 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiTimeCrossNet: Time-Aware Self-Supervised Learning for Pediatric Sleep
Feb 02, 2026We present BiTimeCrossNet (BTCNet), a multimodal self-supervised learning framework for long physiological recordings such as overnight sleep studies. While many existing approaches train on short segments treated as independent samples, BTCNet incorporates information about when each segment occurs within its parent recording, for example within a sleep session. BTCNet further learns pairwise interactions between physiological signals via cross-attention, without requiring task labels or sequence-level supervision. We evaluate BTCNet on pediatric sleep data across six downstream tasks, including sleep staging, arousal detection, and respiratory event detection. Under frozen-backbone linear probing, BTCNet consistently outperforms an otherwise identical non-time-aware variant, with gains that generalize to an independent pediatric dataset. Compared to existing multimodal self-supervised sleep models, BTCNet achieves strong performance, particularly on respiration-related tasks.
Federated Learning for Epileptic Seizure Prediction Across Heterogeneous EEG Datasets
Aug 11, 2025Developing accurate and generalizable epileptic seizure prediction models from electroencephalography (EEG) data across multiple clinical sites is hindered by patient privacy regulations and significant data heterogeneity (non-IID characteristics). Federated Learning (FL) offers a privacy-preserving framework for collaborative training, but standard aggregation methods like Federated Averaging (FedAvg) can be biased by dominant datasets in heterogeneous settings. This paper investigates FL for seizure prediction using a single EEG channel across four diverse public datasets (Siena, CHB-MIT, Helsinki, NCH), representing distinct patient populations (adult, pediatric, neonate) and recording conditions. We implement privacy-preserving global normalization and propose a Random Subset Aggregation strategy, where each client trains on a fixed-size random subset of its data per round, ensuring equal contribution during aggregation. Our results show that locally trained models fail to generalize across sites, and standard weighted FedAvg yields highly skewed performance (e.g., 89.0% accuracy on CHB-MIT but only 50.8% on Helsinki and 50.6% on NCH). In contrast, Random Subset Aggregation significantly improves performance on under-represented clients (accuracy increases to 81.7% on Helsinki and 68.7% on NCH) and achieves a superior macro-average accuracy of 77.1% and pooled accuracy of 80.0% across all sites, demonstrating a more robust and fair global model. This work highlights the potential of balanced FL approaches for building effective and generalizable seizure prediction systems in realistic, heterogeneous multi-hospital environments while respecting data privacy.
PedSleepMAE: Generative Model for Multimodal Pediatric Sleep Signals
Nov 01, 2024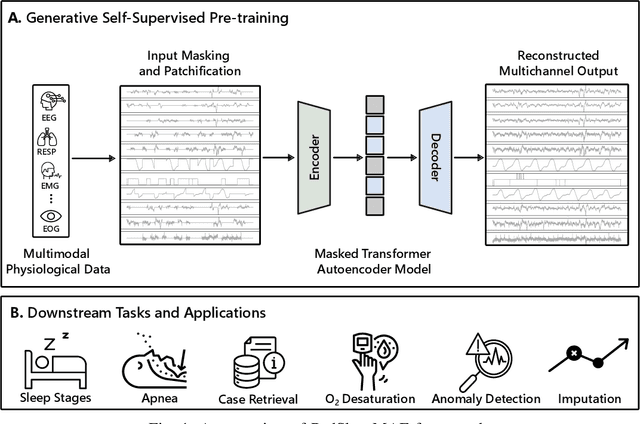
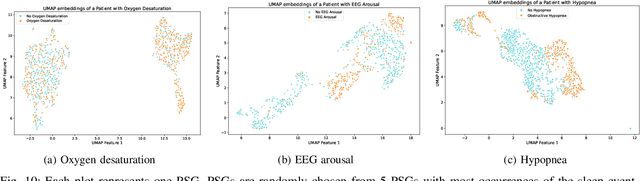
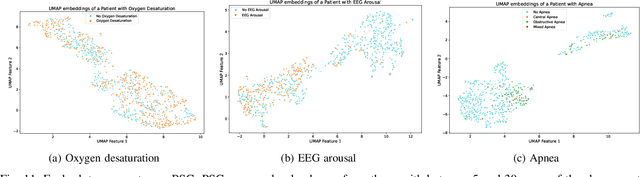

Pediatric sleep is an important but often overlooked area in health informatics. We present PedSleepMAE, a generative model that fully leverages multimodal pediatric sleep signals including multichannel EEGs, respiratory signals, EOGs and EMG. This masked autoencoder-based model performs comparably to supervised learning models in sleep scoring and in the detection of apnea, hypopnea, EEG arousal and oxygen desaturation. Its embeddings are also shown to capture subtle differences in sleep signals coming from a rare genetic disorder. Furthermore, PedSleepMAE generates realistic signals that can be used for sleep segment retrieval, outlier detection, and missing channel imputation. This is the first general-purpose generative model trained on multiple types of pediatric sleep signals.
Explainable Enrichment-Driven GrAph Reasoner (EDGAR) for Large Knowledge Graphs with Applications in Drug Repurposing
Sep 27, 2024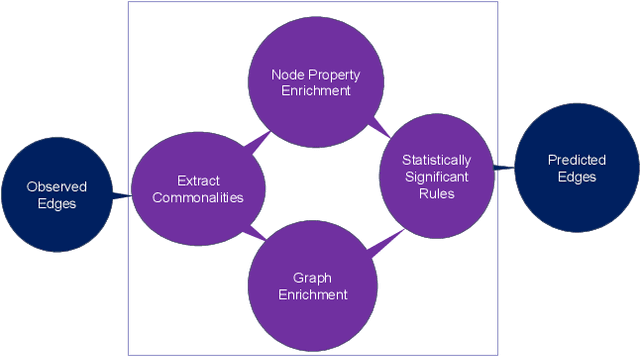
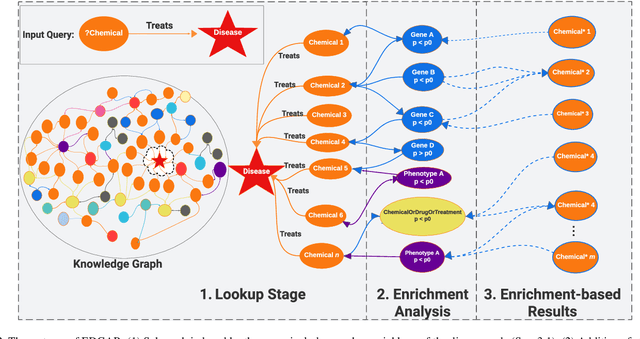

Knowledge graphs (KGs) represent connections and relationships between real-world entities. We propose a link prediction framework for KGs named Enrichment-Driven GrAph Reasoner (EDGAR), which infers new edges by mining entity-local rules. This approach leverages enrichment analysis, a well-established statistical method used to identify mechanisms common to sets of differentially expressed genes. EDGAR's inference results are inherently explainable and rankable, with p-values indicating the statistical significance of each enrichment-based rule. We demonstrate the framework's effectiveness on a large-scale biomedical KG, ROBOKOP, focusing on drug repurposing for Alzheimer disease (AD) as a case study. Initially, we extracted 14 known drugs from the KG and identified 20 contextual biomarkers through enrichment analysis, revealing functional pathways relevant to shared drug efficacy for AD. Subsequently, using the top 1000 enrichment results, our system identified 1246 additional drug candidates for AD treatment. The top 10 candidates were validated using evidence from medical literature. EDGAR is deployed within ROBOKOP, complete with a web user interface. This is the first study to apply enrichment analysis to large graph completion and drug repurposing.
Efficient Trajectory Inference in Wasserstein Space Using Consecutive Averaging
May 30, 2024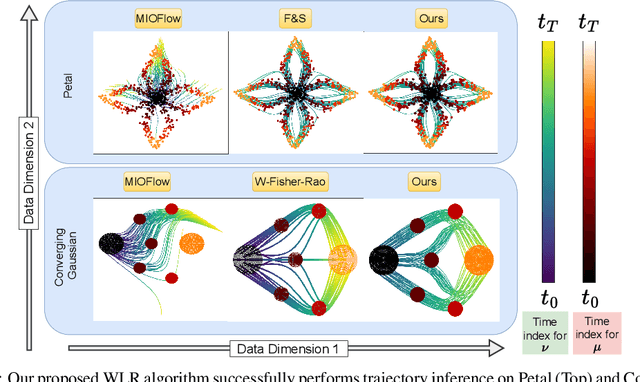
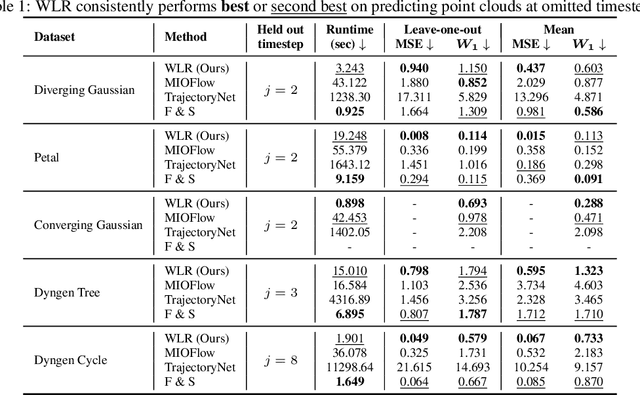
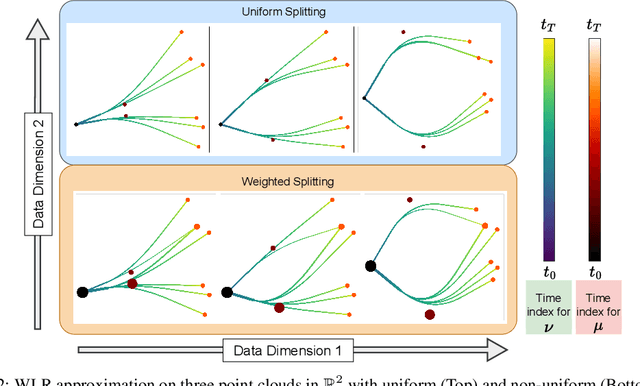

Capturing data from dynamic processes through cross-sectional measurements is seen in many fields such as computational biology. Trajectory inference deals with the challenge of reconstructing continuous processes from such observations. In this work, we propose methods for B-spline approximation and interpolation of point clouds through consecutive averaging that is instrinsic to the Wasserstein space. Combining subdivision schemes with optimal transport-based geodesic, our methods carry out trajectory inference at a chosen level of precision and smoothness, and can automatically handle scenarios where particles undergo division over time. We rigorously evaluate our method by providing convergence guarantees and testing it on simulated cell data characterized by bifurcations and merges, comparing its performance against state-of-the-art trajectory inference and interpolation methods. The results not only underscore the effectiveness of our method in inferring trajectories, but also highlight the benefit of performing interpolation and approximation that respect the inherent geometric properties of the data.
$O(k)$-Equivariant Dimensionality Reduction on Stiefel Manifolds
Sep 19, 2023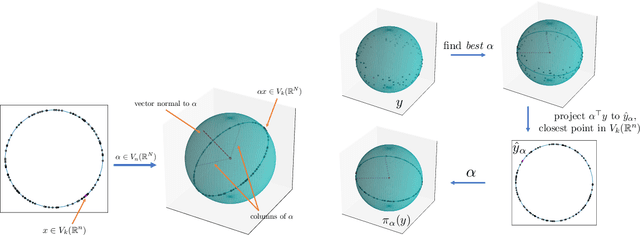

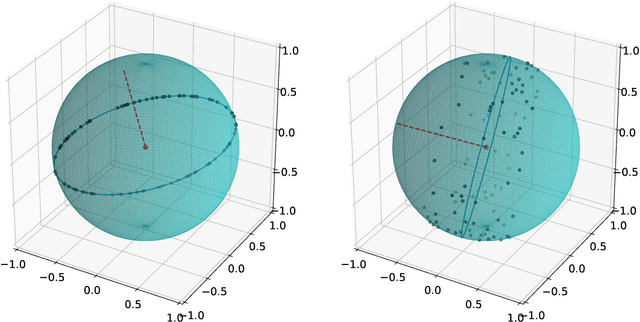
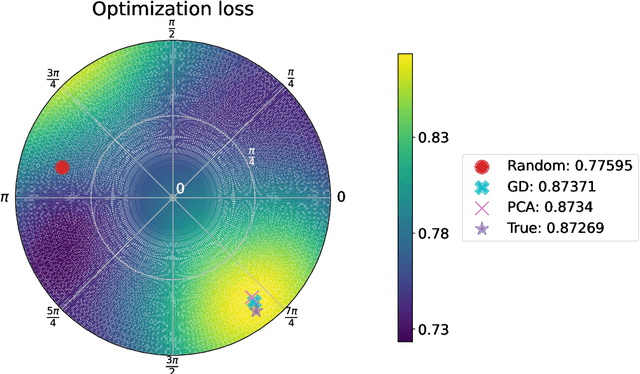
Many real-world datasets live on high-dimensional Stiefel and Grassmannian manifolds, $V_k(\mathbb{R}^N)$ and $Gr(k, \mathbb{R}^N)$ respectively, and benefit from projection onto lower-dimensional Stiefel (respectively, Grassmannian) manifolds. In this work, we propose an algorithm called Principal Stiefel Coordinates (PSC) to reduce data dimensionality from $ V_k(\mathbb{R}^N)$ to $V_k(\mathbb{R}^n)$ in an $O(k)$-equivariant manner ($k \leq n \ll N$). We begin by observing that each element $\alpha \in V_n(\mathbb{R}^N)$ defines an isometric embedding of $V_k(\mathbb{R}^n)$ into $V_k(\mathbb{R}^N)$. Next, we optimize for such an embedding map that minimizes data fit error by warm-starting with the output of principal component analysis (PCA) and applying gradient descent. Then, we define a continuous and $O(k)$-equivariant map $\pi_\alpha$ that acts as a ``closest point operator'' to project the data onto the image of $V_k(\mathbb{R}^n)$ in $V_k(\mathbb{R}^N)$ under the embedding determined by $\alpha$, while minimizing distortion. Because this dimensionality reduction is $O(k)$-equivariant, these results extend to Grassmannian manifolds as well. Lastly, we show that the PCA output globally minimizes projection error in a noiseless setting, but that our algorithm achieves a meaningfully different and improved outcome when the data does not lie exactly on the image of a linearly embedded lower-dimensional Stiefel manifold as above. Multiple numerical experiments using synthetic and real-world data are performed.
Active Learning of Non-semantic Speech Tasks with Pretrained Models
Nov 03, 2022
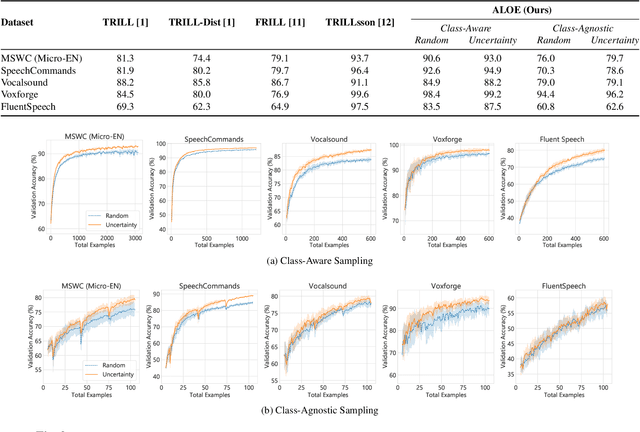

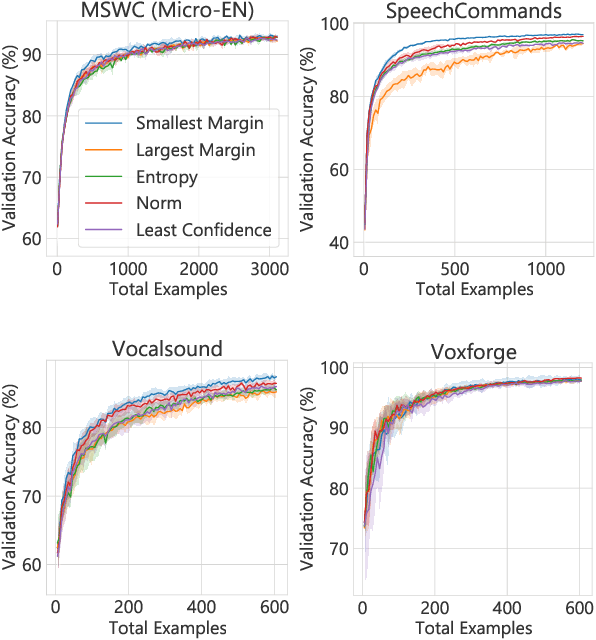
Pretraining neural networks with massive unlabeled datasets has become popular as it equips the deep models with a better prior to solve downstream tasks. However, this approach generally assumes that for downstream tasks, we have access to annotated data of sufficient size. In this work, we propose ALOE, a novel system for improving the data- and label-efficiency of non-semantic speech tasks with active learning (AL). ALOE uses pre-trained models in conjunction with active learning to label data incrementally and learns classifiers for downstream tasks, thereby mitigating the need to acquire labeled data beforehand. We demonstrate the effectiveness of ALOE on a wide range of tasks, uncertainty-based acquisition functions, and model architectures. Training a linear classifier on top of a frozen encoder with ALOE is shown to achieve performance similar to several baselines that utilize the entire labeled data.
Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022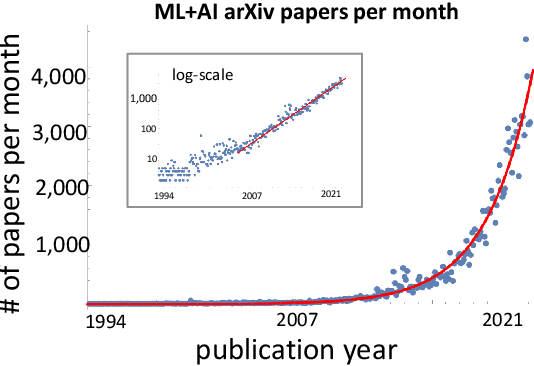
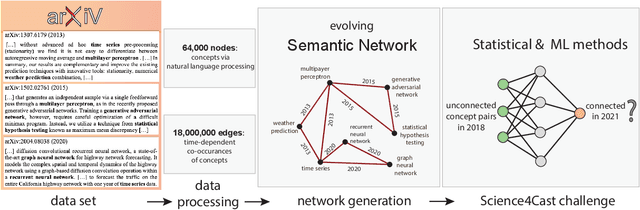
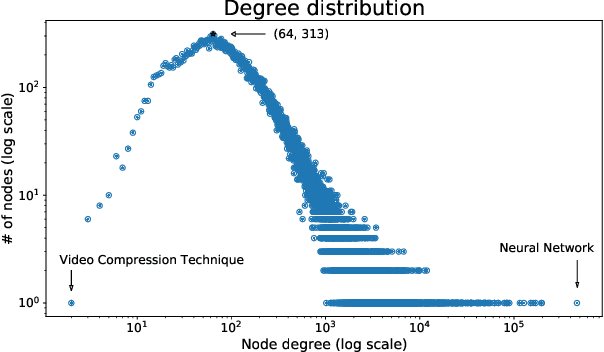
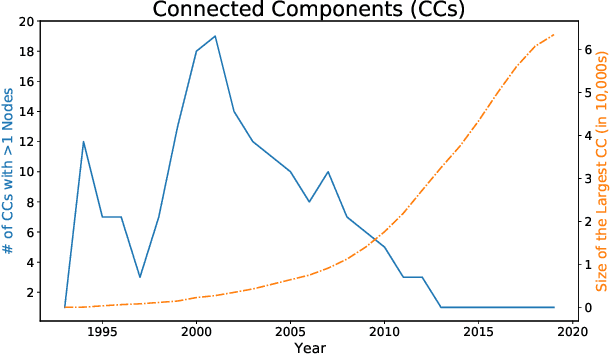
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Distilled Non-Semantic Speech Embeddings with Binary Neural Networks for Low-Resource Devices
Jul 12, 2022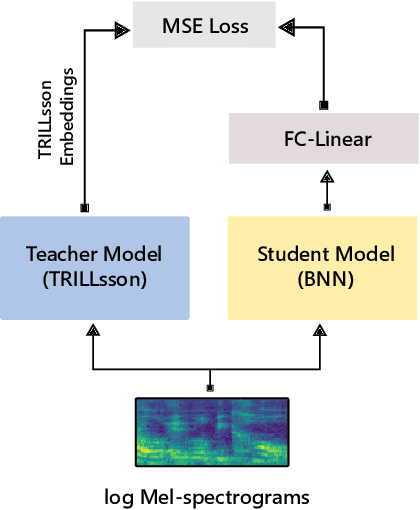
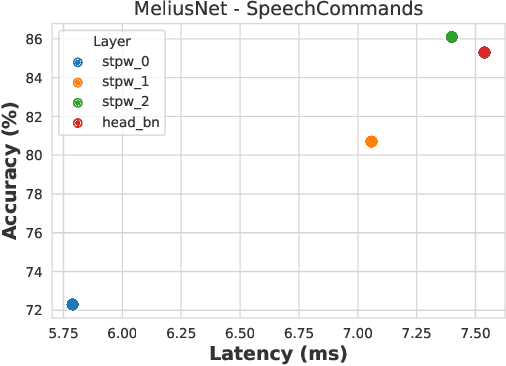

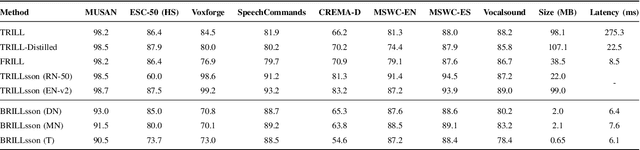
This work introduces BRILLsson, a novel binary neural network-based representation learning model for a broad range of non-semantic speech tasks. We train the model with knowledge distillation from a large and real-valued TRILLsson model with only a fraction of the dataset used to train TRILLsson. The resulting BRILLsson models are only 2MB in size with a latency less than 8ms, making them suitable for deployment in low-resource devices such as wearables. We evaluate BRILLsson on eight benchmark tasks (including but not limited to spoken language identification, emotion recognition, heath condition diagnosis, and keyword spotting), and demonstrate that our proposed ultra-light and low-latency models perform as well as large-scale models.
Pediatric Sleep Scoring In-the-wild from Millions of Multi-channel EEG Signals
Jun 30, 2022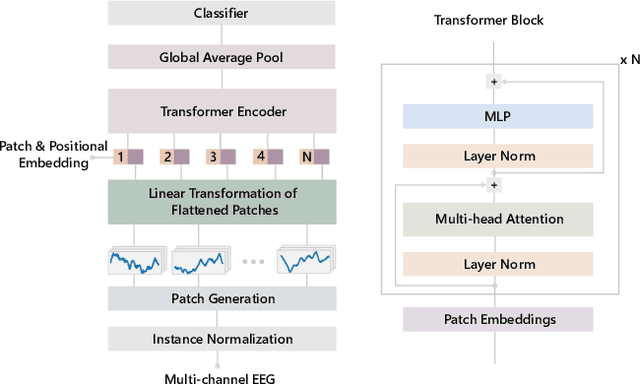

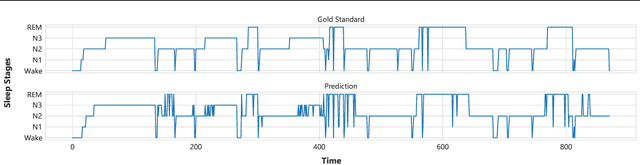
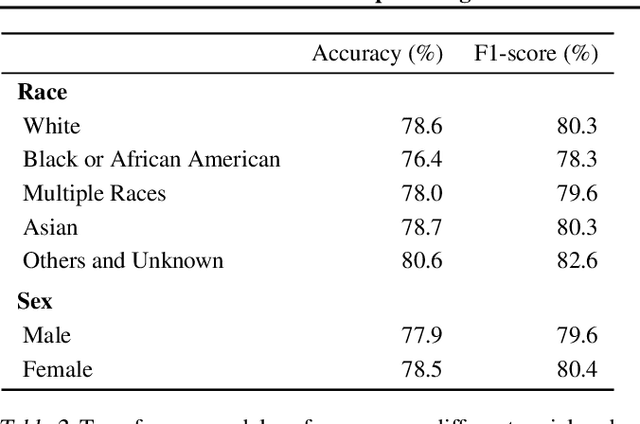
Sleep is critical to the health and development of infants, children, and adolescents, but pediatric sleep is severely under-researched compared to adult sleep in the context of machine learning for health and well-being. Here, we present the first automated pediatric sleep scoring results on a recent large-scale sleep study dataset that was collected during standard clinical care. We develop a transformer-based deep neural network model that learns to classify five sleep stages from millions of multi-channel electroencephalogram (EEG) signals with 78% overall accuracy. Further, we conduct an in-depth analysis of the model performance based on patient demographics and EEG channels.