 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Convergence and Rich Feature Learning in $L$-Layer Infinite-Width Neural Networks under $μ$P Parametrization
Mar 12, 2025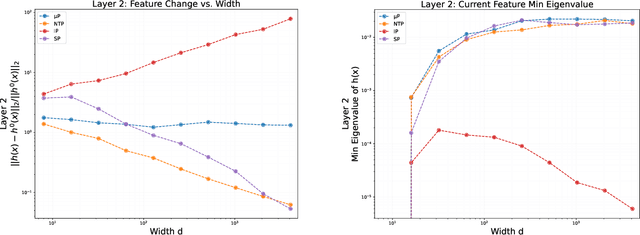


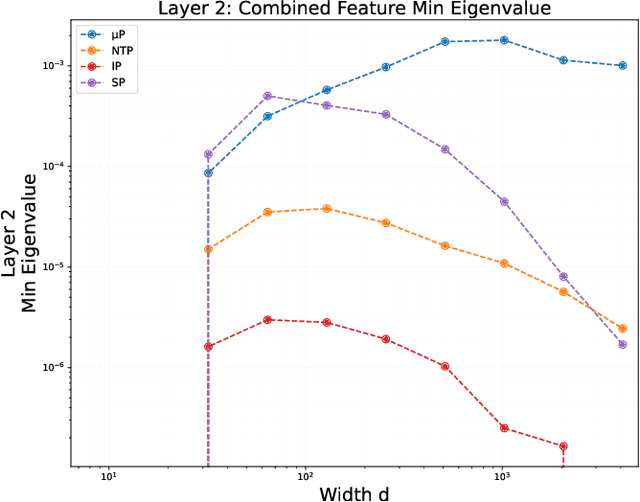
Despite deep neural networks' powerful representation learning capabilities, theoretical understanding of how networks can simultaneously achieve meaningful feature learning and global convergence remains elusive. Existing approaches like the neural tangent kernel (NTK) are limited because features stay close to their initialization in this parametrization, leaving open questions about feature properties during substantial evolution. In this paper, we investigate the training dynamics of infinitely wide, $L$-layer neural networks using the tensor program (TP) framework. Specifically, we show that, when trained with stochastic gradient descent (SGD) under the Maximal Update parametrization ($\mu$P) and mild conditions on the activation function, SGD enables these networks to learn linearly independent features that substantially deviate from their initial values. This rich feature space captures relevant data information and ensures that any convergent point of the training process is a global minimum. Our analysis leverages both the interactions among features across layers and the properties of Gaussian random variables, providing new insights into deep representation learning. We further validate our theoretical findings through experiments on real-world datasets.
Nearly Optimal Sample Complexity of Offline KL-Regularized Contextual Bandits under Single-Policy Concentrability
Feb 09, 2025
KL-regularized policy optimization has become a workhorse in learning-based decision making, while its theoretical understanding is still very limited. Although recent progress has been made towards settling the sample complexity of KL-regularized contextual bandits, existing sample complexity bounds are either $\tilde{O}(\epsilon^{-2})$ under single-policy concentrability or $\tilde{O}(\epsilon^{-1})$ under all-policy concentrability. In this paper, we propose the \emph{first} algorithm with $\tilde{O}(\epsilon^{-1})$ sample complexity under single-policy concentrability for offline contextual bandits. Our algorithm is designed for general function approximation and based on the principle of \emph{pessimism in the face of uncertainty}. The core of our proof leverages the strong convexity of the KL regularization, and the conditional non-negativity of the gap between the true reward and its pessimistic estimator to refine a mean-value-type risk upper bound to its extreme. This in turn leads to a novel covariance-based analysis, effectively bypassing the need for uniform control over the discrepancy between any two functions in the function class. The near-optimality of our algorithm is demonstrated by an $\tilde{\Omega}(\epsilon^{-1})$ lower bound. Furthermore, we extend our algorithm to contextual dueling bandits and achieve a similar nearly optimal sample complexity.
Towards the Fundamental Limits of Knowledge Transfer over Finite Domains
Oct 17, 2023


We characterize the statistical efficiency of knowledge transfer through $n$ samples from a teacher to a probabilistic student classifier with input space $\mathcal S$ over labels $\mathcal A$. We show that privileged information at three progressive levels accelerates the transfer. At the first level, only samples with hard labels are known, via which the maximum likelihood estimator attains the minimax rate $\sqrt{{|{\mathcal S}||{\mathcal A}|}/{n}}$. The second level has the teacher probabilities of sampled labels available in addition, which turns out to boost the convergence rate lower bound to ${{|{\mathcal S}||{\mathcal A}|}/{n}}$. However, under this second data acquisition protocol, minimizing a naive adaptation of the cross-entropy loss results in an asymptotically biased student. We overcome this limitation and achieve the fundamental limit by using a novel empirical variant of the squared error logit loss. The third level further equips the student with the soft labels (complete logits) on ${\mathcal A}$ given every sampled input, thereby provably enables the student to enjoy a rate ${|{\mathcal S}|}/{n}$ free of $|{\mathcal A}|$. We find any Kullback-Leibler divergence minimizer to be optimal in the last case. Numerical simulations distinguish the four learners and corroborate our theory.
Horizon-free Reinforcement Learning in Adversarial Linear Mixture MDPs
May 15, 2023Recent studies have shown that episodic reinforcement learning (RL) is no harder than bandits when the total reward is bounded by $1$, and proved regret bounds that have a polylogarithmic dependence on the planning horizon $H$. However, it remains an open question that if such results can be carried over to adversarial RL, where the reward is adversarially chosen at each episode. In this paper, we answer this question affirmatively by proposing the first horizon-free policy search algorithm. To tackle the challenges caused by exploration and adversarially chosen reward, our algorithm employs (1) a variance-uncertainty-aware weighted least square estimator for the transition kernel; and (2) an occupancy measure-based technique for the online search of a \emph{stochastic} policy. We show that our algorithm achieves an $\tilde{O}\big((d+\log (|\mathcal{S}|^2 |\mathcal{A}|))\sqrt{K}\big)$ regret with full-information feedback, where $d$ is the dimension of a known feature mapping linearly parametrizing the unknown transition kernel of the MDP, $K$ is the number of episodes, $|\mathcal{S}|$ and $|\mathcal{A}|$ are the cardinalities of the state and action spaces. We also provide hardness results and regret lower bounds to justify the near optimality of our algorithm and the unavoidability of $\log|\mathcal{S}|$ and $\log|\mathcal{A}|$ in the regret bound.