 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOOSComp: Improving Lightweight Long-Context Compressor via Mitigating Over-Smoothing and Incorporating Outlier Scores
Apr 23, 2025Recent advances in large language models have significantly improved their ability to process long-context input, but practical applications are challenged by increased inference time and resource consumption, particularly in resource-constrained environments. To address these challenges, we propose MOOSComp, a token-classification-based long-context compression method that enhances the performance of a BERT-based compressor by mitigating the over-smoothing problem and incorporating outlier scores. In the training phase, we add an inter-class cosine similarity loss term to penalize excessively similar token representations, thereby improving the token classification accuracy. During the compression phase, we introduce outlier scores to preserve rare but critical tokens that are prone to be discarded in task-agnostic compression. These scores are integrated with the classifier's output, making the compressor more generalizable to various tasks. Superior performance is achieved at various compression ratios on long-context understanding and reasoning benchmarks. Moreover, our method obtains a speedup of 3.3x at a 4x compression ratio on a resource-constrained mobile device.
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Lumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023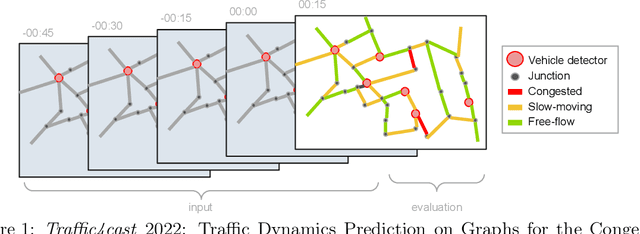
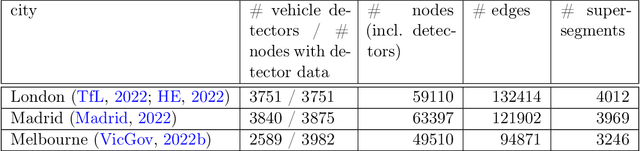
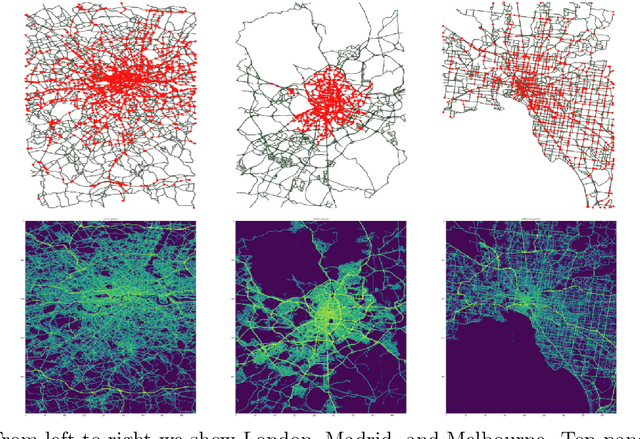
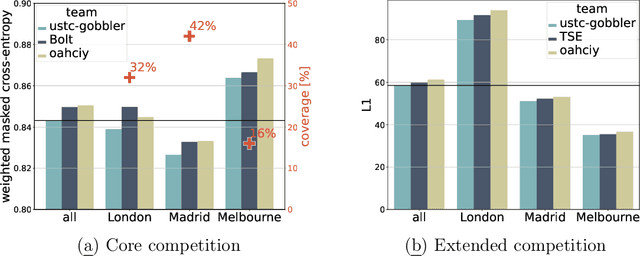
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
An Efficient Two-stage Gradient Boosting Framework for Short-term Traffic State Estimation
Feb 21, 2023Real-time traffic state estimation is essential for intelligent transportation systems. The NeurIPS 2022 Traffic4cast challenge provides an excellent testbed for benchmarking short-term traffic state estimation approaches. This technical report describes our solution to this challenge. In particular, we present an efficient two-stage gradient boosting framework for short-term traffic state estimation. The first stage derives the month, day of the week, and time slot index based on the sparse loop counter data, and the second stage predicts the future traffic states based on the sparse loop counter data and the derived month, day of the week, and time slot index. Experimental results demonstrate that our two-stage gradient boosting framework achieves strong empirical performance, achieving third place in both the core and the extended challenges while remaining highly efficient. The source code for this technical report is available at \url{https://github.com/YichaoLu/Traffic4cast2022}.
Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022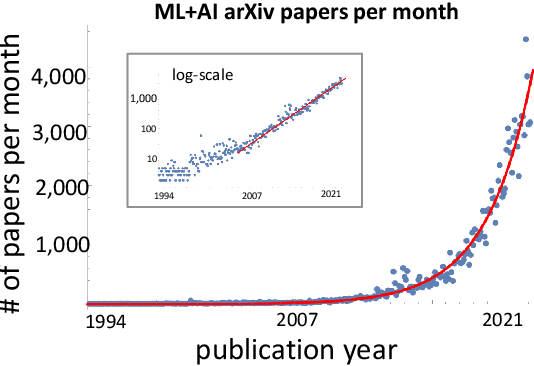
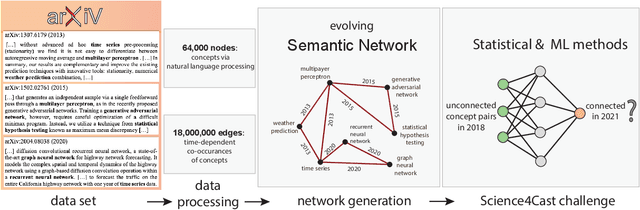
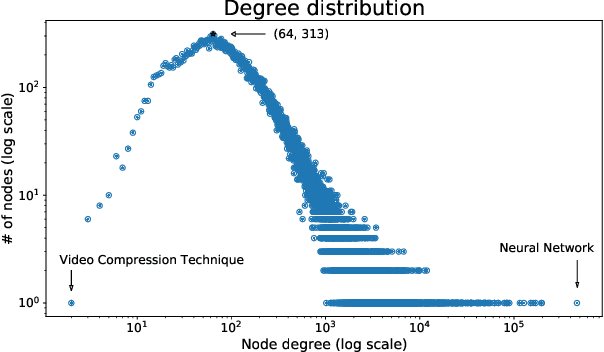
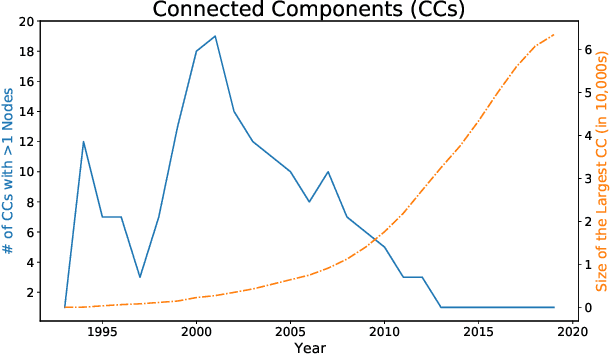
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022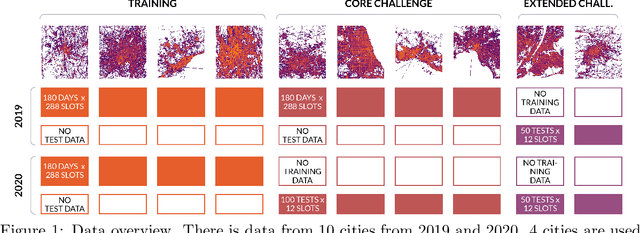
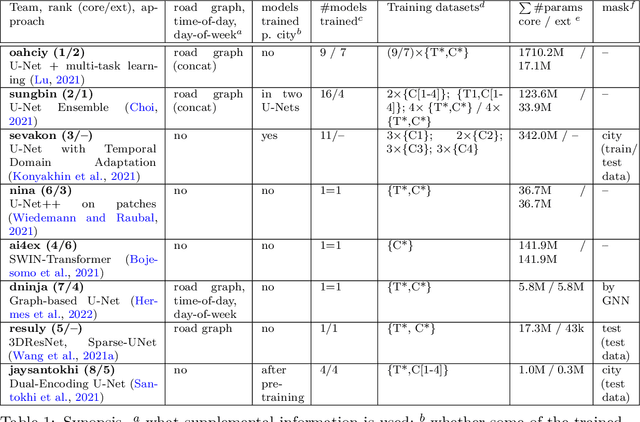
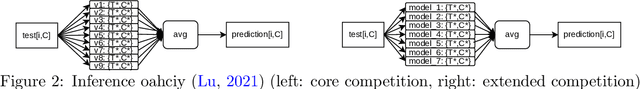
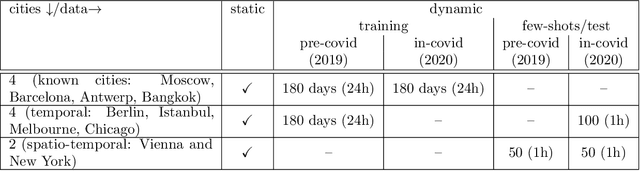
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
Learning to Transfer for Traffic Forecasting via Multi-task Learning
Nov 27, 2021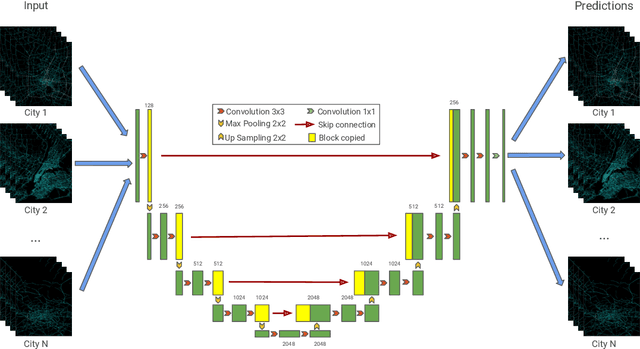
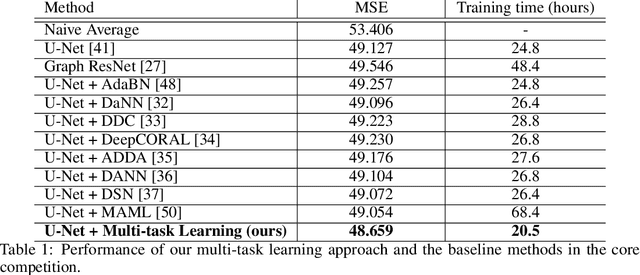

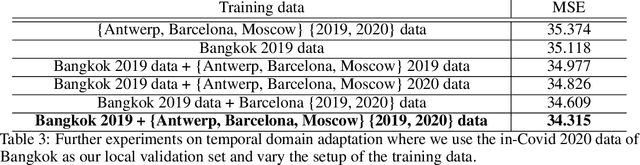
Deep neural networks have demonstrated superior performance in short-term traffic forecasting. However, most existing traffic forecasting systems assume that the training and testing data are drawn from the same underlying distribution, which limits their practical applicability. The NeurIPS 2021 Traffic4cast challenge is the first of its kind dedicated to benchmarking the robustness of traffic forecasting models towards domain shifts in space and time. This technical report describes our solution to this challenge. In particular, we present a multi-task learning framework for temporal and spatio-temporal domain adaptation of traffic forecasting models. Experimental results demonstrate that our multi-task learning approach achieves strong empirical performance, outperforming a number of baseline domain adaptation methods, while remaining highly efficient. The source code for this technical report is available at https://github.com/YichaoLu/Traffic4cast2021.
Unsupervised Bitext Mining and Translation via Self-trained Contextual Embeddings
Oct 15, 2020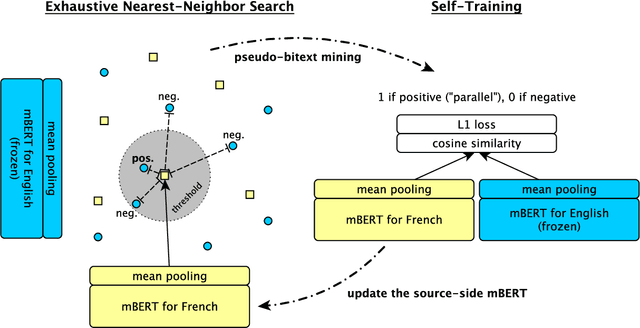
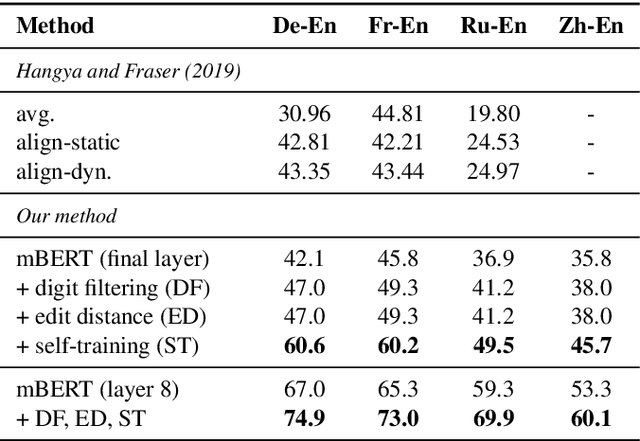

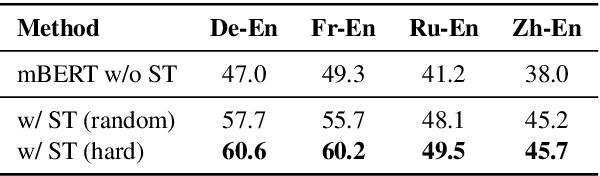
We describe an unsupervised method to create pseudo-parallel corpora for machine translation (MT) from unaligned text. We use multilingual BERT to create source and target sentence embeddings for nearest-neighbor search and adapt the model via self-training. We validate our technique by extracting parallel sentence pairs on the BUCC 2017 bitext mining task and observe up to a 24.5 point increase (absolute) in F1 scores over previous unsupervised methods. We then improve an XLM-based unsupervised neural MT system pre-trained on Wikipedia by supplementing it with pseudo-parallel text mined from the same corpus, boosting unsupervised translation performance by up to 3.5 BLEU on the WMT'14 French-English and WMT'16 German-English tasks and outperforming the previous state-of-the-art. Finally, we enrich the IWSLT'15 English-Vietnamese corpus with pseudo-parallel Wikipedia sentence pairs, yielding a 1.2 BLEU improvement on the low-resource MT task. We demonstrate that unsupervised bitext mining is an effective way of augmenting MT datasets and complements existing techniques like initializing with pre-trained contextual embeddings.
The Multilingual Amazon Reviews Corpus
Oct 06, 2020



We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., 'books', 'appliances', etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot cross-lingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.