 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitText: Evolving Agent Tool Ecologies via Memetic Retrieval
May 04, 2026A semantic gap separates how users describe tasks from how tools are documented. As API ecosystems scale to tens of thousands of endpoints, static retrieval from the initial query alone cannot bridge this gap: the agent's understanding of what it needs evolves during execution, but its tool set does not. We introduce FitText, a training-free framework that makes retrieval dynamic by embedding it directly in the agent's reasoning loop. FitText generates natural-language pseudo-tool descriptions as retrieval probes, refines them iteratively using retrieval feedback, and explores diverse alternatives through stochastic generation. Memetic Retrieval adds evolutionary selection pressure over candidate descriptions, guided by a tool memory that avoids redundant search. On ToolRet (43k tools, 4 domains), FitText improves average retrieval rank from 8.81 to 2.78; on StableToolBench (16,464 APIs), it achieves a 0.73 average pass rate--a 24-point absolute gain over static query retrieval. The gains transfer across base models capable of acting as competent semantic operators; under weaker base models, Memetic's evolutionary search inverts--amplifying noise rather than refining signal--surfacing model capacity as a prerequisite for evolutionary tool exploration.
BioVerge: A Comprehensive Benchmark and Study of Self-Evaluating Agents for Biomedical Hypothesis Generation
Nov 12, 2025Hypothesis generation in biomedical research has traditionally centered on uncovering hidden relationships within vast scientific literature, often using methods like Literature-Based Discovery (LBD). Despite progress, current approaches typically depend on single data types or predefined extraction patterns, which restricts the discovery of novel and complex connections. Recent advances in Large Language Model (LLM) agents show significant potential, with capabilities in information retrieval, reasoning, and generation. However, their application to biomedical hypothesis generation has been limited by the absence of standardized datasets and execution environments. To address this, we introduce BioVerge, a comprehensive benchmark, and BioVerge Agent, an LLM-based agent framework, to create a standardized environment for exploring biomedical hypothesis generation at the frontier of existing scientific knowledge. Our dataset includes structured and textual data derived from historical biomedical hypotheses and PubMed literature, organized to support exploration by LLM agents. BioVerge Agent utilizes a ReAct-based approach with distinct Generation and Evaluation modules that iteratively produce and self-assess hypothesis proposals. Through extensive experimentation, we uncover key insights: 1) different architectures of BioVerge Agent influence exploration diversity and reasoning strategies; 2) structured and textual information sources each provide unique, critical contexts that enhance hypothesis generation; and 3) self-evaluation significantly improves the novelty and relevance of proposed hypotheses.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025
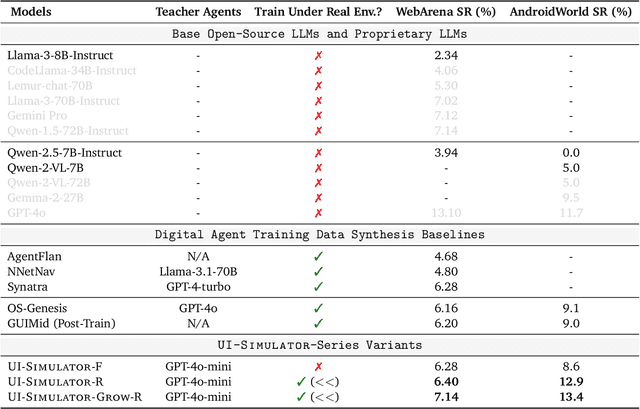

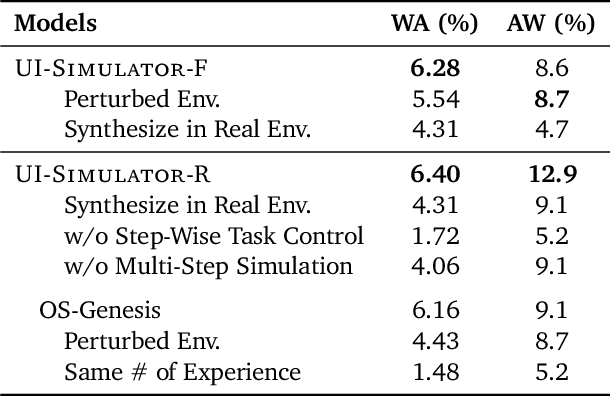
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
Narrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
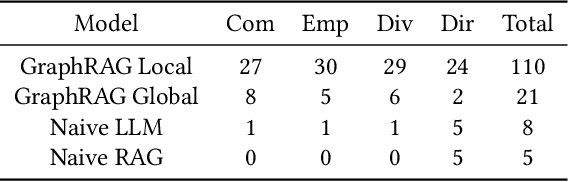

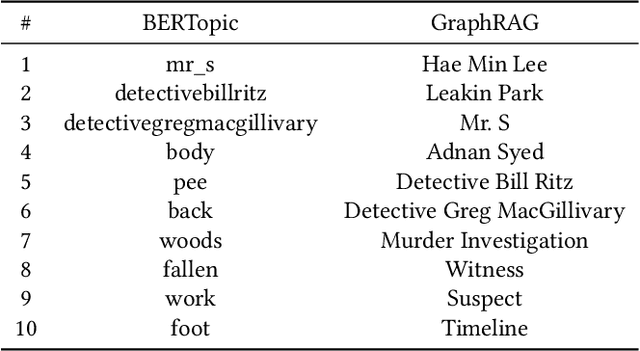
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.
MIRAI: Evaluating LLM Agents for Event Forecasting
Jul 01, 2024



Recent advancements in Large Language Models (LLMs) have empowered LLM agents to autonomously collect world information, over which to conduct reasoning to solve complex problems. Given this capability, increasing interests have been put into employing LLM agents for predicting international events, which can influence decision-making and shape policy development on an international scale. Despite such a growing interest, there is a lack of a rigorous benchmark of LLM agents' forecasting capability and reliability. To address this gap, we introduce MIRAI, a novel benchmark designed to systematically evaluate LLM agents as temporal forecasters in the context of international events. Our benchmark features an agentic environment with tools for accessing an extensive database of historical, structured events and textual news articles. We refine the GDELT event database with careful cleaning and parsing to curate a series of relational prediction tasks with varying forecasting horizons, assessing LLM agents' abilities from short-term to long-term forecasting. We further implement APIs to enable LLM agents to utilize different tools via a code-based interface. In summary, MIRAI comprehensively evaluates the agents' capabilities in three dimensions: 1) autonomously source and integrate critical information from large global databases; 2) write codes using domain-specific APIs and libraries for tool-use; and 3) jointly reason over historical knowledge from diverse formats and time to accurately predict future events. Through comprehensive benchmarking, we aim to establish a reliable framework for assessing the capabilities of LLM agents in forecasting international events, thereby contributing to the development of more accurate and trustworthy models for international relation analysis.
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Jun 14, 2024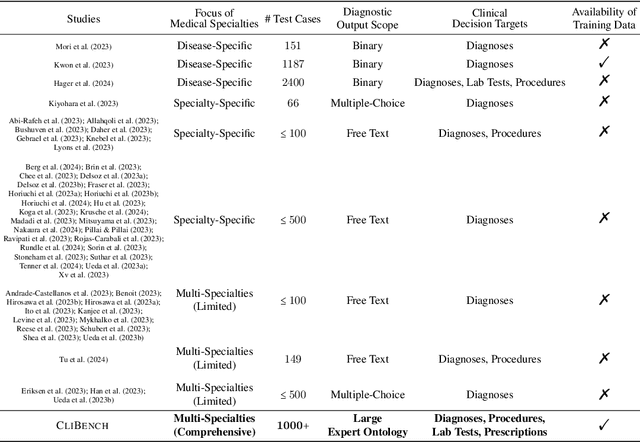



The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
Analyzing Temporal Complex Events with Large Language Models? A Benchmark towards Temporal, Long Context Understanding
Jun 04, 2024



The digital landscape is rapidly evolving with an ever-increasing volume of online news, emphasizing the need for swift and precise analysis of complex events. We refer to the complex events composed of many news articles over an extended period as Temporal Complex Event (TCE). This paper proposes a novel approach using Large Language Models (LLMs) to systematically extract and analyze the event chain within TCE, characterized by their key points and timestamps. We establish a benchmark, named TCELongBench, to evaluate the proficiency of LLMs in handling temporal dynamics and understanding extensive text. This benchmark encompasses three distinct tasks - reading comprehension, temporal sequencing, and future event forecasting. In the experiment, we leverage retrieval-augmented generation (RAG) method and LLMs with long context window to deal with lengthy news articles of TCE. Our findings indicate that models with suitable retrievers exhibit comparable performance with those utilizing long context window.
Structured, Complex and Time-complete Temporal Event Forecasting
Dec 02, 2023



Temporal event forecasting aims to predict what will happen next given the observed events in history. Previous formulations of temporal event are unstructured, atomic, or lacking full temporal information, thus largely restricting the representation quality and forecasting ability of temporal events. To address these limitations, we introduce a novel formulation for Structured, Complex, and Time-complete Temporal Event (SCTc-TE). Based on this new formulation, we develop a simple and fully automated pipeline for constructing such SCTc-TEs from a large amount of news articles. Furthermore, we propose a novel model that leverages both Local and Global contexts for SCTc-TE forecasting, named LoGo. To evaluate our model, we construct two large-scale datasets named MidEast-TE and GDELT-TE. Extensive evaluations demonstrate the advantages of our datasets in multiple aspects, while experimental results justify the effectiveness of our forecasting model LoGo. We release the code and dataset via https://github.com/yecchen/GDELT-ComplexEvent.
Context-aware Event Forecasting via Graph Disentanglement
Aug 12, 2023



Event forecasting has been a demanding and challenging task throughout the entire human history. It plays a pivotal role in crisis alarming and disaster prevention in various aspects of the whole society. The task of event forecasting aims to model the relational and temporal patterns based on historical events and makes forecasting to what will happen in the future. Most existing studies on event forecasting formulate it as a problem of link prediction on temporal event graphs. However, such pure structured formulation suffers from two main limitations: 1) most events fall into general and high-level types in the event ontology, and therefore they tend to be coarse-grained and offers little utility which inevitably harms the forecasting accuracy; and 2) the events defined by a fixed ontology are unable to retain the out-of-ontology contextual information. To address these limitations, we propose a novel task of context-aware event forecasting which incorporates auxiliary contextual information. First, the categorical context provides supplementary fine-grained information to the coarse-grained events. Second and more importantly, the context provides additional information towards specific situation and condition, which is crucial or even determinant to what will happen next. However, it is challenging to properly integrate context into the event forecasting framework, considering the complex patterns in the multi-context scenario. Towards this end, we design a novel framework named Separation and Collaboration Graph Disentanglement (short as SeCoGD) for context-aware event forecasting. Since there is no available dataset for this novel task, we construct three large-scale datasets based on GDELT. Experimental results demonstrate that our model outperforms a list of SOTA methods.
Neural Topic Modeling with Bidirectional Adversarial Training
Apr 26, 2020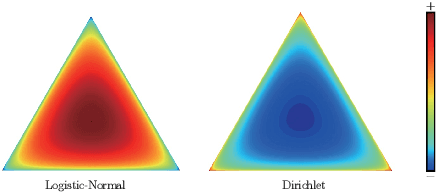
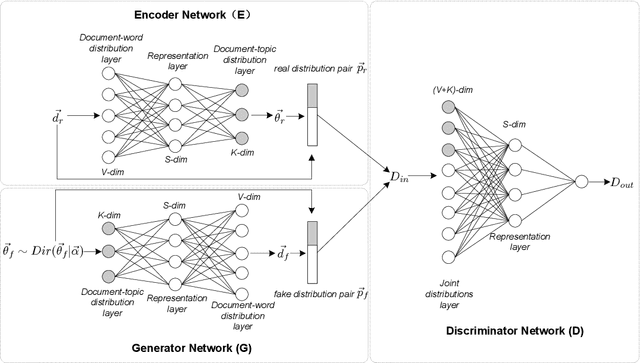
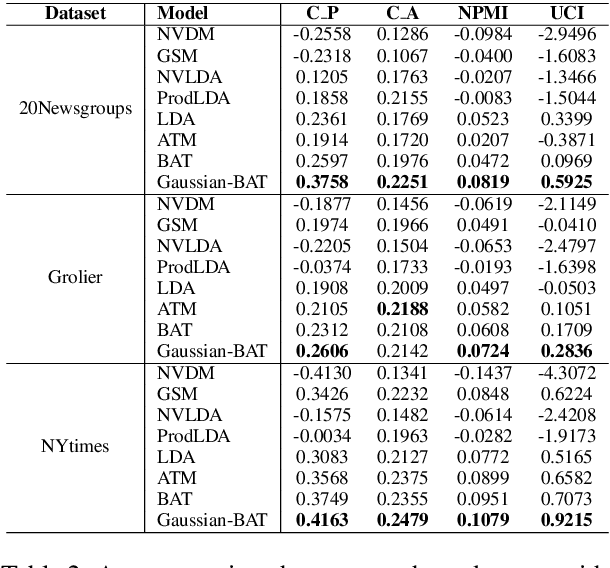
Recent years have witnessed a surge of interests of using neural topic models for automatic topic extraction from text, since they avoid the complicated mathematical derivations for model inference as in traditional topic models such as Latent Dirichlet Allocation (LDA). However, these models either typically assume improper prior (e.g. Gaussian or Logistic Normal) over latent topic space or could not infer topic distribution for a given document. To address these limitations, we propose a neural topic modeling approach, called Bidirectional Adversarial Topic (BAT) model, which represents the first attempt of applying bidirectional adversarial training for neural topic modeling. The proposed BAT builds a two-way projection between the document-topic distribution and the document-word distribution. It uses a generator to capture the semantic patterns from texts and an encoder for topic inference. Furthermore, to incorporate word relatedness information, the Bidirectional Adversarial Topic model with Gaussian (Gaussian-BAT) is extended from BAT. To verify the effectiveness of BAT and Gaussian-BAT, three benchmark corpora are used in our experiments. The experimental results show that BAT and Gaussian-BAT obtain more coherent topics, outperforming several competitive baselines. Moreover, when performing text clustering based on the extracted topics, our models outperform all the baselines, with more significant improvements achieved by Gaussian-BAT where an increase of near 6\% is observed in accuracy.