 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMFlow: Refined Mean Flow by a Noise-Injection Step for Multimodal Generation
Jan 31, 2026Mean flow (MeanFlow) enables efficient, high-fidelity image generation, yet its single-function evaluation (1-NFE) generation often cannot yield compelling results. We address this issue by introducing RMFlow, an efficient multimodal generative model that integrates a coarse 1-NFE MeanFlow transport with a subsequent tailored noise-injection refinement step. RMFlow approximates the average velocity of the flow path using a neural network trained with a new loss function that balances minimizing the Wasserstein distance between probability paths and maximizing sample likelihood. RMFlow achieves near state-of-the-art results on text-to-image, context-to-molecule, and time-series generation using only 1-NFE, at a computational cost comparable to the baseline MeanFlows.
Topology-Aware Active Learning on Graphs
Oct 29, 2025We propose a graph-topological approach to active learning that directly targets the core challenge of exploration versus exploitation under scarce label budgets. To guide exploration, we introduce a coreset construction algorithm based on Balanced Forman Curvature (BFC), which selects representative initial labels that reflect the graph's cluster structure. This method includes a data-driven stopping criterion that signals when the graph has been sufficiently explored. We further use BFC to dynamically trigger the shift from exploration to exploitation within active learning routines, replacing hand-tuned heuristics. To improve exploitation, we introduce a localized graph rewiring strategy that efficiently incorporates multiscale information around labeled nodes, enhancing label propagation while preserving sparsity. Experiments on benchmark classification tasks show that our methods consistently outperform existing graph-based semi-supervised baselines at low label rates.
STORK: Improving the Fidelity of Mid-NFE Sampling for Diffusion and Flow Matching Models
May 30, 2025Diffusion models (DMs) have demonstrated remarkable performance in high-fidelity image and video generation. Because high-quality generations with DMs typically require a large number of function evaluations (NFEs), resulting in slow sampling, there has been extensive research successfully reducing the NFE to a small range (<10) while maintaining acceptable image quality. However, many practical applications, such as those involving Stable Diffusion 3.5, FLUX, and SANA, commonly operate in the mid-NFE regime (20-50 NFE) to achieve superior results, and, despite the practical relevance, research on the effective sampling within this mid-NFE regime remains underexplored. In this work, we propose a novel, training-free, and structure-independent DM ODE solver called the Stabilized Taylor Orthogonal Runge--Kutta (STORK) method, based on a class of stiff ODE solvers with a Taylor expansion adaptation. Unlike prior work such as DPM-Solver, which is dependent on the semi-linear structure of the DM ODE, STORK is applicable to any DM sampling, including noise-based and flow matching-based models. Within the 20-50 NFE range, STORK achieves improved generation quality, as measured by FID scores, across unconditional pixel-level generation and conditional latent-space generation tasks using models like Stable Diffusion 3.5 and SANA. Code is available at https://github.com/ZT220501/STORK.
GLL: A Differentiable Graph Learning Layer for Neural Networks
Dec 11, 2024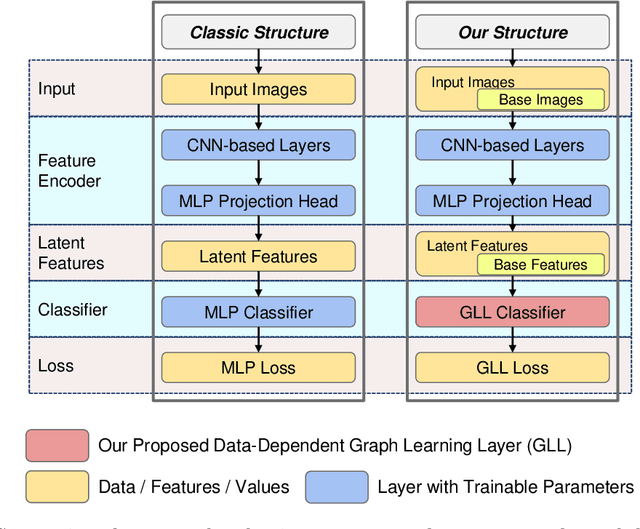
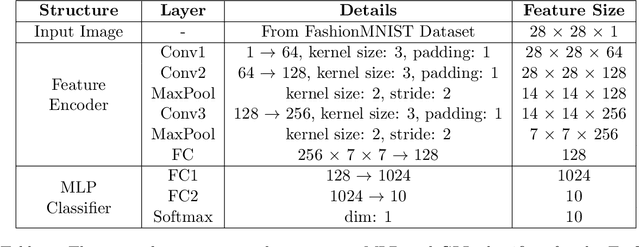


Standard deep learning architectures used for classification generate label predictions with a projection head and softmax activation function. Although successful, these methods fail to leverage the relational information between samples in the batch for generating label predictions. In recent works, graph-based learning techniques, namely Laplace learning, have been heuristically combined with neural networks for both supervised and semi-supervised learning (SSL) tasks. However, prior works approximate the gradient of the loss function with respect to the graph learning algorithm or decouple the processes; end-to-end integration with neural networks is not achieved. In this work, we derive backpropagation equations, via the adjoint method, for inclusion of a general family of graph learning layers into a neural network. This allows us to precisely integrate graph Laplacian-based label propagation into a neural network layer, replacing a projection head and softmax activation function for classification tasks. Using this new framework, our experimental results demonstrate smooth label transitions across data, improved robustness to adversarial attacks, improved generalization, and improved training dynamics compared to the standard softmax-based approach.
Robot Swarming over the internet
Nov 06, 2024
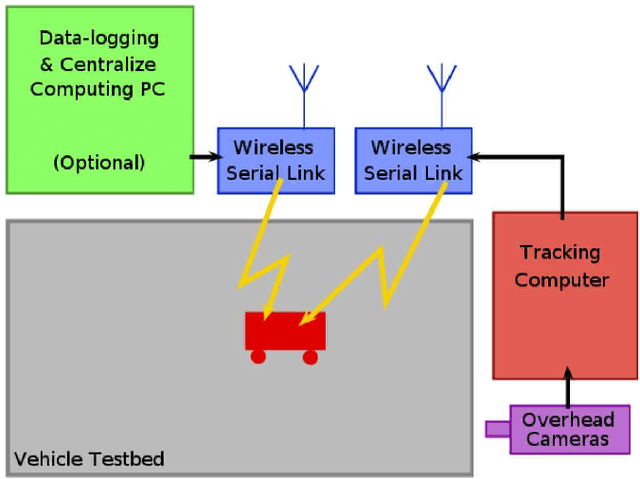

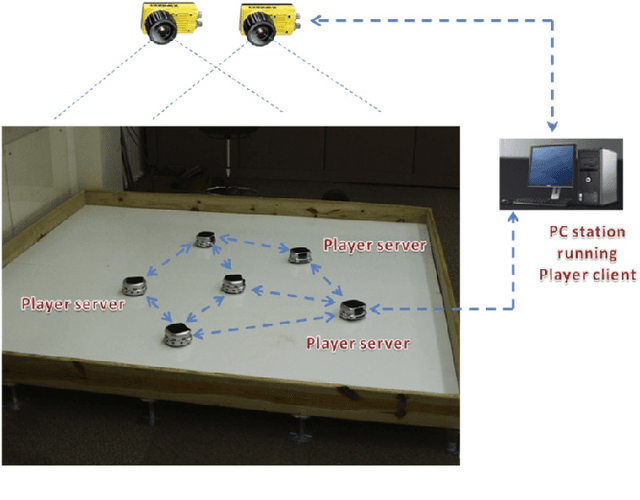
This paper considers cooperative control of robots involving two different testbed systems in remote locations with communication on the internet. This provides us the capability to exchange robots status like positions, velocities and directions needed for the swarming algorithm. The results show that all robots properly follow some leader defined one of the testbeds. Measurement of data exchange rates show no loss of packets, and average transfer delays stay within tolerance limits for practical applications. In our knowledge, the novelty of this paper concerns this kind of control over a large network like internet.
Detection and tracking of gas plumes in LWIR hyperspectral video sequence data
Nov 01, 2024Automated detection of chemical plumes presents a segmentation challenge. The segmentation problem for gas plumes is difficult due to the diffusive nature of the cloud. The advantage of considering hyperspectral images in the gas plume detection problem over the conventional RGB imagery is the presence of non-visual data, allowing for a richer representation of information. In this paper we present an effective method of visualizing hyperspectral video sequences containing chemical plumes and investigate the effectiveness of segmentation techniques on these post-processed videos. Our approach uses a combination of dimension reduction and histogram equalization to prepare the hyperspectral videos for segmentation. First, Principal Components Analysis (PCA) is used to reduce the dimension of the entire video sequence. This is done by projecting each pixel onto the first few Principal Components resulting in a type of spectral filter. Next, a Midway method for histogram equalization is used. These methods redistribute the intensity values in order to reduce flicker between frames. This properly prepares these high-dimensional video sequences for more traditional segmentation techniques. We compare the ability of various clustering techniques to properly segment the chemical plume. These include K-means, spectral clustering, and the Ginzburg-Landau functional.
Narrative Analysis of True Crime Podcasts With Knowledge Graph-Augmented Large Language Models
Nov 01, 2024
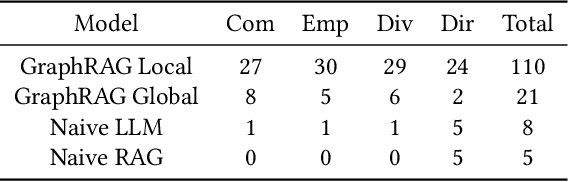

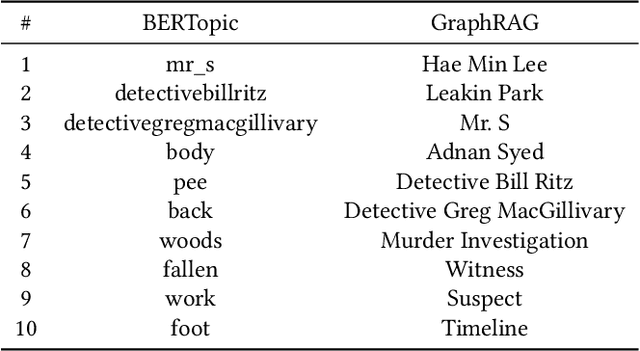
Narrative data spans all disciplines and provides a coherent model of the world to the reader or viewer. Recent advancement in machine learning and Large Language Models (LLMs) have enable great strides in analyzing natural language. However, Large language models (LLMs) still struggle with complex narrative arcs as well as narratives containing conflicting information. Recent work indicates LLMs augmented with external knowledge bases can improve the accuracy and interpretability of the resulting models. In this work, we analyze the effectiveness of applying knowledge graphs (KGs) in understanding true-crime podcast data from both classical Natural Language Processing (NLP) and LLM approaches. We directly compare KG-augmented LLMs (KGLLMs) with classical methods for KG construction, topic modeling, and sentiment analysis. Additionally, the KGLLM allows us to query the knowledge base in natural language and test its ability to factually answer questions. We examine the robustness of the model to adversarial prompting in order to test the model's ability to deal with conflicting information. Finally, we apply classical methods to understand more subtle aspects of the text such as the use of hearsay and sentiment in narrative construction and propose future directions. Our results indicate that KGLLMs outperform LLMs on a variety of metrics, are more robust to adversarial prompts, and are more capable of summarizing the text into topics.
A Primal-Dual Framework for Transformers and Neural Networks
Jun 19, 2024Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
AutoKG: Efficient Automated Knowledge Graph Generation for Language Models
Nov 22, 2023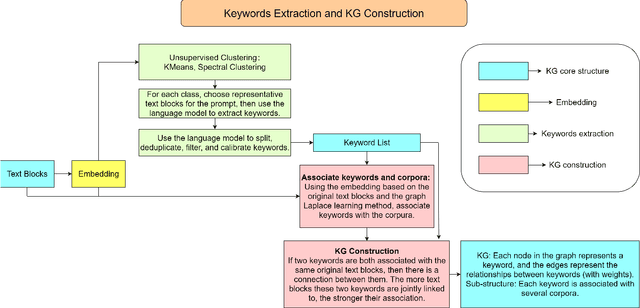


Traditional methods of linking large language models (LLMs) to knowledge bases via the semantic similarity search often fall short of capturing complex relational dynamics. To address these limitations, we introduce AutoKG, a lightweight and efficient approach for automated knowledge graph (KG) construction. For a given knowledge base consisting of text blocks, AutoKG first extracts keywords using a LLM and then evaluates the relationship weight between each pair of keywords using graph Laplace learning. We employ a hybrid search scheme combining vector similarity and graph-based associations to enrich LLM responses. Preliminary experiments demonstrate that AutoKG offers a more comprehensive and interconnected knowledge retrieval mechanism compared to the semantic similarity search, thereby enhancing the capabilities of LLMs in generating more insightful and relevant outputs.
Novel Batch Active Learning Approach and Its Application to Synthetic Aperture Radar Datasets
Jul 19, 2023Active learning improves the performance of machine learning methods by judiciously selecting a limited number of unlabeled data points to query for labels, with the aim of maximally improving the underlying classifier's performance. Recent gains have been made using sequential active learning for synthetic aperture radar (SAR) data arXiv:2204.00005. In each iteration, sequential active learning selects a query set of size one while batch active learning selects a query set of multiple datapoints. While batch active learning methods exhibit greater efficiency, the challenge lies in maintaining model accuracy relative to sequential active learning methods. We developed a novel, two-part approach for batch active learning: Dijkstra's Annulus Core-Set (DAC) for core-set generation and LocalMax for batch sampling. The batch active learning process that combines DAC and LocalMax achieves nearly identical accuracy as sequential active learning but is more efficient, proportional to the batch size. As an application, a pipeline is built based on transfer learning feature embedding, graph learning, DAC, and LocalMax to classify the FUSAR-Ship and OpenSARShip datasets. Our pipeline outperforms the state-of-the-art CNN-based methods.
* 16 pages, 7 figures, Preprint