 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
Apr 09, 2026Group Relative Policy Optimization (GRPO) has emerged as the de facto Reinforcement Learning (RL) objective driving recent advancements in Multimodal Large Language Models. However, extending this success to open-source multimodal generalist models remains heavily constrained by two primary challenges: the extreme variance in reward topologies across diverse visual tasks, and the inherent difficulty of balancing fine-grained perception with multi-step reasoning capabilities. To address these issues, we introduce Gaussian GRPO (G$^2$RPO), a novel RL training objective that replaces standard linear scaling with non-linear distributional matching. By mathematically forcing the advantage distribution of any given task to strictly converge to a standard normal distribution, $\mathcal{N}(0,1)$, G$^2$RPO theoretically ensures inter-task gradient equity, mitigates vulnerabilities to heavy-tail outliers, and offers symmetric update for positive and negative rewards. Leveraging the enhanced training stability provided by G$^2$RPO, we introduce two task-level shaping mechanisms to seamlessly balance perception and reasoning. First, response length shaping dynamically elicits extended reasoning chains for complex queries while enforce direct outputs to bolster visual grounding. Second, entropy shaping tightly bounds the model's exploration zone, effectively preventing both entropy collapse and entropy explosion. Integrating these methodologies, we present OpenVLThinkerV2, a highly robust, general-purpose multimodal model. Extensive evaluations across 18 diverse benchmarks demonstrate its superior performance over strong open-source and leading proprietary frontier models.
Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
Oct 29, 2025Large Language Models (LLMs) often struggle with problems that require multi-step reasoning. For small-scale open-source models, Reinforcement Learning with Verifiable Rewards (RLVR) fails when correct solutions are rarely sampled even after many attempts, while Supervised Fine-Tuning (SFT) tends to overfit long demonstrations through rigid token-by-token imitation. To address this gap, we propose Supervised Reinforcement Learning (SRL), a framework that reformulates problem solving as generating a sequence of logical "actions". SRL trains the model to generate an internal reasoning monologue before committing to each action. It provides smoother rewards based on the similarity between the model's actions and expert actions extracted from the SFT dataset in a step-wise manner. This supervision offers richer learning signals even when all rollouts are incorrect, while encouraging flexible reasoning guided by expert demonstrations. As a result, SRL enables small models to learn challenging problems previously unlearnable by SFT or RLVR. Moreover, initializing training with SRL before refining with RLVR yields the strongest overall performance. Beyond reasoning benchmarks, SRL generalizes effectively to agentic software engineering tasks, establishing it as a robust and versatile training framework for reasoning-oriented LLMs.
More is Less: The Pitfalls of Multi-Model Synthetic Preference Data in DPO Safety Alignment
Apr 03, 2025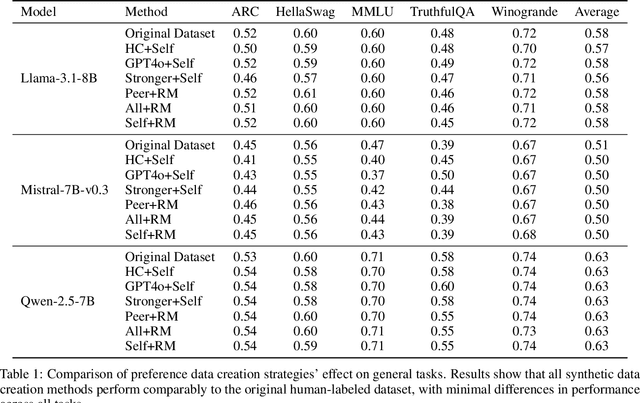
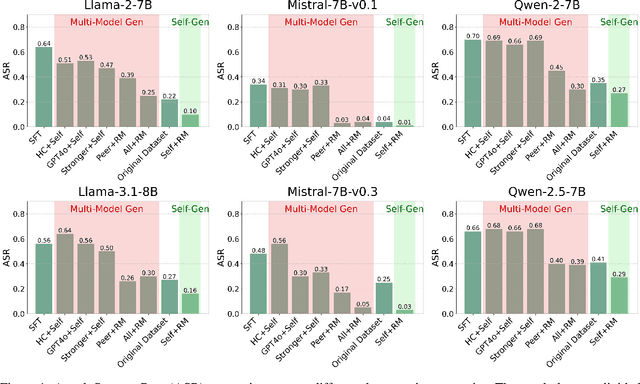
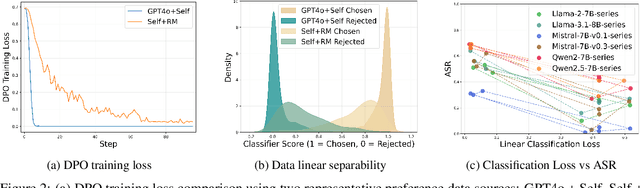

Aligning large language models (LLMs) with human values is an increasingly critical step in post-training. Direct Preference Optimization (DPO) has emerged as a simple, yet effective alternative to reinforcement learning from human feedback (RLHF). Synthetic preference data with its low cost and high quality enable effective alignment through single- or multi-model generated preference data. Our study reveals a striking, safety-specific phenomenon associated with DPO alignment: Although multi-model generated data enhances performance on general tasks (ARC, Hellaswag, MMLU, TruthfulQA, Winogrande) by providing diverse responses, it also tends to facilitate reward hacking during training. This can lead to a high attack success rate (ASR) when models encounter jailbreaking prompts. The issue is particularly pronounced when employing stronger models like GPT-4o or larger models in the same family to generate chosen responses paired with target model self-generated rejected responses, resulting in dramatically poorer safety outcomes. Furthermore, with respect to safety, using solely self-generated responses (single-model generation) for both chosen and rejected pairs significantly outperforms configurations that incorporate responses from stronger models, whether used directly as chosen data or as part of a multi-model response pool. We demonstrate that multi-model preference data exhibits high linear separability between chosen and rejected responses, which allows models to exploit superficial cues rather than internalizing robust safety constraints. Our experiments, conducted on models from the Llama, Mistral, and Qwen families, consistently validate these findings.
Entropy-Based Adaptive Weighting for Self-Training
Mar 31, 2025



The mathematical problem-solving capabilities of large language models have become a focal point of research, with growing interests in leveraging self-generated reasoning paths as a promising way to refine and enhance these models. These paths capture step-by-step logical processes while requiring only the correct answer for supervision. The self-training method has been shown to be effective in reasoning tasks while eliminating the need for external models and manual annotations. However, optimizing the use of self-generated data for model training remains an open challenge. In this work, we propose Entropy-Based Adaptive Weighting for Self-Training (EAST), an adaptive weighting strategy designed to prioritize uncertain data during self-training. Specifically, EAST employs a mapping function with a tunable parameter that controls the sharpness of the weighting, assigning higher weights to data where the model exhibits greater uncertainty. This approach guides the model to focus on more informative and challenging examples, thereby enhancing its reasoning ability. We evaluate our approach on GSM8K and MATH benchmarks. Empirical results show that, while the vanilla method yields virtually no improvement (0%) on MATH, EAST achieves around a 1% gain over backbone model. On GSM8K, EAST attains a further 1-2% performance boost compared to the vanilla method.
OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
Mar 21, 2025



Recent advancements demonstrated by DeepSeek-R1 have shown that complex reasoning abilities in large language models (LLMs), including sophisticated behaviors such as self-verification and self-correction, can be achieved by RL with verifiable rewards and significantly improves model performance on challenging tasks such as AIME. Motivated by these findings, our study investigates whether similar reasoning capabilities can be successfully integrated into large vision-language models (LVLMs) and assesses their impact on challenging multimodal reasoning tasks. We consider an approach that iteratively leverages supervised fine-tuning (SFT) on lightweight training data and Reinforcement Learning (RL) to further improve model generalization. Initially, reasoning capabilities were distilled from pure-text R1 models by generating reasoning steps using high-quality captions of the images sourced from diverse visual datasets. Subsequently, iterative RL training further enhance reasoning skills, with each iteration's RL-improved model generating refined SFT datasets for the next round. This iterative process yielded OpenVLThinker, a LVLM exhibiting consistently improved reasoning performance on challenging benchmarks such as MathVista, MathVerse, and MathVision, demonstrating the potential of our strategy for robust vision-language reasoning. The code, model and data are held at https://github.com/yihedeng9/OpenVLThinker.
DuoGuard: A Two-Player RL-Driven Framework for Multilingual LLM Guardrails
Feb 07, 2025



The rapid advancement of large language models (LLMs) has increased the need for guardrail models to ensure responsible use, particularly in detecting unsafe and illegal content. While substantial safety data exist in English, multilingual guardrail modeling remains underexplored due to the scarcity of open-source safety data in other languages. To address this gap, we propose a novel two-player Reinforcement Learning (RL) framework, where a generator and a guardrail model co-evolve adversarially to produce high-quality synthetic data for multilingual guardrail training. We theoretically formalize this interaction as a two-player game, proving convergence to a Nash equilibrium. Empirical evaluations show that our model \ours outperforms state-of-the-art models, achieving nearly 10% improvement over LlamaGuard3 (8B) on English benchmarks while being 4.5x faster at inference with a significantly smaller model (0.5B). We achieve substantial advancements in multilingual safety tasks, particularly in addressing the imbalance for lower-resource languages in a collected real dataset. Ablation studies emphasize the critical role of synthetic data generation in bridging the imbalance in open-source data between English and other languages. These findings establish a scalable and efficient approach to synthetic data generation, paving the way for improved multilingual guardrail models to enhance LLM safety. Code, model, and data will be open-sourced at https://github.com/yihedeng9/DuoGuard.
Flow-DPO: Improving LLM Mathematical Reasoning through Online Multi-Agent Learning
Oct 29, 2024



Mathematical reasoning is a crucial capability for Large Language Models (LLMs), yet generating detailed and accurate reasoning traces remains a significant challenge. This paper introduces a novel approach to produce high-quality reasoning traces for LLM fine-tuning using online learning \textbf{Flows}. Our method employs an incremental output production Flow, where component LLMs collaboratively construct solutions through iterative communication. We train the Flow using online Direct Preference Optimization (DPO) learning with rollouts, generating DPO pairs for each training example and updating models in real-time. We directly compare the quality of reasoning traces generated by our method with those produced through direct model inference, demonstrating the effectiveness of our approach in improving LLM performance in mathematical reasoning tasks.
MIRAI: Evaluating LLM Agents for Event Forecasting
Jul 01, 2024



Recent advancements in Large Language Models (LLMs) have empowered LLM agents to autonomously collect world information, over which to conduct reasoning to solve complex problems. Given this capability, increasing interests have been put into employing LLM agents for predicting international events, which can influence decision-making and shape policy development on an international scale. Despite such a growing interest, there is a lack of a rigorous benchmark of LLM agents' forecasting capability and reliability. To address this gap, we introduce MIRAI, a novel benchmark designed to systematically evaluate LLM agents as temporal forecasters in the context of international events. Our benchmark features an agentic environment with tools for accessing an extensive database of historical, structured events and textual news articles. We refine the GDELT event database with careful cleaning and parsing to curate a series of relational prediction tasks with varying forecasting horizons, assessing LLM agents' abilities from short-term to long-term forecasting. We further implement APIs to enable LLM agents to utilize different tools via a code-based interface. In summary, MIRAI comprehensively evaluates the agents' capabilities in three dimensions: 1) autonomously source and integrate critical information from large global databases; 2) write codes using domain-specific APIs and libraries for tool-use; and 3) jointly reason over historical knowledge from diverse formats and time to accurately predict future events. Through comprehensive benchmarking, we aim to establish a reliable framework for assessing the capabilities of LLM agents in forecasting international events, thereby contributing to the development of more accurate and trustworthy models for international relation analysis.
Enhancing Large Vision Language Models with Self-Training on Image Comprehension
May 30, 2024Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs. To address this, we introduce Self-Training on Image Comprehension (STIC), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts. We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies investigate various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training. Code and data are made publicly available.
Mitigating Object Hallucination in Large Vision-Language Models via Classifier-Free Guidance
Feb 13, 2024The advancement of Large Vision-Language Models (LVLMs) has increasingly highlighted the critical issue of their tendency to hallucinate non-existing objects in the images. To address this issue, previous works focused on using specially curated datasets or powerful LLMs (e.g., GPT-3.5) to rectify the outputs of LVLMs. However, these approaches require either expensive training/fine-tuning or API access to advanced LLMs to correct the model's output post-generation. In this paper, we tackle this challenge by introducing a framework called Mitigating hallucinAtion via classifieR-Free guIdaNcE (MARINE), which is both training-free and API-free, and can effectively and efficiently reduce object hallucinations during the generation process. Specifically, MARINE enriches the visual context of LVLMs by integrating existing open-source vision models, and employs classifier-free guidance to incorporate the additional object grounding features to improve the precision of LVLMs' generations. Through comprehensive evaluations across $6$ popular LVLMs with diverse evaluation metrics, we demonstrate the effectiveness of MARINE, which even outperforms existing fine-tuning-based methods. Remarkably, it not only reduces hallucinations but also improves the detailedness of LVLMs' generations, as assessed by GPT-4V.