 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Relevant Subgoals in Successful Dialogs using Iterative Training for Task-oriented Dialog Systems
Nov 25, 2024



Task-oriented Dialog (ToD) systems have to solve multiple subgoals to accomplish user goals, whereas feedback is often obtained only at the end of the dialog. In this work, we propose SUIT (SUbgoal-aware ITerative Training), an iterative training approach for improving ToD systems. We sample dialogs from the model we aim to improve and determine subgoals that contribute to dialog success using distant supervision to obtain high quality training samples. We show how this data improves supervised fine-tuning or, alternatively, preference learning results. SUIT is able to iteratively generate more data instead of relying on fixed static sets. SUIT reaches new state-of-the-art performance on a popular ToD benchmark.
Few Shot Rationale Generation using Self-Training with Dual Teachers
Jun 05, 2023Self-rationalizing models that also generate a free-text explanation for their predicted labels are an important tool to build trustworthy AI applications. Since generating explanations for annotated labels is a laborious and costly pro cess, recent models rely on large pretrained language models (PLMs) as their backbone and few-shot learning. In this work we explore a self-training approach leveraging both labeled and unlabeled data to further improve few-shot models, under the assumption that neither human written rationales nor annotated task labels are available at scale. We introduce a novel dual-teacher learning framework, which learns two specialized teacher models for task prediction and rationalization using self-training and distills their knowledge into a multi-tasking student model that can jointly generate the task label and rationale. Furthermore, we formulate a new loss function, Masked Label Regularization (MLR) which promotes explanations to be strongly conditioned on predicted labels. Evaluation on three public datasets demonstrate that the proposed methods are effective in modeling task labels and generating faithful rationales.
Deploying a Retrieval based Response Model for Task Oriented Dialogues
Oct 25, 2022


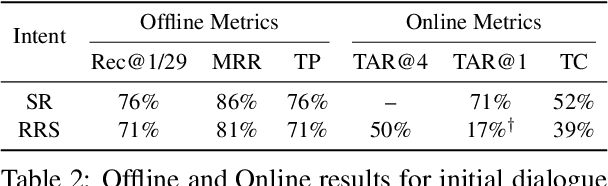
Task-oriented dialogue systems in industry settings need to have high conversational capability, be easily adaptable to changing situations and conform to business constraints. This paper describes a 3-step procedure to develop a conversational model that satisfies these criteria and can efficiently scale to rank a large set of response candidates. First, we provide a simple algorithm to semi-automatically create a high-coverage template set from historic conversations without any annotation. Second, we propose a neural architecture that encodes the dialogue context and applicable business constraints as profile features for ranking the next turn. Third, we describe a two-stage learning strategy with self-supervised training, followed by supervised fine-tuning on limited data collected through a human-in-the-loop platform. Finally, we describe offline experiments and present results of deploying our model with human-in-the-loop to converse with live customers online.
Transformer Uncertainty Estimation with Hierarchical Stochastic Attention
Dec 27, 2021



Transformers are state-of-the-art in a wide range of NLP tasks and have also been applied to many real-world products. Understanding the reliability and certainty of transformer model predictions is crucial for building trustable machine learning applications, e.g., medical diagnosis. Although many recent transformer extensions have been proposed, the study of the uncertainty estimation of transformer models is under-explored. In this work, we propose a novel way to enable transformers to have the capability of uncertainty estimation and, meanwhile, retain the original predictive performance. This is achieved by learning a hierarchical stochastic self-attention that attends to values and a set of learnable centroids, respectively. Then new attention heads are formed with a mixture of sampled centroids using the Gumbel-Softmax trick. We theoretically show that the self-attention approximation by sampling from a Gumbel distribution is upper bounded. We empirically evaluate our model on two text classification tasks with both in-domain (ID) and out-of-domain (OOD) datasets. The experimental results demonstrate that our approach: (1) achieves the best predictive performance and uncertainty trade-off among compared methods; (2) exhibits very competitive (in most cases, improved) predictive performance on ID datasets; (3) is on par with Monte Carlo dropout and ensemble methods in uncertainty estimation on OOD datasets.
The Multilingual Amazon Reviews Corpus
Oct 06, 2020



We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., 'books', 'appliances', etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot cross-lingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.