 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Dependent Regret Lower Bounds for Contextual Bandits
Mar 15, 2025Variance-dependent regret bounds for linear contextual bandits, which improve upon the classical $\tilde{O}(d\sqrt{K})$ regret bound to $\tilde{O}(d\sqrt{\sum_{k=1}^K\sigma_k^2})$, where $d$ is the context dimension, $K$ is the number of rounds, and $\sigma^2_k$ is the noise variance in round $k$, has been widely studied in recent years. However, most existing works focus on the regret upper bounds instead of lower bounds. To our knowledge, the only lower bound is from Jia et al. (2024), which proved that for any eluder dimension $d_{\textbf{elu}}$ and total variance budget $\Lambda$, there exists an instance with $\sum_{k=1}^K\sigma_k^2\leq \Lambda$ for which any algorithm incurs a variance-dependent lower bound of $\Omega(\sqrt{d_{\textbf{elu}}\Lambda})$. However, this lower bound has a $\sqrt{d}$ gap with existing upper bounds. Moreover, it only considers a fixed total variance budget $\Lambda$ and does not apply to a general variance sequence $\{\sigma_1^2,\ldots,\sigma_K^2\}$. In this paper, to overcome the limitations of Jia et al. (2024), we consider the general variance sequence under two settings. For a prefixed sequence, where the entire variance sequence is revealed to the learner at the beginning of the learning process, we establish a variance-dependent lower bound of $\Omega(d \sqrt{\sum_{k=1}^K\sigma_k^2 }/\log K)$ for linear contextual bandits. For an adaptive sequence, where an adversary can generate the variance $\sigma_k^2$ in each round $k$ based on historical observations, we show that when the adversary must generate $\sigma_k^2$ before observing the decision set $\mathcal{D}_k$, a similar lower bound of $\Omega(d\sqrt{ \sum_{k=1}^K\sigma_k^2} /\log^6(dK))$ holds. In both settings, our results match the upper bounds of the SAVE algorithm (Zhao et al., 2023) up to logarithmic factors.
Accelerated Preference Optimization for Large Language Model Alignment
Oct 08, 2024Reinforcement Learning from Human Feedback (RLHF) has emerged as a pivotal tool for aligning large language models (LLMs) with human preferences. Direct Preference Optimization (DPO), one of the most popular approaches, formulates RLHF as a policy optimization problem without explicitly estimating the reward function. It overcomes the stability and efficiency issues of two-step approaches, which typically involve first estimating the reward function and then optimizing the policy via proximal policy optimization (PPO). Since RLHF is essentially an optimization problem, and it is well-known that momentum techniques can accelerate optimization both theoretically and empirically, a natural question arises: Can RLHF be accelerated by momentum? This paper answers this question in the affirmative. In detail, we first show that the iterative preference optimization method can be viewed as a proximal point method. Based on this observation, we propose a general Accelerated Preference Optimization (APO) framework, which unifies many existing preference optimization algorithms and employs Nesterov's momentum technique to speed up the alignment of LLMs. Theoretically, we demonstrate that APO can achieve a faster convergence rate than the standard iterative preference optimization methods, including DPO and Self-Play Preference Optimization (SPPO). Empirically, we show the superiority of APO over DPO, iterative DPO, and other strong baselines for RLHF on the AlpacaEval 2.0 benchmark.
Nearly Optimal Algorithms for Contextual Dueling Bandits from Adversarial Feedback
Apr 16, 2024Learning from human feedback plays an important role in aligning generative models, such as large language models (LLM). However, the effectiveness of this approach can be influenced by adversaries, who may intentionally provide misleading preferences to manipulate the output in an undesirable or harmful direction. To tackle this challenge, we study a specific model within this problem domain--contextual dueling bandits with adversarial feedback, where the true preference label can be flipped by an adversary. We propose an algorithm namely robust contextual dueling bandit (\algo), which is based on uncertainty-weighted maximum likelihood estimation. Our algorithm achieves an $\tilde O(d\sqrt{T}+dC)$ regret bound, where $T$ is the number of rounds, $d$ is the dimension of the context, and $ 0 \le C \le T$ is the total number of adversarial feedback. We also prove a lower bound to show that our regret bound is nearly optimal, both in scenarios with and without ($C=0$) adversarial feedback. Additionally, we conduct experiments to evaluate our proposed algorithm against various types of adversarial feedback. Experimental results demonstrate its superiority over the state-of-the-art dueling bandit algorithms in the presence of adversarial feedback.
Settling Constant Regrets in Linear Markov Decision Processes
Apr 16, 2024We study the constant regret guarantees in reinforcement learning (RL). Our objective is to design an algorithm that incurs only finite regret over infinite episodes with high probability. We introduce an algorithm, Cert-LSVI-UCB, for misspecified linear Markov decision processes (MDPs) where both the transition kernel and the reward function can be approximated by some linear function up to misspecification level $\zeta$. At the core of Cert-LSVI-UCB is an innovative certified estimator, which facilitates a fine-grained concentration analysis for multi-phase value-targeted regression, enabling us to establish an instance-dependent regret bound that is constant w.r.t. the number of episodes. Specifically, we demonstrate that for an MDP characterized by a minimal suboptimality gap $\Delta$, Cert-LSVI-UCB has a cumulative regret of $\tilde{\mathcal{O}}(d^3H^5/\Delta)$ with high probability, provided that the misspecification level $\zeta$ is below $\tilde{\mathcal{O}}(\Delta / (\sqrt{d}H^2))$. Remarkably, this regret bound remains constant relative to the number of episodes $K$. To the best of our knowledge, Cert-LSVI-UCB is the first algorithm to achieve a constant, instance-dependent, high-probability regret bound in RL with linear function approximation for infinite runs without relying on prior distribution assumptions. This not only highlights the robustness of Cert-LSVI-UCB to model misspecification but also introduces novel algorithmic designs and analytical techniques of independent interest.
Towards Robust Model-Based Reinforcement Learning Against Adversarial Corruption
Feb 15, 2024This study tackles the challenges of adversarial corruption in model-based reinforcement learning (RL), where the transition dynamics can be corrupted by an adversary. Existing studies on corruption-robust RL mostly focus on the setting of model-free RL, where robust least-square regression is often employed for value function estimation. However, these techniques cannot be directly applied to model-based RL. In this paper, we focus on model-based RL and take the maximum likelihood estimation (MLE) approach to learn transition model. Our work encompasses both online and offline settings. In the online setting, we introduce an algorithm called corruption-robust optimistic MLE (CR-OMLE), which leverages total-variation (TV)-based information ratios as uncertainty weights for MLE. We prove that CR-OMLE achieves a regret of $\tilde{\mathcal{O}}(\sqrt{T} + C)$, where $C$ denotes the cumulative corruption level after $T$ episodes. We also prove a lower bound to show that the additive dependence on $C$ is optimal. We extend our weighting technique to the offline setting, and propose an algorithm named corruption-robust pessimistic MLE (CR-PMLE). Under a uniform coverage condition, CR-PMLE exhibits suboptimality worsened by $\mathcal{O}(C/n)$, nearly matching the lower bound. To the best of our knowledge, this is the first work on corruption-robust model-based RL algorithms with provable guarantees.
Nearly Minimax Optimal Regret for Learning Linear Mixture Stochastic Shortest Path
Feb 14, 2024

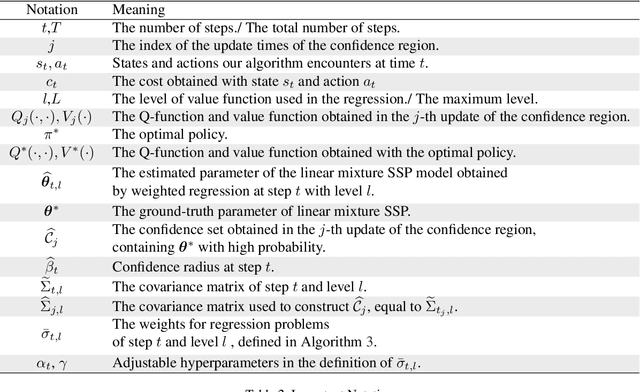
We study the Stochastic Shortest Path (SSP) problem with a linear mixture transition kernel, where an agent repeatedly interacts with a stochastic environment and seeks to reach certain goal state while minimizing the cumulative cost. Existing works often assume a strictly positive lower bound of the cost function or an upper bound of the expected length for the optimal policy. In this paper, we propose a new algorithm to eliminate these restrictive assumptions. Our algorithm is based on extended value iteration with a fine-grained variance-aware confidence set, where the variance is estimated recursively from high-order moments. Our algorithm achieves an $\tilde{\mathcal O}(dB_*\sqrt{K})$ regret bound, where $d$ is the dimension of the feature mapping in the linear transition kernel, $B_*$ is the upper bound of the total cumulative cost for the optimal policy, and $K$ is the number of episodes. Our regret upper bound matches the $\Omega(dB_*\sqrt{K})$ lower bound of linear mixture SSPs in Min et al. (2022), which suggests that our algorithm is nearly minimax optimal.
Reinforcement Learning from Human Feedback with Active Queries
Feb 14, 2024

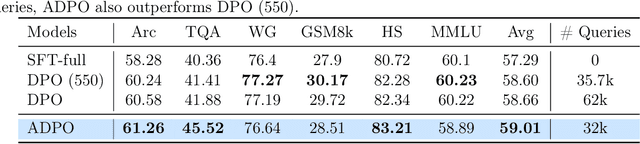

Aligning large language models (LLM) with human preference plays a key role in building modern generative models and can be achieved by reinforcement learning from human feedback (RLHF). Despite their superior performance, current RLHF approaches often require a large amount of human-labelled preference data, which is expensive to collect. In this paper, inspired by the success of active learning, we address this problem by proposing query-efficient RLHF methods. We first formalize the alignment problem as a contextual dueling bandit problem and design an active-query-based proximal policy optimization (APPO) algorithm with an $\tilde{O}(d^2/\Delta)$ regret bound and an $\tilde{O}(d^2/\Delta^2)$ query complexity, where $d$ is the dimension of feature space and $\Delta$ is the sub-optimality gap over all the contexts. We then propose ADPO, a practical version of our algorithm based on direct preference optimization (DPO) and apply it to fine-tuning LLMs. Our experiments show that ADPO, while only making about half of queries for human preference, matches the performance of the state-of-the-art DPO method.
A Nearly Optimal and Low-Switching Algorithm for Reinforcement Learning with General Function Approximation
Nov 26, 2023The exploration-exploitation dilemma has been a central challenge in reinforcement learning (RL) with complex model classes. In this paper, we propose a new algorithm, Monotonic Q-Learning with Upper Confidence Bound (MQL-UCB) for RL with general function approximation. Our key algorithmic design includes (1) a general deterministic policy-switching strategy that achieves low switching cost, (2) a monotonic value function structure with carefully controlled function class complexity, and (3) a variance-weighted regression scheme that exploits historical trajectories with high data efficiency. MQL-UCB achieves minimax optimal regret of $\tilde{O}(d\sqrt{HK})$ when $K$ is sufficiently large and near-optimal policy switching cost of $\tilde{O}(dH)$, with $d$ being the eluder dimension of the function class, $H$ being the planning horizon, and $K$ being the number of episodes. Our work sheds light on designing provably sample-efficient and deployment-efficient Q-learning with nonlinear function approximation.
Pessimistic Nonlinear Least-Squares Value Iteration for Offline Reinforcement Learning
Oct 02, 2023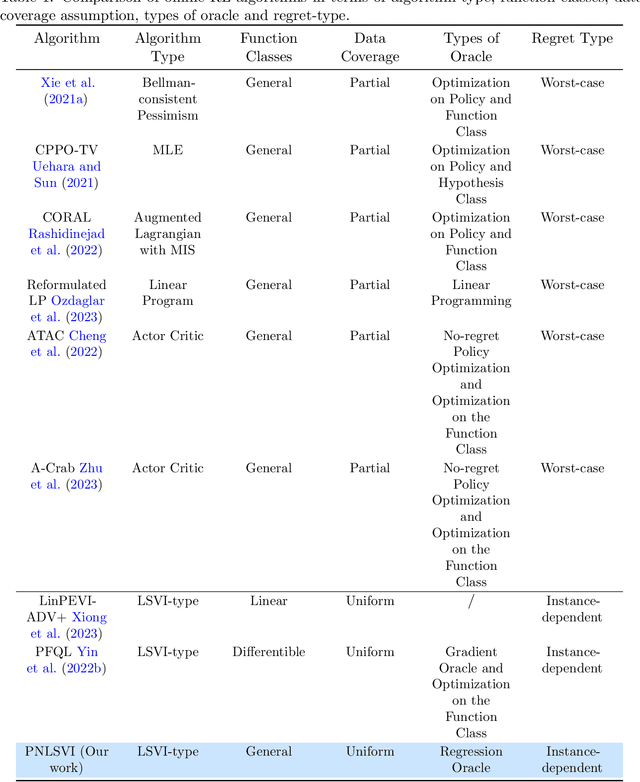
Offline reinforcement learning (RL), where the agent aims to learn the optimal policy based on the data collected by a behavior policy, has attracted increasing attention in recent years. While offline RL with linear function approximation has been extensively studied with optimal results achieved under certain assumptions, many works shift their interest to offline RL with non-linear function approximation. However, limited works on offline RL with non-linear function approximation have instance-dependent regret guarantees. In this paper, we propose an oracle-efficient algorithm, dubbed Pessimistic Nonlinear Least-Square Value Iteration (PNLSVI), for offline RL with non-linear function approximation. Our algorithmic design comprises three innovative components: (1) a variance-based weighted regression scheme that can be applied to a wide range of function classes, (2) a subroutine for variance estimation, and (3) a planning phase that utilizes a pessimistic value iteration approach. Our algorithm enjoys a regret bound that has a tight dependency on the function class complexity and achieves minimax optimal instance-dependent regret when specialized to linear function approximation. Our work extends the previous instance-dependent results within simpler function classes, such as linear and differentiable function to a more general framework.
Uniform-PAC Guarantees for Model-Based RL with Bounded Eluder Dimension
May 15, 2023Recently, there has been remarkable progress in reinforcement learning (RL) with general function approximation. However, all these works only provide regret or sample complexity guarantees. It is still an open question if one can achieve stronger performance guarantees, i.e., the uniform probably approximate correctness (Uniform-PAC) guarantee that can imply both a sub-linear regret bound and a polynomial sample complexity for any target learning accuracy. We study this problem by proposing algorithms for both nonlinear bandits and model-based episodic RL using the general function class with a bounded eluder dimension. The key idea of the proposed algorithms is to assign each action to different levels according to its width with respect to the confidence set. The achieved uniform-PAC sample complexity is tight in the sense that it matches the state-of-the-art regret bounds or sample complexity guarantees when reduced to the linear case. To the best of our knowledge, this is the first work for uniform-PAC guarantees on bandit and RL that goes beyond linear cases.