 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeMFL-240K: A Large-scale Dataset and Benchmark for Object Detection in Pipeline Magnetic Flux Leakage Imaging
Feb 04, 2026Pipeline integrity is critical to industrial safety and environmental protection, with Magnetic Flux Leakage (MFL) detection being a primary non-destructive testing technology. Despite the promise of deep learning for automating MFL interpretation, progress toward reliable models has been constrained by the absence of a large-scale public dataset and benchmark, making fair comparison and reproducible evaluation difficult. We introduce \textbf{PipeMFL-240K}, a large-scale, meticulously annotated dataset and benchmark for complex object detection in pipeline MFL pseudo-color images. PipeMFL-240K reflects real-world inspection complexity and poses several unique challenges: (i) an extremely long-tailed distribution over \textbf{12} categories, (ii) a high prevalence of tiny objects that often comprise only a handful of pixels, and (iii) substantial intra-class variability. The dataset contains \textbf{240,320} images and \textbf{191,530} high-quality bounding-box annotations, collected from 11 pipelines spanning approximately \textbf{1,480} km. Extensive experiments are conducted with state-of-the-art object detectors to establish baselines. Results show that modern detectors still struggle with the intrinsic properties of MFL data, highlighting considerable headroom for improvement, while PipeMFL-240K provides a reliable and challenging testbed to drive future research. As the first public dataset and the first benchmark of this scale and scope for pipeline MFL inspection, it provides a critical foundation for efficient pipeline diagnostics as well as maintenance planning and is expected to accelerate algorithmic innovation and reproducible research in MFL-based pipeline integrity assessment.
Exploring Data Scaling Trends and Effects in Reinforcement Learning from Human Feedback
Mar 31, 2025Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning large language models with human preferences. While recent research has focused on algorithmic improvements, the importance of prompt-data construction has been overlooked. This paper addresses this gap by exploring data-driven bottlenecks in RLHF performance scaling, particularly reward hacking and decreasing response diversity. We introduce a hybrid reward system combining reasoning task verifiers (RTV) and a generative reward model (GenRM) to mitigate reward hacking. We also propose a novel prompt-selection method, Pre-PPO, to maintain response diversity and enhance learning effectiveness. Additionally, we find that prioritizing mathematical and coding tasks early in RLHF training significantly improves performance. Experiments across two model sizes validate our methods' effectiveness and scalability. Results show that RTV is most resistant to reward hacking, followed by GenRM with ground truth, and then GenRM with SFT Best-of-N responses. Our strategies enable rapid capture of subtle task-specific distinctions, leading to substantial improvements in overall RLHF performance. This work highlights the importance of careful data construction and provides practical methods to overcome performance barriers in RLHF.
Knowledge Distillation with Training Wheels
Feb 24, 2025Knowledge distillation is used, in generative language modeling, to train a smaller student model using the help of a larger teacher model, resulting in improved capabilities for the student model. In this paper, we formulate a more general framework for knowledge distillation where the student learns from the teacher during training, and also learns to ask for the teacher's help at test-time following rules specifying test-time restrictions. Towards this, we first formulate knowledge distillation as an entropy-regularized value optimization problem. Adopting Path Consistency Learning to solve this, leads to a new knowledge distillation algorithm using on-policy and off-policy demonstrations. We extend this using constrained reinforcement learning to a framework that incorporates the use of the teacher model as a test-time reference, within constraints. In this situation, akin to a human learner, the model needs to learn not only the learning material, but also the relative difficulty of different sections to prioritize for seeking teacher help. We examine the efficacy of our method through experiments in translation and summarization tasks, observing trends in accuracy and teacher use, noting that our approach unlocks operating points not available to the popular Speculative Decoding approach.
DNMDR: Dynamic Networks and Multi-view Drug Representations for Safe Medication Recommendation
Jan 15, 2025



Medication Recommendation (MR) is a promising research topic which booms diverse applications in the healthcare and clinical domains. However, existing methods mainly rely on sequential modeling and static graphs for representation learning, which ignore the dynamic correlations in diverse medical events of a patient's temporal visits, leading to insufficient global structural exploration on nodes. Additionally, mitigating drug-drug interactions (DDIs) is another issue determining the utility of the MR systems. To address the challenges mentioned above, this paper proposes a novel MR method with the integration of dynamic networks and multi-view drug representations (DNMDR). Specifically, weighted snapshot sequences for dynamic heterogeneous networks are constructed based on discrete visits in temporal EHRs, and all the dynamic networks are jointly trained to gain both structural correlations in diverse medical events and temporal dependency in historical health conditions, for achieving comprehensive patient representations with both semantic features and structural relationships. Moreover, combining the drug co-occurrences and adverse drug-drug interactions (DDIs) in internal view of drug molecule structure and interactive view of drug pairs, the safe drug representations are available to obtain high-quality medication combination recommendation. Finally, extensive experiments on real world datasets are conducted for performance evaluation, and the experimental results demonstrate that the proposed DNMDR method outperforms the state-of-the-art baseline models with a large margin on various metrics such as PRAUC, Jaccard, DDI rates and so on.
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024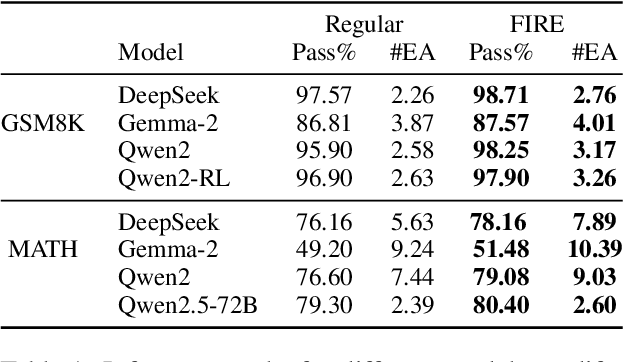


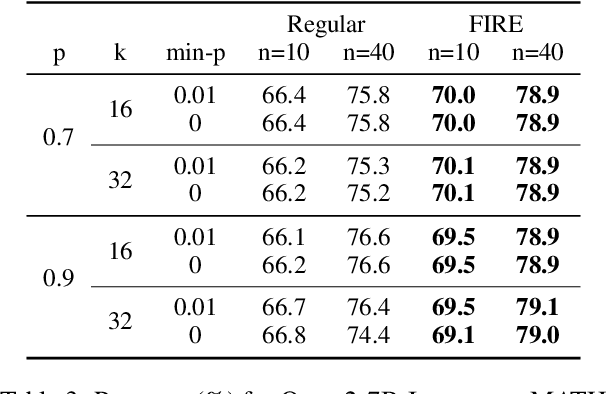
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024
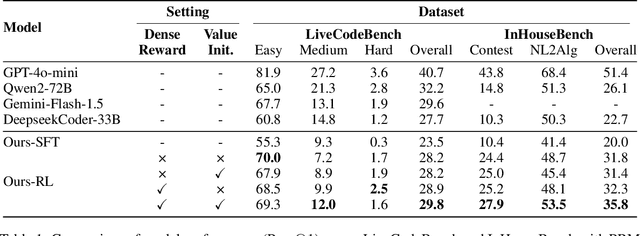

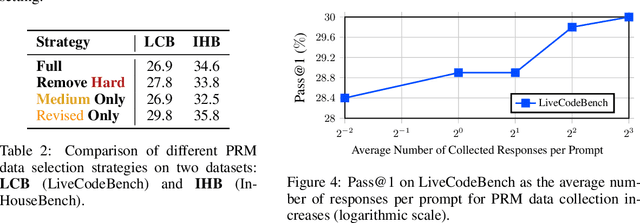
Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization
Oct 11, 2024



Reinforcement Learning (RL) plays a crucial role in aligning large language models (LLMs) with human preferences and improving their ability to perform complex tasks. However, current approaches either require significant computational resources due to the use of multiple models and extensive online sampling for training (e.g., PPO) or are framed as bandit problems (e.g., DPO, DRO), which often struggle with multi-step reasoning tasks, such as math problem-solving and complex reasoning that involve long chains of thought. To overcome these limitations, we introduce Direct Q-function Optimization (DQO), which formulates the response generation process as a Markov Decision Process (MDP) and utilizes the soft actor-critic (SAC) framework to optimize a Q-function directly parameterized by the language model. The MDP formulation of DQO offers structural advantages over bandit-based methods, enabling more effective process supervision. Experimental results on two math problem-solving datasets, GSM8K and MATH, demonstrate that DQO outperforms previous methods, establishing it as a promising offline reinforcement learning approach for aligning language models.
Optimal Cost Constrained Adversarial Attacks For Multiple Agent Systems
Nov 01, 2023


Finding optimal adversarial attack strategies is an important topic in reinforcement learning and the Markov decision process. Previous studies usually assume one all-knowing coordinator (attacker) for whom attacking different recipient (victim) agents incurs uniform costs. However, in reality, instead of using one limitless central attacker, the attacks often need to be performed by distributed attack agents. We formulate the problem of performing optimal adversarial agent-to-agent attacks using distributed attack agents, in which we impose distinct cost constraints on each different attacker-victim pair. We propose an optimal method integrating within-step static constrained attack-resource allocation optimization and between-step dynamic programming to achieve the optimal adversarial attack in a multi-agent system. Our numerical results show that the proposed attacks can significantly reduce the rewards received by the attacked agents.
Efficient Action Robust Reinforcement Learning with Probabilistic Policy Execution Uncertainty
Jul 20, 2023
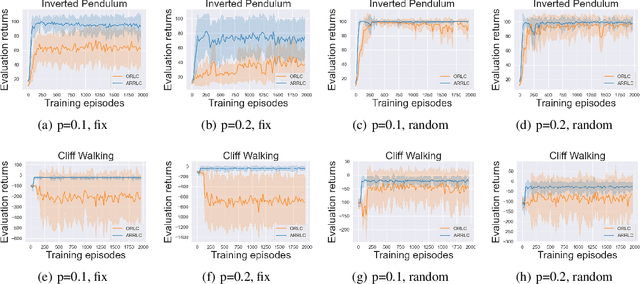
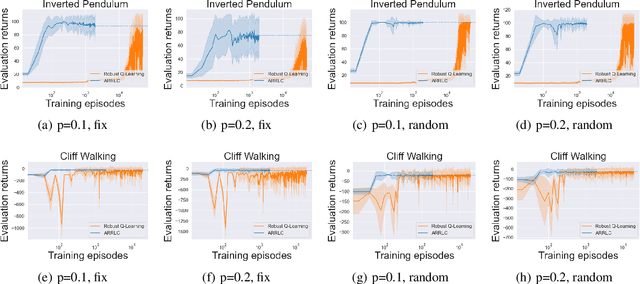
Robust reinforcement learning (RL) aims to find a policy that optimizes the worst-case performance in the face of uncertainties. In this paper, we focus on action robust RL with the probabilistic policy execution uncertainty, in which, instead of always carrying out the action specified by the policy, the agent will take the action specified by the policy with probability $1-\rho$ and an alternative adversarial action with probability $\rho$. We establish the existence of an optimal policy on the action robust MDPs with probabilistic policy execution uncertainty and provide the action robust Bellman optimality equation for its solution. Furthermore, we develop Action Robust Reinforcement Learning with Certificates (ARRLC) algorithm that achieves minimax optimal regret and sample complexity. Furthermore, we conduct numerical experiments to validate our approach's robustness, demonstrating that ARRLC outperforms non-robust RL algorithms and converges faster than the robust TD algorithm in the presence of action perturbations.
Efficient Adversarial Attacks on Online Multi-agent Reinforcement Learning
Jul 15, 2023



Due to the broad range of applications of multi-agent reinforcement learning (MARL), understanding the effects of adversarial attacks against MARL model is essential for the safe applications of this model. Motivated by this, we investigate the impact of adversarial attacks on MARL. In the considered setup, there is an exogenous attacker who is able to modify the rewards before the agents receive them or manipulate the actions before the environment receives them. The attacker aims to guide each agent into a target policy or maximize the cumulative rewards under some specific reward function chosen by the attacker, while minimizing the amount of manipulation on feedback and action. We first show the limitations of the action poisoning only attacks and the reward poisoning only attacks. We then introduce a mixed attack strategy with both the action poisoning and the reward poisoning. We show that the mixed attack strategy can efficiently attack MARL agents even if the attacker has no prior information about the underlying environment and the agents' algorithms.