 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Fixed-Point Constraints in Neural-ODEs with Provable Universality
May 11, 2026We introduce a technique that enables Neural-ODEs to approximate arbitrary velocity fields with a priori planted fixed-points. Specifically, a recipe is given to explicitly accommodate for a finite collection of points in the reference multi-dimensional space of the Neural-ODE where the velocity field is exactly equal to zero. In this way, the gradient-based training is rigorously constrained inside the prescribed hypothesis class while leaving the expressive power of the Neural-ODE unaltered. We rigorously prove the universality of the Neural-ODE under any local constraints in the velocity field and give a computationally convenient way of imposing the fixed points. Our method is then tested on two paradigmatic physical models.
Learning in Wilson-Cowan model for metapopulation
Jun 24, 2024The Wilson-Cowan model for metapopulation, a Neural Mass Network Model, treats different subcortical regions of the brain as connected nodes, with connections representing various types of structural, functional, or effective neuronal connectivity between these regions. Each region comprises interacting populations of excitatory and inhibitory cells, consistent with the standard Wilson-Cowan model. By incorporating stable attractors into such a metapopulation model's dynamics, we transform it into a learning algorithm capable of achieving high image and text classification accuracy. We test it on MNIST and Fashion MNIST, in combination with convolutional neural networks, on CIFAR-10 and TF-FLOWERS, and, in combination with a transformer architecture (BERT), on IMDB, always showing high classification accuracy. These numerical evaluations illustrate that minimal modifications to the Wilson-Cowan model for metapopulation can reveal unique and previously unobserved dynamics.
Automatic Input Feature Relevance via Spectral Neural Networks
Jun 03, 2024Working with high-dimensional data is a common practice, in the field of machine learning. Identifying relevant input features is thus crucial, so as to obtain compact dataset more prone for effective numerical handling. Further, by isolating pivotal elements that form the basis of decision making, one can contribute to elaborate on - ex post - models' interpretability, so far rather elusive. Here, we propose a novel method to estimate the relative importance of the input components for a Deep Neural Network. This is achieved by leveraging on a spectral re-parametrization of the optimization process. Eigenvalues associated to input nodes provide in fact a robust proxy to gauge the relevance of the supplied entry features. Unlike existing techniques, the spectral features ranking is carried out automatically, as a byproduct of the network training. The technique is successfully challenged against both synthetic and real data.
A Short Review on Novel Approaches for Maximum Clique Problem: from Classical algorithms to Graph Neural Networks and Quantum algorithms
Mar 13, 2024This manuscript provides a comprehensive review of the Maximum Clique Problem, a computational problem that involves finding subsets of vertices in a graph that are all pairwise adjacent to each other. The manuscript covers in a simple way classical algorithms for solving the problem and includes a review of recent developments in graph neural networks and quantum algorithms. The review concludes with benchmarks for testing classical as well as new learning, and quantum algorithms.
Engineered Ordinary Differential Equations as Classification Algorithm (EODECA): thorough characterization and testing
Dec 22, 2023EODECA (Engineered Ordinary Differential Equations as Classification Algorithm) is a novel approach at the intersection of machine learning and dynamical systems theory, presenting a unique framework for classification tasks [1]. This method stands out with its dynamical system structure, utilizing ordinary differential equations (ODEs) to efficiently handle complex classification challenges. The paper delves into EODECA's dynamical properties, emphasizing its resilience against random perturbations and robust performance across various classification scenarios. Notably, EODECA's design incorporates the ability to embed stable attractors in the phase space, enhancing reliability and allowing for reversible dynamics. In this paper, we carry out a comprehensive analysis by expanding on the work [1], and employing a Euler discretization scheme. In particular, we evaluate EODECA's performance across five distinct classification problems, examining its adaptability and efficiency. Significantly, we demonstrate EODECA's effectiveness on the MNIST and Fashion MNIST datasets, achieving impressive accuracies of $98.06\%$ and $88.21\%$, respectively. These results are comparable to those of a multi-layer perceptron (MLP), underscoring EODECA's potential in complex data processing tasks. We further explore the model's learning journey, assessing its evolution in both pre and post training environments and highlighting its ability to navigate towards stable attractors. The study also investigates the invertibility of EODECA, shedding light on its decision-making processes and internal workings. This paper presents a significant step towards a more transparent and robust machine learning paradigm, bridging the gap between machine learning algorithms and dynamical systems methodologies.
Complex Recurrent Spectral Network
Dec 12, 2023This paper presents a novel approach to advancing artificial intelligence (AI) through the development of the Complex Recurrent Spectral Network ($\mathbb{C}$-RSN), an innovative variant of the Recurrent Spectral Network (RSN) model. The $\mathbb{C}$-RSN is designed to address a critical limitation in existing neural network models: their inability to emulate the complex processes of biological neural networks dynamically and accurately. By integrating key concepts from dynamical systems theory and leveraging principles from statistical mechanics, the $\mathbb{C}$-RSN model introduces localized non-linearity, complex fixed eigenvalues, and a distinct separation of memory and input processing functionalities. These features collectively enable the $\mathbb{C}$-RSN evolving towards a dynamic, oscillating final state that more closely mirrors biological cognition. Central to this work is the exploration of how the $\mathbb{C}$-RSN manages to capture the rhythmic, oscillatory dynamics intrinsic to biological systems, thanks to its complex eigenvalue structure and the innovative segregation of its linear and non-linear components. The model's ability to classify data through a time-dependent function, and the localization of information processing, is demonstrated with an empirical evaluation using the MNIST dataset. Remarkably, distinct items supplied as a sequential input yield patterns in time which bear the indirect imprint of the insertion order (and of the time of separation between contiguous insertions).
A Bridge between Dynamical Systems and Machine Learning: Engineered Ordinary Differential Equations as Classification Algorithm (EODECA)
Nov 17, 2023In a world increasingly reliant on machine learning, the interpretability of these models remains a substantial challenge, with many equating their functionality to an enigmatic black box. This study seeks to bridge machine learning and dynamical systems. Recognizing the deep parallels between dense neural networks and dynamical systems, particularly in the light of non-linearities and successive transformations, this manuscript introduces the Engineered Ordinary Differential Equations as Classification Algorithms (EODECAs). Uniquely designed as neural networks underpinned by continuous ordinary differential equations, EODECAs aim to capitalize on the well-established toolkit of dynamical systems. Unlike traditional deep learning models, which often suffer from opacity, EODECAs promise both high classification performance and intrinsic interpretability. They are naturally invertible, granting them an edge in understanding and transparency over their counterparts. By bridging these domains, we hope to usher in a new era of machine learning models where genuine comprehension of data processes complements predictive prowess.
How a student becomes a teacher: learning and forgetting through Spectral methods
Nov 03, 2023In theoretical ML, the teacher-student paradigm is often employed as an effective metaphor for real-life tuition. The above scheme proves particularly relevant when the student network is overparameterized as compared to the teacher network. Under these operating conditions, it is tempting to speculate that the student ability to handle the given task could be eventually stored in a sub-portion of the whole network. This latter should be to some extent reminiscent of the frozen teacher structure, according to suitable metrics, while being approximately invariant across different architectures of the student candidate network. Unfortunately, state-of-the-art conventional learning techniques could not help in identifying the existence of such an invariant subnetwork, due to the inherent degree of non-convexity that characterizes the examined problem. In this work, we take a leap forward by proposing a radically different optimization scheme which builds on a spectral representation of the linear transfer of information between layers. The gradient is hence calculated with respect to both eigenvalues and eigenvectors with negligible increase in terms of computational and complexity load, as compared to standard training algorithms. Working in this framework, we could isolate a stable student substructure, that mirrors the true complexity of the teacher in terms of computing neurons, path distribution and topological attributes. When pruning unimportant nodes of the trained student, as follows a ranking that reflects the optimized eigenvalues, no degradation in the recorded performance is seen above a threshold that corresponds to the effective teacher size. The observed behavior can be pictured as a genuine second-order phase transition that bears universality traits.
* 10 pages + references + supplemental material. Poster presentation at NeurIPS 2023
Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022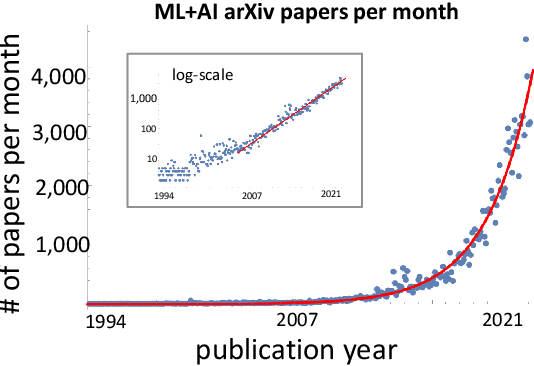
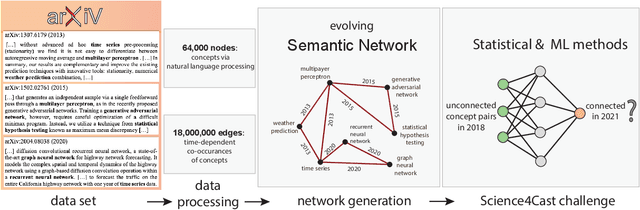
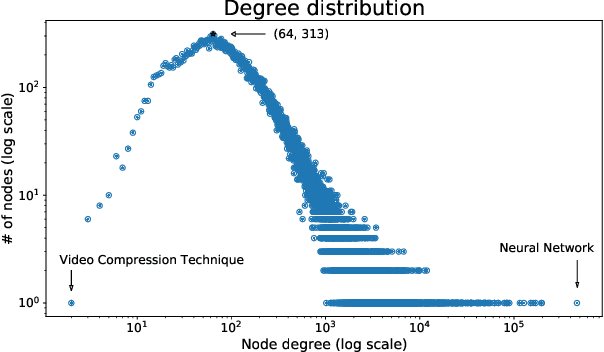
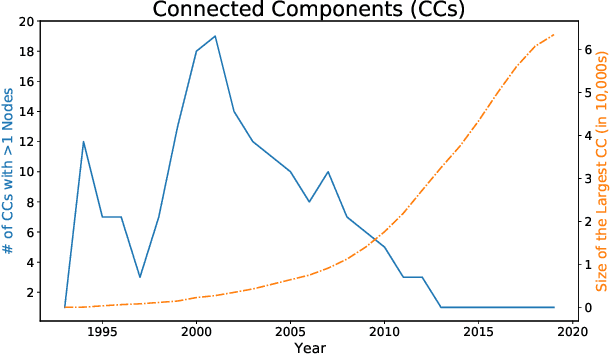
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Noise fingerprints in quantum computers: Machine learning software tools
Feb 09, 2022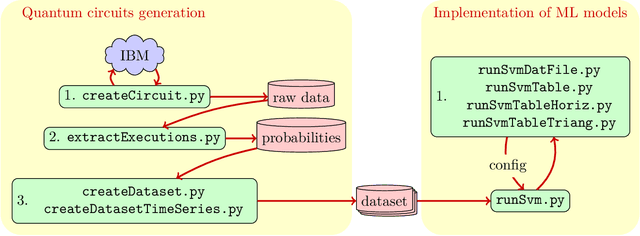
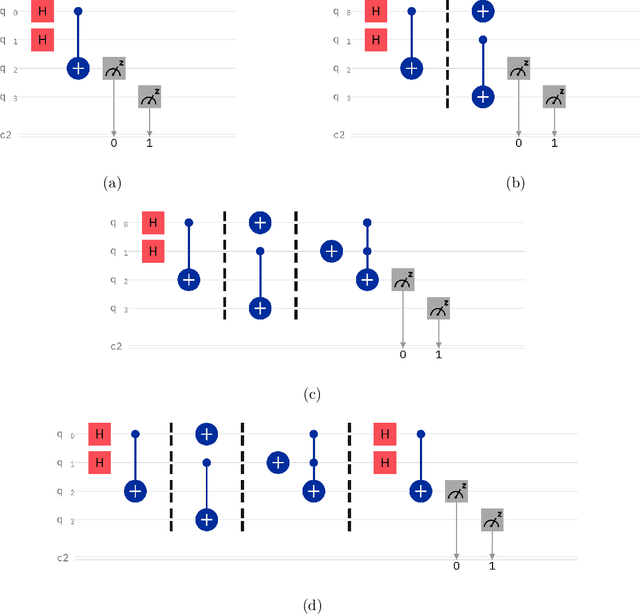
In this paper we present the high-level functionalities of a quantum-classical machine learning software, whose purpose is to learn the main features (the fingerprint) of quantum noise sources affecting a quantum device, as a quantum computer. Specifically, the software architecture is designed to classify successfully (more than 99% of accuracy) the noise fingerprints in different quantum devices with similar technical specifications, or distinct time-dependences of a noise fingerprint in single quantum machines.