 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Regret for KL-Regularized Multi-Armed Bandits
Mar 02, 2026Recent studies have shown that reinforcement learning with KL-regularized objectives can enjoy faster rates of convergence or logarithmic regret, in contrast to the classical $\sqrt{T}$-type regret in the unregularized setting. However, the statistical efficiency of online learning with respect to KL-regularized objectives remains far from completely characterized, even when specialized to multi-armed bandits (MABs). We address this problem for MABs via a sharp analysis of KL-UCB using a novel peeling argument, which yields a $\tilde{O}(ηK\log^2T)$ upper bound: the first high-probability regret bound with linear dependence on $K$. Here, $T$ is the time horizon, $K$ is the number of arms, $η^{-1}$ is the regularization intensity, and $\tilde{O}$ hides all logarithmic factors except those involving $\log T$. The near-tightness of our analysis is certified by the first non-constant lower bound $Ω(ηK \log T)$, which follows from subtle hard-instance constructions and a tailored decomposition of the Bayes prior. Moreover, in the low-regularization regime (i.e., large $η$), we show that the KL-regularized regret for MABs is $η$-independent and scales as $\tildeΘ(\sqrt{KT})$. Overall, our results provide a thorough understanding of KL-regularized MABs across all regimes of $η$ and yield nearly optimal bounds in terms of $K$, $η$, and $T$.
Nearly Optimal Sample Complexity of Offline KL-Regularized Contextual Bandits under Single-Policy Concentrability
Feb 09, 2025
KL-regularized policy optimization has become a workhorse in learning-based decision making, while its theoretical understanding is still very limited. Although recent progress has been made towards settling the sample complexity of KL-regularized contextual bandits, existing sample complexity bounds are either $\tilde{O}(\epsilon^{-2})$ under single-policy concentrability or $\tilde{O}(\epsilon^{-1})$ under all-policy concentrability. In this paper, we propose the \emph{first} algorithm with $\tilde{O}(\epsilon^{-1})$ sample complexity under single-policy concentrability for offline contextual bandits. Our algorithm is designed for general function approximation and based on the principle of \emph{pessimism in the face of uncertainty}. The core of our proof leverages the strong convexity of the KL regularization, and the conditional non-negativity of the gap between the true reward and its pessimistic estimator to refine a mean-value-type risk upper bound to its extreme. This in turn leads to a novel covariance-based analysis, effectively bypassing the need for uniform control over the discrepancy between any two functions in the function class. The near-optimality of our algorithm is demonstrated by an $\tilde{\Omega}(\epsilon^{-1})$ lower bound. Furthermore, we extend our algorithm to contextual dueling bandits and achieve a similar nearly optimal sample complexity.
Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization
Oct 11, 2024



Reinforcement Learning (RL) plays a crucial role in aligning large language models (LLMs) with human preferences and improving their ability to perform complex tasks. However, current approaches either require significant computational resources due to the use of multiple models and extensive online sampling for training (e.g., PPO) or are framed as bandit problems (e.g., DPO, DRO), which often struggle with multi-step reasoning tasks, such as math problem-solving and complex reasoning that involve long chains of thought. To overcome these limitations, we introduce Direct Q-function Optimization (DQO), which formulates the response generation process as a Markov Decision Process (MDP) and utilizes the soft actor-critic (SAC) framework to optimize a Q-function directly parameterized by the language model. The MDP formulation of DQO offers structural advantages over bandit-based methods, enabling more effective process supervision. Experimental results on two math problem-solving datasets, GSM8K and MATH, demonstrate that DQO outperforms previous methods, establishing it as a promising offline reinforcement learning approach for aligning language models.
Self-Play Preference Optimization for Language Model Alignment
May 01, 2024
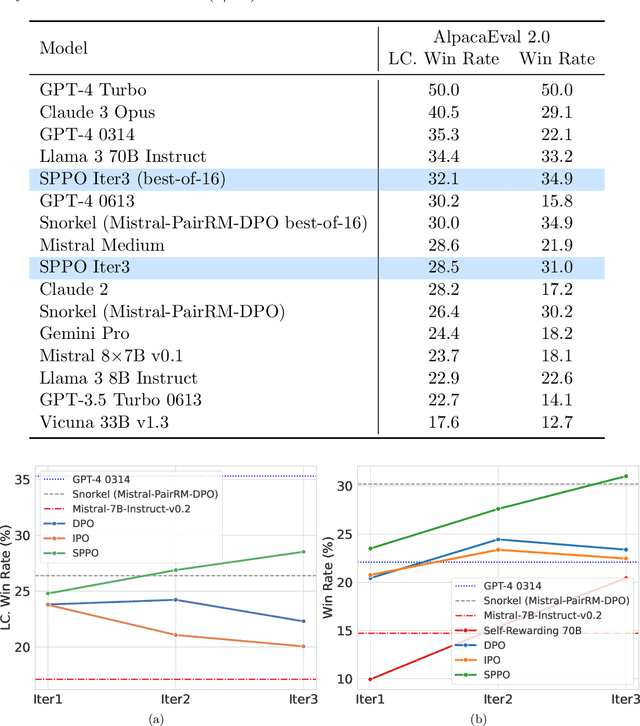


Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed \textit{Self-Play Preference Optimization} (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models.
Self-Play Fine-Tuning of Diffusion Models for Text-to-Image Generation
Feb 15, 2024


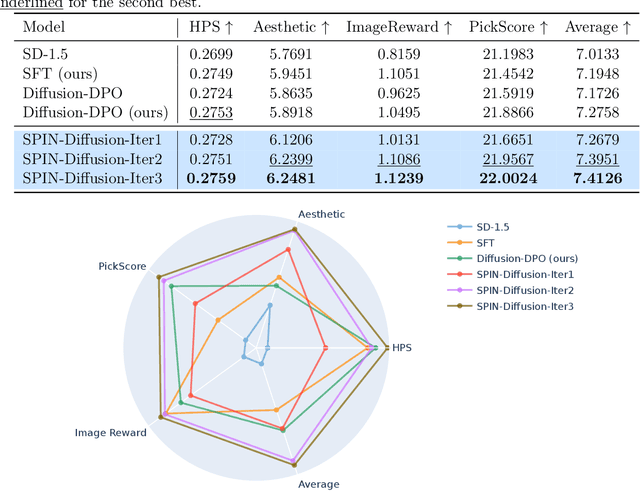
Fine-tuning Diffusion Models remains an underexplored frontier in generative artificial intelligence (GenAI), especially when compared with the remarkable progress made in fine-tuning Large Language Models (LLMs). While cutting-edge diffusion models such as Stable Diffusion (SD) and SDXL rely on supervised fine-tuning, their performance inevitably plateaus after seeing a certain volume of data. Recently, reinforcement learning (RL) has been employed to fine-tune diffusion models with human preference data, but it requires at least two images ("winner" and "loser" images) for each text prompt. In this paper, we introduce an innovative technique called self-play fine-tuning for diffusion models (SPIN-Diffusion), where the diffusion model engages in competition with its earlier versions, facilitating an iterative self-improvement process. Our approach offers an alternative to conventional supervised fine-tuning and RL strategies, significantly improving both model performance and alignment. Our experiments on the Pick-a-Pic dataset reveal that SPIN-Diffusion outperforms the existing supervised fine-tuning method in aspects of human preference alignment and visual appeal right from its first iteration. By the second iteration, it exceeds the performance of RLHF-based methods across all metrics, achieving these results with less data.
Reinforcement Learning from Human Feedback with Active Queries
Feb 14, 2024

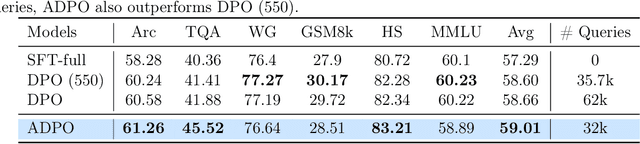

Aligning large language models (LLM) with human preference plays a key role in building modern generative models and can be achieved by reinforcement learning from human feedback (RLHF). Despite their superior performance, current RLHF approaches often require a large amount of human-labelled preference data, which is expensive to collect. In this paper, inspired by the success of active learning, we address this problem by proposing query-efficient RLHF methods. We first formalize the alignment problem as a contextual dueling bandit problem and design an active-query-based proximal policy optimization (APPO) algorithm with an $\tilde{O}(d^2/\Delta)$ regret bound and an $\tilde{O}(d^2/\Delta^2)$ query complexity, where $d$ is the dimension of feature space and $\Delta$ is the sub-optimality gap over all the contexts. We then propose ADPO, a practical version of our algorithm based on direct preference optimization (DPO) and apply it to fine-tuning LLMs. Our experiments show that ADPO, while only making about half of queries for human preference, matches the performance of the state-of-the-art DPO method.
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Jan 02, 2024



Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong LLM out of a weak one without the need for acquiring additional human-annotated data. We propose a new fine-tuning method called Self-Play fIne-tuNing (SPIN), which starts from a supervised fine-tuned model. At the heart of SPIN lies a self-play mechanism, where the LLM refines its capability by playing against instances of itself. More specifically, the LLM generates its own training data from its previous iterations, refining its policy by discerning these self-generated responses from those obtained from human-annotated data. Our method progressively elevates the LLM from a nascent model to a formidable one, unlocking the full potential of human-annotated demonstration data for SFT. Theoretically, we prove that the global optimum to the training objective function of our method is achieved only when the LLM policy aligns with the target data distribution. Empirically, we evaluate our method on several benchmark datasets including the HuggingFace Open LLM Leaderboard, MT-Bench, and datasets from Big-Bench. Our results show that SPIN can significantly improve the LLM's performance across a variety of benchmarks and even outperform models trained through direct preference optimization (DPO) supplemented with extra GPT-4 preference data. This sheds light on the promise of self-play, enabling the achievement of human-level performance in LLMs without the need for expert opponents.
Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment
Oct 16, 2023



Open Information Extraction (OIE) aims to extract objective structured knowledge from natural texts, which has attracted growing attention to build dedicated models with human experience. As the large language models (LLMs) have exhibited remarkable in-context learning capabilities, a question arises as to whether the task of OIE can be effectively tackled with this paradigm? In this paper, we explore solving the OIE problem by constructing an appropriate reasoning environment for LLMs. Specifically, we first propose a method to effectively estimate the discrepancy of syntactic distribution between a LLM and test samples, which can serve as correlation evidence for preparing positive demonstrations. Upon the evidence, we introduce a simple yet effective mechanism to establish the reasoning environment for LLMs on specific tasks. Without bells and whistles, experimental results on the standard CaRB benchmark demonstrate that our $6$-shot approach outperforms state-of-the-art supervised method, achieving an $55.3$ $F_1$ score. Further experiments on TACRED and ACE05 show that our method can naturally generalize to other information extraction tasks, resulting in improvements of $5.7$ and $6.8$ $F_1$ scores, respectively.
BiLL-VTG: Bridging Large Language Models and Lightweight Visual Tools for Video-based Texts Generation
Oct 16, 2023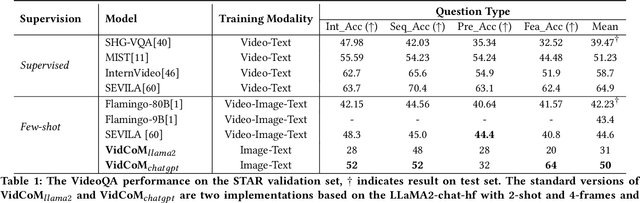
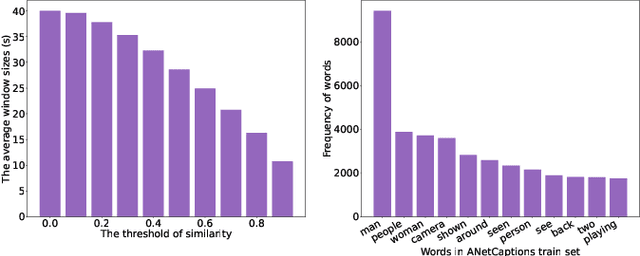
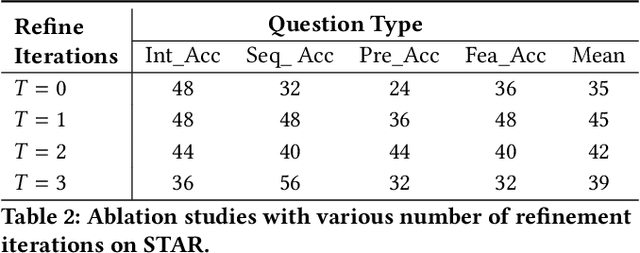

Building models that generate textual responses to user instructions for videos is a practical and challenging topic, as it requires both vision understanding and knowledge reasoning. Compared to language and image modalities, training efficiency remains a serious problem as existing studies train models on massive sparse videos aligned with brief descriptions. In this paper, we introduce BiLL-VTG, a fast adaptive framework that leverages large language models (LLMs) to reasoning on videos based on essential lightweight visual tools. Specifically, we reveal the key to response specific instructions is the concentration on relevant video events, and utilize two visual tools of structured scene graph generation and descriptive image caption generation to gather and represent the events information. Thus, a LLM equipped with world knowledge is adopted as the reasoning agent to achieve the response by performing multiple reasoning steps on specified video events.To address the difficulty of specifying events from agent, we further propose an Instruction-oriented Video Events Recognition (InsOVER) algorithm based on the efficient Hungarian matching to localize corresponding video events using linguistic instructions, enabling LLMs to interact with long videos. Extensive experiments on two typical video-based texts generations tasks show that our tuning-free framework outperforms the pre-trained models including Flamingo-80B, to achieve the state-of-the-art performance.
Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs
May 15, 2023Recent studies have shown that episodic reinforcement learning (RL) is no harder than bandits when the total reward is bounded by $1$, and proved regret bounds that have a polylogarithmic dependence on the planning horizon $H$. However, it remains an open question that if such results can be carried over to adversarial RL, where the reward is adversarially chosen at each episode. In this paper, we answer this question affirmatively by proposing the first horizon-free policy search algorithm. To tackle the challenges caused by exploration and adversarially chosen reward, our algorithm employs (1) a variance-uncertainty-aware weighted least square estimator for the transition kernel; and (2) an occupancy measure-based technique for the online search of a \emph{stochastic} policy. We show that our algorithm achieves an $\tilde{O}\big((d+\log (|\mathcal{S}|^2 |\mathcal{A}|))\sqrt{K}\big)$ regret with full-information feedback, where $d$ is the dimension of a known feature mapping linearly parametrizing the unknown transition kernel of the MDP, $K$ is the number of episodes, $|\mathcal{S}|$ and $|\mathcal{A}|$ are the cardinalities of the state and action spaces. We also provide hardness results and regret lower bounds to justify the near optimality of our algorithm and the unavoidability of $\log|\mathcal{S}|$ and $\log|\mathcal{A}|$ in the regret bound.