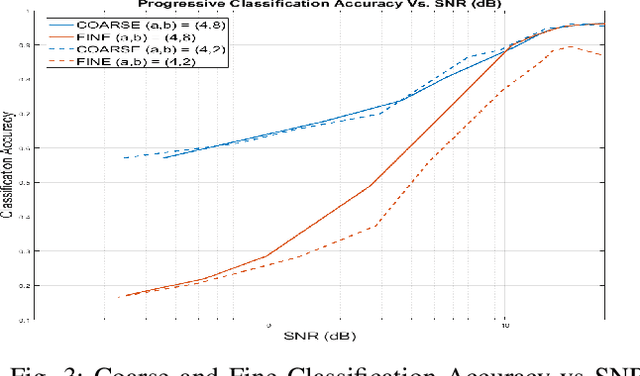

We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
Distributed Dual Coordinate Ascent with Imbalanced Data on a General Tree Network
Aug 28, 2023
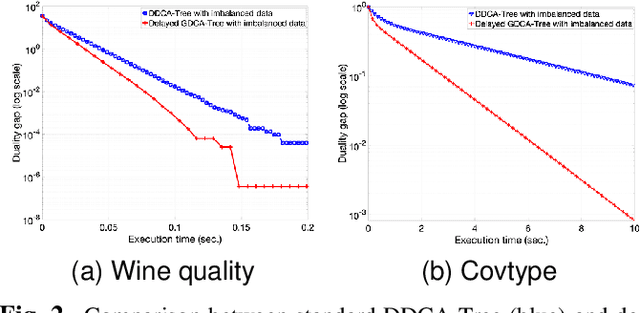
In this paper, we investigate the impact of imbalanced data on the convergence of distributed dual coordinate ascent in a tree network for solving an empirical loss minimization problem in distributed machine learning. To address this issue, we propose a method called delayed generalized distributed dual coordinate ascent that takes into account the information of the imbalanced data, and provide the analysis of the proposed algorithm. Numerical experiments confirm the effectiveness of our proposed method in improving the convergence speed of distributed dual coordinate ascent in a tree network.
To AI or not to AI, to Buy Local or not to Buy Local: A Mathematical Theory of Real Price
May 09, 2023


In the past several decades, the world's economy has become increasingly globalized. On the other hand, there are also ideas advocating the practice of ``buy local'', by which people buy locally produced goods and services rather than those produced farther away. In this paper, we establish a mathematical theory of real price that determines the optimal global versus local spending of an agent which achieves the agent's optimal tradeoff between spending and obtained utility. Our theory of real price depends on the asymptotic analysis of a Markov chain transition probability matrix related to the network of producers and consumers. We show that the real price of a product or service can be determined from the involved Markov chain matrix, and can be dramatically different from the product's label price. In particular, we show that the label prices of products and services are often not ``real'' or directly ``useful'': given two products offering the same myopic utility, the one with lower label price may not necessarily offer better asymptotic utility. This theory shows that the globality or locality of the products and services does have different impacts on the spending-utility tradeoff of a customer. The established mathematical theory of real price can be used to determine whether to adopt or not to adopt certain artificial intelligence (AI) technologies from an economic perspective.
Optimal Compression for Minimizing Classification Error Probability: an Information-Theoretic Approach
Nov 03, 2022We formulate the problem of performing optimal data compression under the constraints that compressed data can be used for accurate classification in machine learning. We show that this translates to a problem of minimizing the mutual information between data and its compressed version under the constraint on error probability of classification is small when using the compressed data for machine learning. We then provide analytical and computational methods to characterize the optimal trade-off between data compression and classification error probability. First, we provide an analytical characterization for the optimal compression strategy for data with binary labels. Second, for data with multiple labels, we formulate a set of convex optimization problems to characterize the optimal tradeoff, from which the optimal trade-off between the classification error and compression efficiency can be obtained by numerically solving the formulated optimization problems. We further show the improvements of our formulations over the information-bottleneck methods in classification performance.
A deep learning network with differentiable dynamic programming for retina OCT surface segmentation
Oct 08, 2022
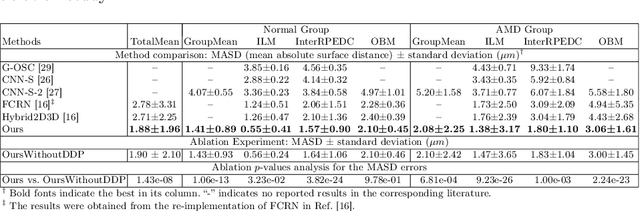
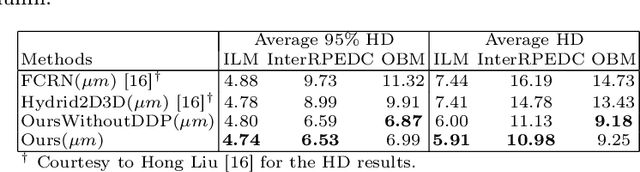
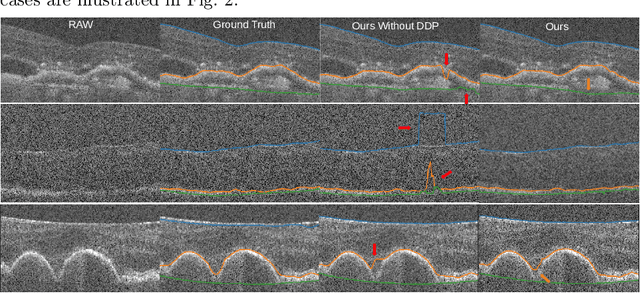
Multiple-surface segmentation in Optical Coherence Tomography (OCT) images is a challenge problem, further complicated by the frequent presence of weak image boundaries. Recently, many deep learning (DL) based methods have been developed for this task and yield remarkable performance. Unfortunately, due to the scarcity of training data in medical imaging, it is challenging for DL networks to learn the global structure of the target surfaces, including surface smoothness. To bridge this gap, this study proposes to seamlessly unify a U-Net for feature learning with a constrained differentiable dynamic programming module to achieve an end-to-end learning for retina OCT surface segmentation to explicitly enforce surface smoothness. It effectively utilizes the feedback from the downstream model optimization module to guide feature learning, yielding a better enforcement of global structures of the target surfaces. Experiments on Duke AMD (age-related macular degeneration) and JHU MS (multiple sclerosis) OCT datasets for retinal layer segmentation demonstrated very promising segmentation accuracy.