 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension-Independent Convergence of Underdamped Langevin Monte Carlo in KL Divergence
Mar 02, 2026Underdamped Langevin dynamics (ULD) is a widely-used sampler for Gibbs distributions $π\propto e^{-V}$, and is often empirically effective in high dimensions. However, existing non-asymptotic convergence guarantees for discretized ULD typically scale polynomially with the ambient dimension $d$, leading to vacuous bounds when $d$ is large. The main known dimension-free result concerns the randomized midpoint discretization in Wasserstein-2 distance (Liu et al.,2023), while dimension-independent guarantees for ULD discretizations in KL divergence have remained open. We close this gap by proving the first dimension-free KL divergence bounds for discretized ULD. Our analysis refines the KL local error framework (Altschuler et al., 2025) to a dimension-free setting and yields bounds that depend on $\mathrm{tr}(\mathbf{H})$, where $\mathbf{H}$ upper bounds the Hessian of $V$, rather than on $d$. As a consequence, we obtain improved iteration complexity for underdamped Langevin Monte Carlo relative to overdamped Langevin methods in regimes where $\mathrm{tr}(\mathbf{H})\ll d$.
Understanding SGD with Exponential Moving Average: A Case Study in Linear Regression
Feb 19, 2025Exponential moving average (EMA) has recently gained significant popularity in training modern deep learning models, especially diffusion-based generative models. However, there have been few theoretical results explaining the effectiveness of EMA. In this paper, to better understand EMA, we establish the risk bound of online SGD with EMA for high-dimensional linear regression, one of the simplest overparameterized learning tasks that shares similarities with neural networks. Our results indicate that (i) the variance error of SGD with EMA is always smaller than that of SGD without averaging, and (ii) unlike SGD with iterate averaging from the beginning, the bias error of SGD with EMA decays exponentially in every eigen-subspace of the data covariance matrix. Additionally, we develop proof techniques applicable to the analysis of a broad class of averaging schemes.
Automated Proof Generation for Rust Code via Self-Evolution
Oct 21, 2024



Ensuring correctness is crucial for code generation. Formal verification offers a definitive assurance of correctness, but demands substantial human effort in proof construction and hence raises a pressing need for automation. The primary obstacle lies in the severe lack of data - there is much less proof than code for LLMs to train upon. In this paper, we introduce SAFE, a novel framework that overcomes the lack of human-written proof to enable automated proof generation of Rust code. SAFE establishes a self-evolving cycle where data synthesis and fine-tuning collaborate to enhance the model capability, leveraging the definitive power of a symbolic verifier in telling correct proof from incorrect ones. SAFE also re-purposes the large number of synthesized incorrect proofs to train the self-debugging capability of the fine-tuned models, empowering them to fix incorrect proofs based on the verifier's feedback. SAFE demonstrates superior efficiency and precision compared to GPT-4o. Through tens of thousands of synthesized proofs and the self-debugging mechanism, we improve the capability of open-source models, initially unacquainted with formal verification, to automatically write proof for Rust code. This advancement leads to a significant improvement in performance, achieving a 70.50% accuracy rate in a benchmark crafted by human experts, a significant leap over GPT-4o's performance of 24.46%.
Feel-Good Thompson Sampling for Contextual Dueling Bandits
Apr 09, 2024

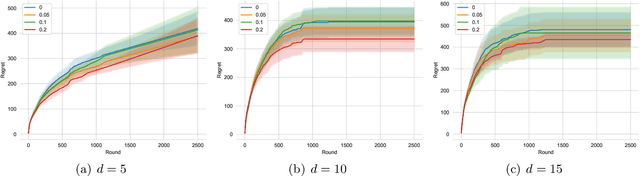
Contextual dueling bandits, where a learner compares two options based on context and receives feedback indicating which was preferred, extends classic dueling bandits by incorporating contextual information for decision-making and preference learning. Several algorithms based on the upper confidence bound (UCB) have been proposed for linear contextual dueling bandits. However, no algorithm based on posterior sampling has been developed in this setting, despite the empirical success observed in traditional contextual bandits. In this paper, we propose a Thompson sampling algorithm, named FGTS.CDB, for linear contextual dueling bandits. At the core of our algorithm is a new Feel-Good exploration term specifically tailored for dueling bandits. This term leverages the independence of the two selected arms, thereby avoiding a cross term in the analysis. We show that our algorithm achieves nearly minimax-optimal regret, i.e., $\tilde{\mathcal{O}}(d\sqrt T)$, where $d$ is the model dimension and $T$ is the time horizon. Finally, we evaluate our algorithm on synthetic data and observe that FGTS.CDB outperforms existing algorithms by a large margin.
Risk Bounds of Accelerated SGD for Overparameterized Linear Regression
Nov 23, 2023
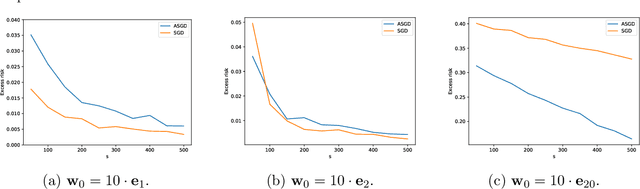


Accelerated stochastic gradient descent (ASGD) is a workhorse in deep learning and often achieves better generalization performance than SGD. However, existing optimization theory can only explain the faster convergence of ASGD, but cannot explain its better generalization. In this paper, we study the generalization of ASGD for overparameterized linear regression, which is possibly the simplest setting of learning with overparameterization. We establish an instance-dependent excess risk bound for ASGD within each eigen-subspace of the data covariance matrix. Our analysis shows that (i) ASGD outperforms SGD in the subspace of small eigenvalues, exhibiting a faster rate of exponential decay for bias error, while in the subspace of large eigenvalues, its bias error decays slower than SGD; and (ii) the variance error of ASGD is always larger than that of SGD. Our result suggests that ASGD can outperform SGD when the difference between the initialization and the true weight vector is mostly confined to the subspace of small eigenvalues. Additionally, when our analysis is specialized to linear regression in the strongly convex setting, it yields a tighter bound for bias error than the best-known result.