 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Rates for Offline Contextual Bandits with Forward-KL Regularization under Single-Policy Concentrability
May 09, 2026\emph{Kullback-Leibler} (KL) regularization is ubiquitous in reinforcement learning algorithms in the form of \emph{reverse} or \emph{forward} KL. Recent studies have demonstrated $ε^{-1}$-type fast rates for decision making under reverse KL regularization, in contrast to the standard $ε^{-2}$-type sample complexity. However, for forward-KL-regularized objectives, existing statistical analyses are either not applicable or result in $\tilde{O}(ε^{-2})$ slow rates. We take the first step towards addressing this problem via a streamlined analysis of forward-KL-regularized offline CBs. We give the first $\tilde{O}(ε^{-1})$ upper bounds in tabular and general function approximation settings, both under notions of \emph{single-policy concentrability}. In particular, our convex-analytical pipeline unifies these settings by exploiting the pessimism principle in a novel way and completely bypasses the proof routines in previous works based on the mean value theorem, which might be of independent interest. Moreover, we provide rate-optimal lower bounds, manifesting the tightness of our upper bounds in terms of statistical rates. Our lower bounds also demonstrate that the forward-KL-regularized sample complexity recovers the unregularized slow rate in the low-regularization regime, similarly to the reverse-KL regularization.
On the Optimal Sample Complexity of Offline Multi-Armed Bandits with KL Regularization
May 04, 2026Kullback-Leibler (KL) regularization is widely used in offline decision-making and offers several benefits, motivating recent work on the sample complexity of offline learning with respect to KL-regularized performance metrics. Nevertheless, the exact sample complexity of KL-regularized offline learning remains largely from fully characterized. In this paper, we study this question in the setting of multi-armed bandits (MABs). We provide a sharp analysis of KL-PCB (Zhao et al., 2026), showing that it achieves a sample complexity of $\tilde{O}(ηSAC^{π^*}/ε)$ under large regularization $η= \tilde{O}(ε^{-1})$, and a sample complexity of $\tildeΩ(SAC^{π^*}/ε^2)$ under small regularization $η= \tildeΩ(ε^{-1})$, where $η$ is the regularization parameter, $S$ is the number of contexts, $A$ is the number of arms, $C^{π^*}$ policy coverage coefficient at the optimal policy $π^*$, $ε$ is the desired sub-optimality, and $\tilde{O}$ and $\tildeΩ$ hide all poly-logarithmic factors. We further provide a pair of sharper sample complexity lower bounds, which matches the upper bounds over the entire range of regularization strengths. Overall, our results provide a nearly complete characterization of offline multi-armed bandits with KL regularization.
Near-Optimal Regret for KL-Regularized Multi-Armed Bandits
Mar 02, 2026Recent studies have shown that reinforcement learning with KL-regularized objectives can enjoy faster rates of convergence or logarithmic regret, in contrast to the classical $\sqrt{T}$-type regret in the unregularized setting. However, the statistical efficiency of online learning with respect to KL-regularized objectives remains far from completely characterized, even when specialized to multi-armed bandits (MABs). We address this problem for MABs via a sharp analysis of KL-UCB using a novel peeling argument, which yields a $\tilde{O}(ηK\log^2T)$ upper bound: the first high-probability regret bound with linear dependence on $K$. Here, $T$ is the time horizon, $K$ is the number of arms, $η^{-1}$ is the regularization intensity, and $\tilde{O}$ hides all logarithmic factors except those involving $\log T$. The near-tightness of our analysis is certified by the first non-constant lower bound $Ω(ηK \log T)$, which follows from subtle hard-instance constructions and a tailored decomposition of the Bayes prior. Moreover, in the low-regularization regime (i.e., large $η$), we show that the KL-regularized regret for MABs is $η$-independent and scales as $\tildeΘ(\sqrt{KT})$. Overall, our results provide a thorough understanding of KL-regularized MABs across all regimes of $η$ and yield nearly optimal bounds in terms of $K$, $η$, and $T$.
Logarithmic Regret for Online KL-Regularized Reinforcement Learning
Feb 11, 2025
Recent advances in Reinforcement Learning from Human Feedback (RLHF) have shown that KL-regularization plays a pivotal role in improving the efficiency of RL fine-tuning for large language models (LLMs). Despite its empirical advantage, the theoretical difference between KL-regularized RL and standard RL remains largely under-explored. While there is a recent line of work on the theoretical analysis of KL-regularized objective in decision making \citep{xiong2024iterative, xie2024exploratory,zhao2024sharp}, these analyses either reduce to the traditional RL setting or rely on strong coverage assumptions. In this paper, we propose an optimism-based KL-regularized online contextual bandit algorithm, and provide a novel analysis of its regret. By carefully leveraging the benign optimization landscape induced by the KL-regularization and the optimistic reward estimation, our algorithm achieves an $\mathcal{O}\big(\eta\log (N_{\mathcal R} T)\cdot d_{\mathcal R}\big)$ logarithmic regret bound, where $\eta, N_{\mathcal R},T,d_{\mathcal R}$ denote the KL-regularization parameter, the cardinality of the reward function class, number of rounds, and the complexity of the reward function class. Furthermore, we extend our algorithm and analysis to reinforcement learning by developing a novel decomposition over transition steps and also obtain a similar logarithmic regret bound.
Nearly Optimal Sample Complexity of Offline KL-Regularized Contextual Bandits under Single-Policy Concentrability
Feb 09, 2025
KL-regularized policy optimization has become a workhorse in learning-based decision making, while its theoretical understanding is still very limited. Although recent progress has been made towards settling the sample complexity of KL-regularized contextual bandits, existing sample complexity bounds are either $\tilde{O}(\epsilon^{-2})$ under single-policy concentrability or $\tilde{O}(\epsilon^{-1})$ under all-policy concentrability. In this paper, we propose the \emph{first} algorithm with $\tilde{O}(\epsilon^{-1})$ sample complexity under single-policy concentrability for offline contextual bandits. Our algorithm is designed for general function approximation and based on the principle of \emph{pessimism in the face of uncertainty}. The core of our proof leverages the strong convexity of the KL regularization, and the conditional non-negativity of the gap between the true reward and its pessimistic estimator to refine a mean-value-type risk upper bound to its extreme. This in turn leads to a novel covariance-based analysis, effectively bypassing the need for uniform control over the discrepancy between any two functions in the function class. The near-optimality of our algorithm is demonstrated by an $\tilde{\Omega}(\epsilon^{-1})$ lower bound. Furthermore, we extend our algorithm to contextual dueling bandits and achieve a similar nearly optimal sample complexity.
Sharp Analysis for KL-Regularized Contextual Bandits and RLHF
Nov 07, 2024

Reverse-Kullback-Leibler (KL) regularization has emerged to be a predominant technique used to enhance policy optimization in reinforcement learning (RL) and reinforcement learning from human feedback (RLHF), which forces the learned policy to stay close to a reference policy. While the effectiveness and necessity of KL-regularization have been empirically demonstrated in various practical scenarios, current theoretical analysis of KL-regularized RLHF still obtains the same $\mathcal{O}(1 / \epsilon^2)$ sample complexity as problems without KL-regularization. To understand the fundamental distinction between policy learning objectives with KL-regularization and ones without KL-regularization, we are the first to theoretically demonstrate the power of KL-regularization by providing a sharp analysis for KL-regularized contextual bandits and RLHF, revealing an $\mathcal{O}(1 / \epsilon)$ sample complexity when $\epsilon$ is sufficiently small. We further explore the role of data coverage in contextual bandits and RLHF. While the coverage assumption is commonly employed in offline RLHF to link the samples from the reference policy to the optimal policy, often at the cost of a multiplicative dependence on the coverage coefficient, its impact on the sample complexity of online RLHF remains unclear. Previous theoretical analyses of online RLHF typically require explicit exploration and additional structural assumptions on the reward function class. In contrast, we show that with sufficient coverage from the reference policy, a simple two-stage mixed sampling strategy can achieve a sample complexity with only an additive dependence on the coverage coefficient. Our results provide a comprehensive understanding of the roles of KL-regularization and data coverage in RLHF, shedding light on the design of more efficient RLHF algorithms.
Feel-Good Thompson Sampling for Contextual Dueling Bandits
Apr 09, 2024

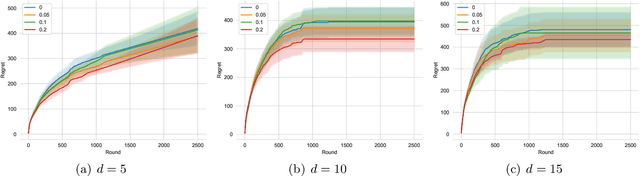
Contextual dueling bandits, where a learner compares two options based on context and receives feedback indicating which was preferred, extends classic dueling bandits by incorporating contextual information for decision-making and preference learning. Several algorithms based on the upper confidence bound (UCB) have been proposed for linear contextual dueling bandits. However, no algorithm based on posterior sampling has been developed in this setting, despite the empirical success observed in traditional contextual bandits. In this paper, we propose a Thompson sampling algorithm, named FGTS.CDB, for linear contextual dueling bandits. At the core of our algorithm is a new Feel-Good exploration term specifically tailored for dueling bandits. This term leverages the independence of the two selected arms, thereby avoiding a cross term in the analysis. We show that our algorithm achieves nearly minimax-optimal regret, i.e., $\tilde{\mathcal{O}}(d\sqrt T)$, where $d$ is the model dimension and $T$ is the time horizon. Finally, we evaluate our algorithm on synthetic data and observe that FGTS.CDB outperforms existing algorithms by a large margin.
A Nearly Optimal and Low-Switching Algorithm for Reinforcement Learning with General Function Approximation
Nov 26, 2023
The exploration-exploitation dilemma has been a central challenge in reinforcement learning (RL) with complex model classes. In this paper, we propose a new algorithm, Monotonic Q-Learning with Upper Confidence Bound (MQL-UCB) for RL with general function approximation. Our key algorithmic design includes (1) a general deterministic policy-switching strategy that achieves low switching cost, (2) a monotonic value function structure with carefully controlled function class complexity, and (3) a variance-weighted regression scheme that exploits historical trajectories with high data efficiency. MQL-UCB achieves minimax optimal regret of $\tilde{O}(d\sqrt{HK})$ when $K$ is sufficiently large and near-optimal policy switching cost of $\tilde{O}(dH)$, with $d$ being the eluder dimension of the function class, $H$ being the planning horizon, and $K$ being the number of episodes. Our work sheds light on designing provably sample-efficient and deployment-efficient Q-learning with nonlinear function approximation.
Pessimistic Nonlinear Least-Squares Value Iteration for Offline Reinforcement Learning
Oct 02, 2023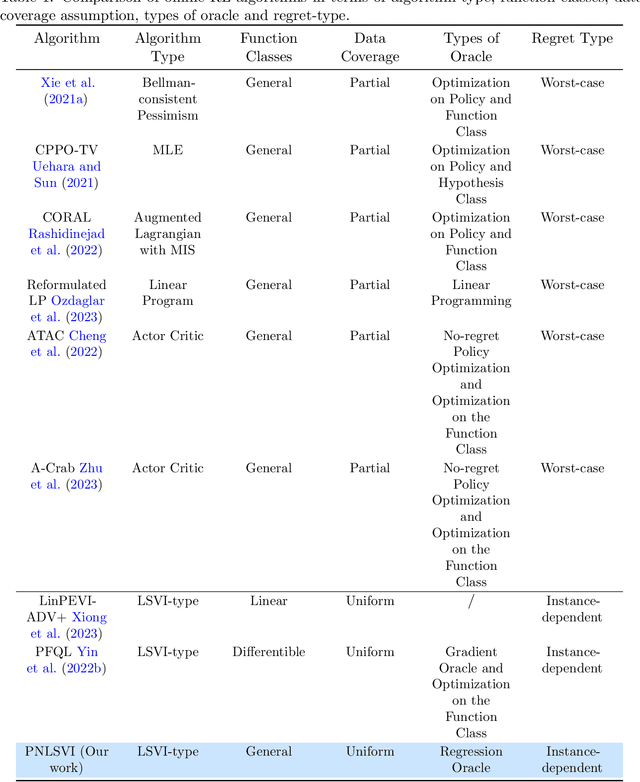
Offline reinforcement learning (RL), where the agent aims to learn the optimal policy based on the data collected by a behavior policy, has attracted increasing attention in recent years. While offline RL with linear function approximation has been extensively studied with optimal results achieved under certain assumptions, many works shift their interest to offline RL with non-linear function approximation. However, limited works on offline RL with non-linear function approximation have instance-dependent regret guarantees. In this paper, we propose an oracle-efficient algorithm, dubbed Pessimistic Nonlinear Least-Square Value Iteration (PNLSVI), for offline RL with non-linear function approximation. Our algorithmic design comprises three innovative components: (1) a variance-based weighted regression scheme that can be applied to a wide range of function classes, (2) a subroutine for variance estimation, and (3) a planning phase that utilizes a pessimistic value iteration approach. Our algorithm enjoys a regret bound that has a tight dependency on the function class complexity and achieves minimax optimal instance-dependent regret when specialized to linear function approximation. Our work extends the previous instance-dependent results within simpler function classes, such as linear and differentiable function to a more general framework.
Variance-Aware Regret Bounds for Stochastic Contextual Dueling Bandits
Oct 02, 2023
Dueling bandits is a prominent framework for decision-making involving preferential feedback, a valuable feature that fits various applications involving human interaction, such as ranking, information retrieval, and recommendation systems. While substantial efforts have been made to minimize the cumulative regret in dueling bandits, a notable gap in the current research is the absence of regret bounds that account for the inherent uncertainty in pairwise comparisons between the dueling arms. Intuitively, greater uncertainty suggests a higher level of difficulty in the problem. To bridge this gap, this paper studies the problem of contextual dueling bandits, where the binary comparison of dueling arms is generated from a generalized linear model (GLM). We propose a new SupLinUCB-type algorithm that enjoys computational efficiency and a variance-aware regret bound $\tilde O\big(d\sqrt{\sum_{t=1}^T\sigma_t^2} + d\big)$, where $\sigma_t$ is the variance of the pairwise comparison in round $t$, $d$ is the dimension of the context vectors, and $T$ is the time horizon. Our regret bound naturally aligns with the intuitive expectation in scenarios where the comparison is deterministic, the algorithm only suffers from an $\tilde O(d)$ regret. We perform empirical experiments on synthetic data to confirm the advantage of our method over previous variance-agnostic algorithms.