 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Provably Implement In-Context Reinforcement Learning with Policy Improvement
May 07, 2026We investigate the ability of transformers to perform in-context reinforcement learning (ICRL), where a model must infer and execute learning algorithms from trajectory data without parameter updates. We show that a linear self-attention transformer block can provably implement policy-improvement methods, including semi-gradient SARSA and actor-critic, via explicit parameter constructions. Beyond existence, we design a teacher-mimicking training procedure, analyze its gradient-flow dynamics, and establish the first convergence guarantee in the ICRL literature: under suitable richness conditions on the training MDP distribution, gradient flow converges locally and exponentially to an optimal parameter manifold corresponding to the desired RL update. Empirically, training transformers on randomly generated tabular MDPs confirms these predictions: the learned models recover the parameter structure of our explicit constructions and, when deployed on unseen MDPs, deliver strong in-context control performance. Together, these results illuminate how transformer architectures internalize and execute classical reinforcement learning algorithms in context, bridging mechanistic understanding and training dynamics in ICRL.
Efficient Preference Poisoning Attack on Offline RLHF
May 04, 2026Offline Reinforcement Learning from Human Feedback (RLHF) pipelines such as Direct Preference Optimization (DPO) train on a pre-collected preference dataset, which makes them vulnerable to preference poisoning attack. We study label flip attacks against log-linear DPO. We first illustrate that flipping one preference label induces a parameter-independent shift in the DPO gradient. Using this key property, we can then convert the targeted poisoning problem into a structured binary sparse approximation problem. To solve this problem, we develop two attack methods: Binary-Aware Lattice Attack (BAL-A) and Binary Matching Pursuit Attack (BMP-A). BAL-A embeds the binary flip selection problem into a binary-aware lattice and applies Lenstra-Lenstra-Lovász reduction and Babai's nearest plane algorithm; we provide sufficient conditions that enforce binary coefficients and recover the minimum-flip objective. BMP-A adapts binary matching pursuit to our non-normalized gradient dictionary and yields coherence-based recovery guarantees and robustness (impossibility) certificates for $K$-flip budgets. Experiments on synthetic dictionaries and the Stanford Human Preferences dataset validate the theory and highlight how dictionary geometry governs attack success.
Provable In-context Learning for Mixture of Linear Regressions using Transformers
Oct 18, 2024We theoretically investigate the in-context learning capabilities of transformers in the context of learning mixtures of linear regression models. For the case of two mixtures, we demonstrate the existence of transformers that can achieve an accuracy, relative to the oracle predictor, of order $\mathcal{\tilde{O}}((d/n)^{1/4})$ in the low signal-to-noise ratio (SNR) regime and $\mathcal{\tilde{O}}(\sqrt{d/n})$ in the high SNR regime, where $n$ is the length of the prompt, and $d$ is the dimension of the problem. Additionally, we derive in-context excess risk bounds of order $\mathcal{O}(L/\sqrt{B})$, where $B$ denotes the number of (training) prompts, and $L$ represents the number of attention layers. The order of $L$ depends on whether the SNR is low or high. In the high SNR regime, we extend the results to $K$-component mixture models for finite $K$. Extensive simulations also highlight the advantages of transformers for this task, outperforming other baselines such as the Expectation-Maximization algorithm.
Transformers Handle Endogeneity in In-Context Linear Regression
Oct 02, 2024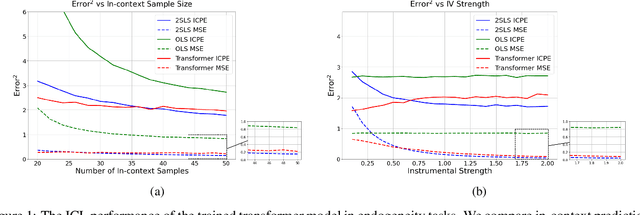
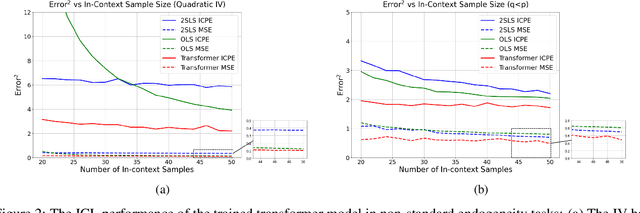
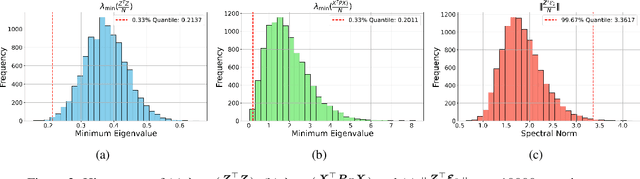
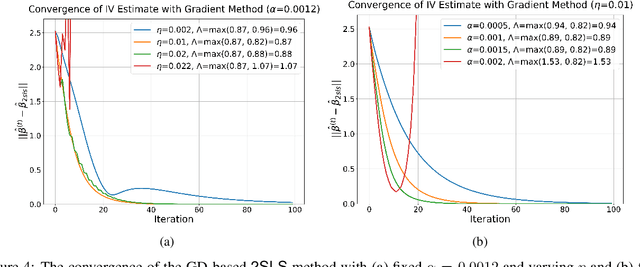
We explore the capability of transformers to address endogeneity in in-context linear regression. Our main finding is that transformers inherently possess a mechanism to handle endogeneity effectively using instrumental variables (IV). First, we demonstrate that the transformer architecture can emulate a gradient-based bi-level optimization procedure that converges to the widely used two-stage least squares $(\textsf{2SLS})$ solution at an exponential rate. Next, we propose an in-context pretraining scheme and provide theoretical guarantees showing that the global minimizer of the pre-training loss achieves a small excess loss. Our extensive experiments validate these theoretical findings, showing that the trained transformer provides more robust and reliable in-context predictions and coefficient estimates than the $\textsf{2SLS}$ method, in the presence of endogeneity.
Distributed Dual Coordinate Ascent with Imbalanced Data on a General Tree Network
Aug 28, 2023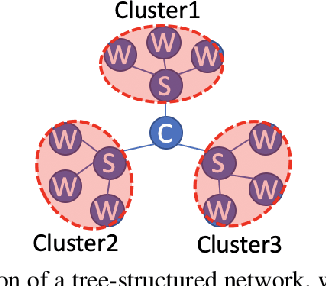
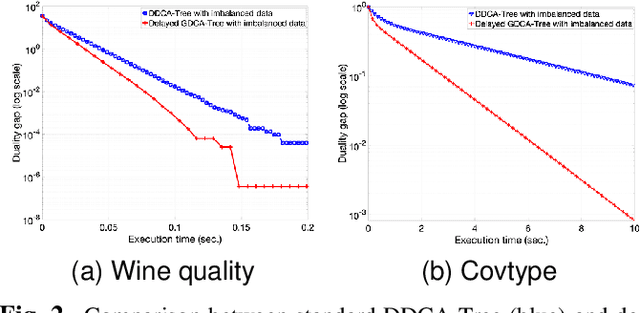
In this paper, we investigate the impact of imbalanced data on the convergence of distributed dual coordinate ascent in a tree network for solving an empirical loss minimization problem in distributed machine learning. To address this issue, we propose a method called delayed generalized distributed dual coordinate ascent that takes into account the information of the imbalanced data, and provide the analysis of the proposed algorithm. Numerical experiments confirm the effectiveness of our proposed method in improving the convergence speed of distributed dual coordinate ascent in a tree network.
Minimax Optimal $Q$ Learning with Nearest Neighbors
Aug 03, 2023



$Q$ learning is a popular model free reinforcement learning method. Most of existing works focus on analyzing $Q$ learning for finite state and action spaces. If the state space is continuous, then the original $Q$ learning method can not be directly used. A modification of the original $Q$ learning method was proposed in (Shah and Xie, 2018), which estimates $Q$ values with nearest neighbors. Such modification makes $Q$ learning suitable for continuous state space. (Shah and Xie, 2018) shows that the convergence rate of estimated $Q$ function is $\tilde{O}(T^{-1/(d+3)})$, which is slower than the minimax lower bound $\tilde{\Omega}(T^{-1/(d+2)})$, indicating that this method is not efficient. This paper proposes two new $Q$ learning methods to bridge the gap of convergence rates in (Shah and Xie, 2018), with one of them being offline, while the other is online. Despite that we still use nearest neighbor approach to estimate $Q$ function, the algorithms are crucially different from (Shah and Xie, 2018). In particular, we replace the kernel nearest neighbor in discretized region with a direct nearest neighbor approach. Consequently, our approach significantly improves the convergence rate. Moreover, the time complexity is also significantly improved in high dimensional state spaces. Our analysis shows that both offline and online methods are minimax rate optimal.
Efficient Action Robust Reinforcement Learning with Probabilistic Policy Execution Uncertainty
Jul 20, 2023
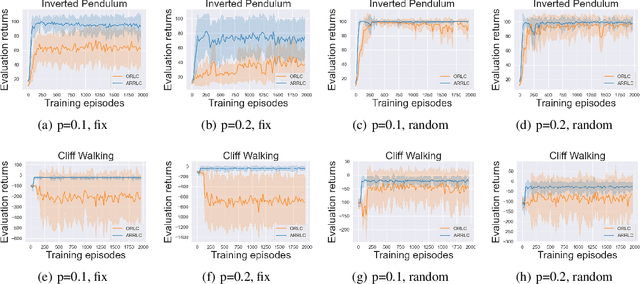
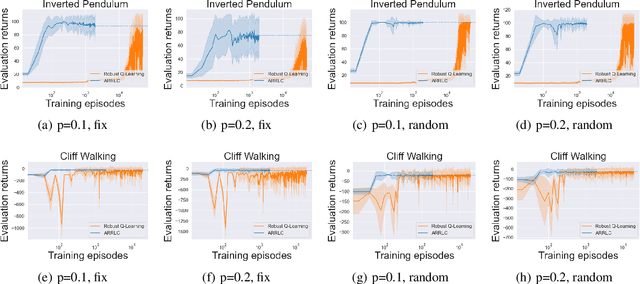
Robust reinforcement learning (RL) aims to find a policy that optimizes the worst-case performance in the face of uncertainties. In this paper, we focus on action robust RL with the probabilistic policy execution uncertainty, in which, instead of always carrying out the action specified by the policy, the agent will take the action specified by the policy with probability $1-\rho$ and an alternative adversarial action with probability $\rho$. We establish the existence of an optimal policy on the action robust MDPs with probabilistic policy execution uncertainty and provide the action robust Bellman optimality equation for its solution. Furthermore, we develop Action Robust Reinforcement Learning with Certificates (ARRLC) algorithm that achieves minimax optimal regret and sample complexity. Furthermore, we conduct numerical experiments to validate our approach's robustness, demonstrating that ARRLC outperforms non-robust RL algorithms and converges faster than the robust TD algorithm in the presence of action perturbations.
Efficient Adversarial Attacks on Online Multi-agent Reinforcement Learning
Jul 15, 2023



Due to the broad range of applications of multi-agent reinforcement learning (MARL), understanding the effects of adversarial attacks against MARL model is essential for the safe applications of this model. Motivated by this, we investigate the impact of adversarial attacks on MARL. In the considered setup, there is an exogenous attacker who is able to modify the rewards before the agents receive them or manipulate the actions before the environment receives them. The attacker aims to guide each agent into a target policy or maximize the cumulative rewards under some specific reward function chosen by the attacker, while minimizing the amount of manipulation on feedback and action. We first show the limitations of the action poisoning only attacks and the reward poisoning only attacks. We then introduce a mixed attack strategy with both the action poisoning and the reward poisoning. We show that the mixed attack strategy can efficiently attack MARL agents even if the attacker has no prior information about the underlying environment and the agents' algorithms.
Fairness-aware Regression Robust to Adversarial Attacks
Nov 04, 2022

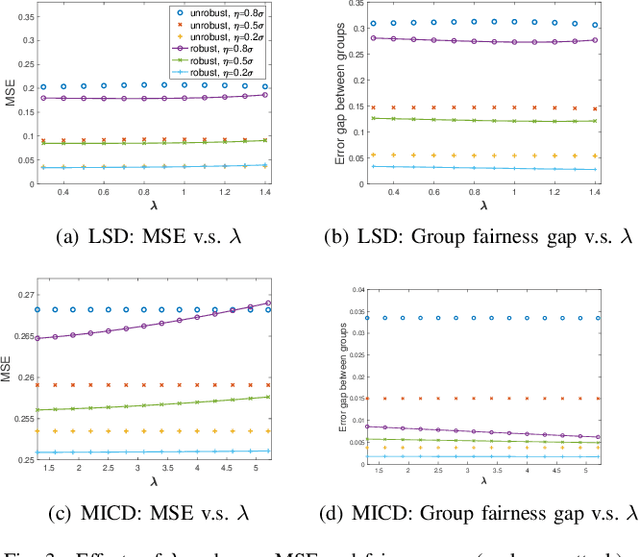

In this paper, we take a first step towards answering the question of how to design fair machine learning algorithms that are robust to adversarial attacks. Using a minimax framework, we aim to design an adversarially robust fair regression model that achieves optimal performance in the presence of an attacker who is able to add a carefully designed adversarial data point to the dataset or perform a rank-one attack on the dataset. By solving the proposed nonsmooth nonconvex-nonconcave minimax problem, the optimal adversary as well as the robust fairness-aware regression model are obtained. For both synthetic data and real-world datasets, numerical results illustrate that the proposed adversarially robust fair models have better performance on poisoned datasets than other fair machine learning models in both prediction accuracy and group-based fairness measure.
Efficiently Escaping Saddle Points in Bilevel Optimization
Feb 08, 2022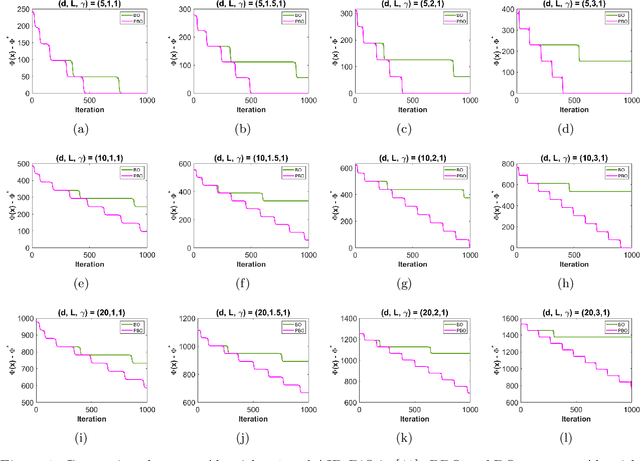
Bilevel optimization is one of the fundamental problems in machine learning and optimization. Recent theoretical developments in bilevel optimization focus on finding the first-order stationary points for nonconvex-strongly-convex cases. In this paper, we analyze algorithms that can escape saddle points in nonconvex-strongly-convex bilevel optimization. Specifically, we show that the perturbed approximate implicit differentiation (AID) with a warm start strategy finds $\epsilon$-approximate local minimum of bilevel optimization in $\tilde{O}(\epsilon^{-2})$ iterations with high probability. Moreover, we propose an inexact NEgative-curvature-Originated-from-Noise Algorithm (iNEON), a pure first-order algorithm that can escape saddle point and find local minimum of stochastic bilevel optimization. As a by-product, we provide the first nonasymptotic analysis of perturbed multi-step gradient descent ascent (GDmax) algorithm that converges to local minimax point for minimax problems.