 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiJustice: A Chinese Dataset for Multi-Party, Multi-Charge Legal Prediction
Jul 09, 2025Legal judgment prediction offers a compelling method to aid legal practitioners and researchers. However, the research question remains relatively under-explored: Should multiple defendants and charges be treated separately in LJP? To address this, we introduce a new dataset namely multi-person multi-charge prediction (MPMCP), and seek the answer by evaluating the performance of several prevailing legal large language models (LLMs) on four practical legal judgment scenarios: (S1) single defendant with a single charge, (S2) single defendant with multiple charges, (S3) multiple defendants with a single charge, and (S4) multiple defendants with multiple charges. We evaluate the dataset across two LJP tasks, i.e., charge prediction and penalty term prediction. We have conducted extensive experiments and found that the scenario involving multiple defendants and multiple charges (S4) poses the greatest challenges, followed by S2, S3, and S1. The impact varies significantly depending on the model. For example, in S4 compared to S1, InternLM2 achieves approximately 4.5% lower F1-score and 2.8% higher LogD, while Lawformer demonstrates around 19.7% lower F1-score and 19.0% higher LogD. Our dataset and code are available at https://github.com/lololo-xiao/MultiJustice-MPMCP.
Script-Strategy Aligned Generation: Aligning LLMs with Expert-Crafted Dialogue Scripts and Therapeutic Strategies for Psychotherapy
Nov 11, 2024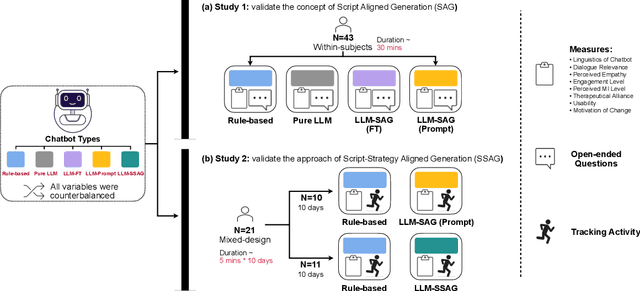
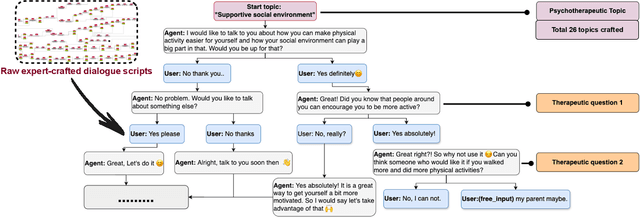
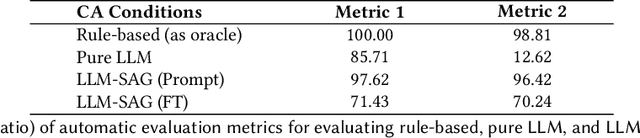
Chatbots or conversational agents (CAs) are increasingly used to improve access to digital psychotherapy. Many current systems rely on rigid, rule-based designs, heavily dependent on expert-crafted dialogue scripts for guiding therapeutic conversations. Although recent advances in large language models (LLMs) offer the potential for more flexible interactions, their lack of controllability and transparency poses significant challenges in sensitive areas like psychotherapy. In this work, we explored how aligning LLMs with expert-crafted scripts can enhance psychotherapeutic chatbot performance. Our comparative study showed that LLMs aligned with expert-crafted scripts through prompting and fine-tuning significantly outperformed both pure LLMs and rule-based chatbots, achieving a more effective balance between dialogue flexibility and adherence to therapeutic principles. Building on findings, we proposed ``Script-Strategy Aligned Generation (SSAG)'', a flexible alignment approach that reduces reliance on fully scripted content while enhancing LLMs' therapeutic adherence and controllability. In a 10-day field study, SSAG demonstrated performance comparable to full script alignment and outperformed rule-based chatbots, empirically supporting SSAG as an efficient approach for aligning LLMs with domain expertise. Our work advances LLM applications in psychotherapy by providing a controllable, adaptable, and scalable solution for digital interventions, reducing reliance on expert effort. It also provides a collaborative framework for domain experts and developers to efficiently build expertise-aligned chatbots, broadening access to psychotherapy and behavioral interventions.
A Comparative Analysis of Faithfulness Metrics and Humans in Citation Evaluation
Aug 22, 2024



Large language models (LLMs) often generate content with unsupported or unverifiable content, known as "hallucinations." To address this, retrieval-augmented LLMs are employed to include citations in their content, grounding the content in verifiable sources. Despite such developments, manually assessing how well a citation supports the associated statement remains a major challenge. Previous studies tackle this challenge by leveraging faithfulness metrics to estimate citation support automatically. However, they limit this citation support estimation to a binary classification scenario, neglecting fine-grained citation support in practical scenarios. To investigate the effectiveness of faithfulness metrics in fine-grained scenarios, we propose a comparative evaluation framework that assesses the metric effectiveness in distinguishing citations between three-category support levels: full, partial, and no support. Our framework employs correlation analysis, classification evaluation, and retrieval evaluation to measure the alignment between metric scores and human judgments comprehensively. Our results indicate no single metric consistently excels across all evaluations, highlighting the complexity of accurately evaluating fine-grained support levels. Particularly, we find that the best-performing metrics struggle to distinguish partial support from full or no support. Based on these findings, we provide practical recommendations for developing more effective metrics.
Chain-of-Strategy Planning with LLMs: Aligning the Generation of Psychotherapy Dialogue with Strategy in Motivational Interviewing
Aug 12, 2024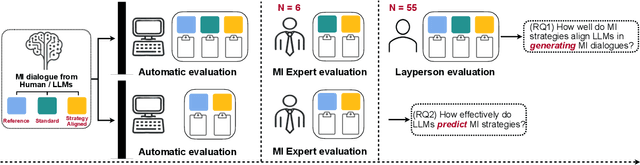

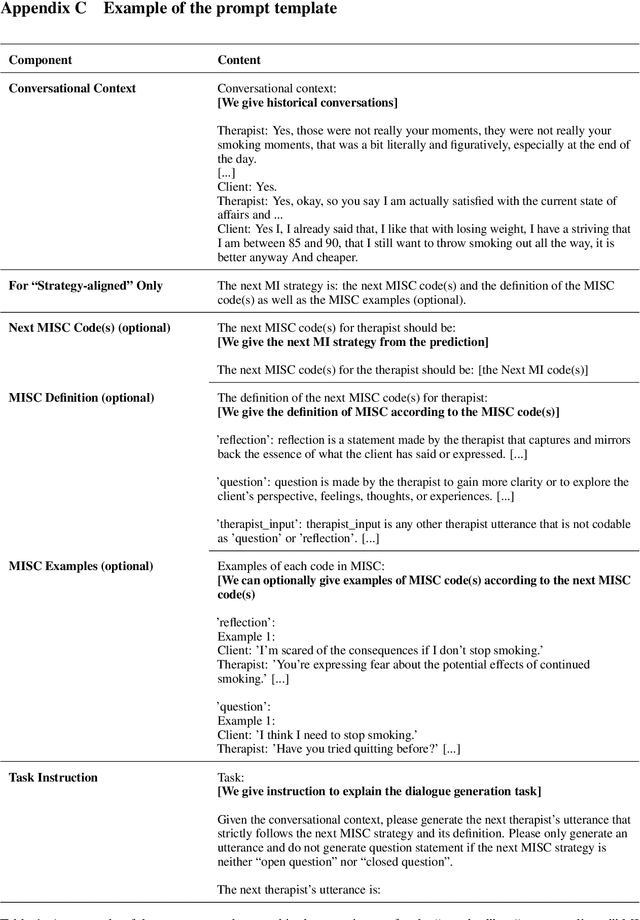
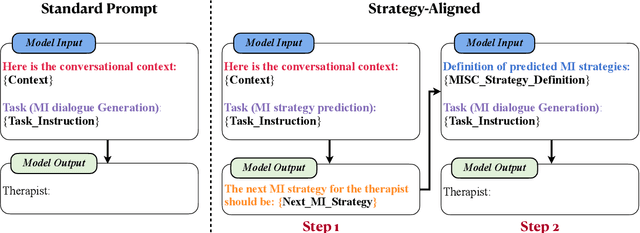
Recent advancements in large language models (LLMs) have shown promise in generating psychotherapeutic dialogues, especially in Motivational Interviewing (MI). However, how to employ strategies, a set of motivational interviewing (MI) skills, to generate therapeutic-adherent conversations with explainability is underexplored. We propose an approach called strategy-aware dialogue generation with Chain-of-Strategy (CoS) planning, which first predicts MI strategies as reasoning and utilizes these strategies to guide the subsequent dialogue generation. It brings the potential for controllable and explainable generation in psychotherapy by aligning the generated MI dialogues with therapeutic strategies. Extensive experiments including automatic and human evaluations are conducted to validate the effectiveness of the MI strategy. Our findings demonstrate the potential of LLMs in producing strategically aligned dialogues and suggest directions for practical applications in psychotherapeutic settings.
Assessing "Implicit" Retrieval Robustness of Large Language Models
Jun 26, 2024



Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the "implicit" retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.
Towards Fine-Grained Citation Evaluation in Generated Text: A Comparative Analysis of Faithfulness Metrics
Jun 21, 2024



Large language models (LLMs) often produce unsupported or unverifiable information, known as "hallucinations." To mitigate this, retrieval-augmented LLMs incorporate citations, grounding the content in verifiable sources. Despite such developments, manually assessing how well a citation supports the associated statement remains a major challenge. Previous studies use faithfulness metrics to estimate citation support automatically but are limited to binary classification, overlooking fine-grained citation support in practical scenarios. To investigate the effectiveness of faithfulness metrics in fine-grained scenarios, we propose a comparative evaluation framework that assesses the metric effectiveness in distinguishinging citations between three-category support levels: full, partial, and no support. Our framework employs correlation analysis, classification evaluation, and retrieval evaluation to measure the alignment between metric scores and human judgments comprehensively. Our results show no single metric consistently excels across all evaluations, revealing the complexity of assessing fine-grained support. Based on the findings, we provide practical recommendations for developing more effective metrics.
Autonomous Workflow for Multimodal Fine-Grained Training Assistants Towards Mixed Reality
May 16, 2024
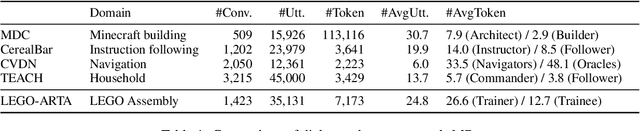
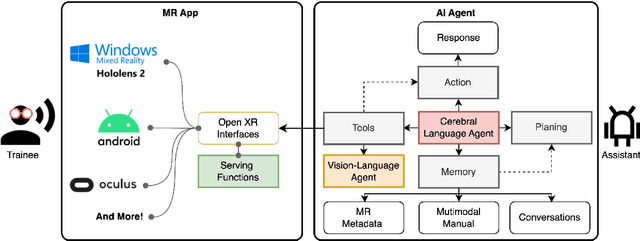

Autonomous artificial intelligence (AI) agents have emerged as promising protocols for automatically understanding the language-based environment, particularly with the exponential development of large language models (LLMs). However, a fine-grained, comprehensive understanding of multimodal environments remains under-explored. This work designs an autonomous workflow tailored for integrating AI agents seamlessly into extended reality (XR) applications for fine-grained training. We present a demonstration of a multimodal fine-grained training assistant for LEGO brick assembly in a pilot XR environment. Specifically, we design a cerebral language agent that integrates LLM with memory, planning, and interaction with XR tools and a vision-language agent, enabling agents to decide their actions based on past experiences. Furthermore, we introduce LEGO-MRTA, a multimodal fine-grained assembly dialogue dataset synthesized automatically in the workflow served by a commercial LLM. This dataset comprises multimodal instruction manuals, conversations, XR responses, and vision question answering. Last, we present several prevailing open-resource LLMs as benchmarks, assessing their performance with and without fine-tuning on the proposed dataset. We anticipate that the broader impact of this workflow will advance the development of smarter assistants for seamless user interaction in XR environments, fostering research in both AI and HCI communities.
ExcluIR: Exclusionary Neural Information Retrieval
Apr 26, 2024



Exclusion is an important and universal linguistic skill that humans use to express what they do not want. However, in information retrieval community, there is little research on exclusionary retrieval, where users express what they do not want in their queries. In this work, we investigate the scenario of exclusionary retrieval in document retrieval for the first time. We present ExcluIR, a set of resources for exclusionary retrieval, consisting of an evaluation benchmark and a training set for helping retrieval models to comprehend exclusionary queries. The evaluation benchmark includes 3,452 high-quality exclusionary queries, each of which has been manually annotated. The training set contains 70,293 exclusionary queries, each paired with a positive document and a negative document. We conduct detailed experiments and analyses, obtaining three main observations: (1) Existing retrieval models with different architectures struggle to effectively comprehend exclusionary queries; (2) Although integrating our training data can improve the performance of retrieval models on exclusionary retrieval, there still exists a gap compared to human performance; (3) Generative retrieval models have a natural advantage in handling exclusionary queries. To facilitate future research on exclusionary retrieval, we share the benchmark and evaluation scripts on \url{https://github.com/zwh-sdu/ExcluIR}.
Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning
Feb 27, 2024



Parameter-efficient fine-tuning (PEFT) is a popular method for tailoring pre-trained large language models (LLMs), especially as the models' scale and the diversity of tasks increase. Low-rank adaptation (LoRA) is based on the idea that the adaptation process is intrinsically low-dimensional, i.e., significant model changes can be represented with relatively few parameters. However, decreasing the rank encounters challenges with generalization errors for specific tasks when compared to full-parameter fine-tuning. We present MELoRA, a mini-ensemble low-rank adapters that uses fewer trainable parameters while maintaining a higher rank, thereby offering improved performance potential. The core idea is to freeze original pretrained weights and train a group of mini LoRAs with only a small number of parameters. This can capture a significant degree of diversity among mini LoRAs, thus promoting better generalization ability. We conduct a theoretical analysis and empirical studies on various NLP tasks. Our experimental results show that, compared to LoRA, MELoRA achieves better performance with 8 times fewer trainable parameters on natural language understanding tasks and 36 times fewer trainable parameters on instruction following tasks, which demonstrates the effectiveness of MELoRA.
Intent-calibrated Self-training for Answer Selection in Open-domain Dialogues
Jul 13, 2023Answer selection in open-domain dialogues aims to select an accurate answer from candidates. Recent success of answer selection models hinges on training with large amounts of labeled data. However, collecting large-scale labeled data is labor-intensive and time-consuming. In this paper, we introduce the predicted intent labels to calibrate answer labels in a self-training paradigm. Specifically, we propose the intent-calibrated self-training (ICAST) to improve the quality of pseudo answer labels through the intent-calibrated answer selection paradigm, in which we employ pseudo intent labels to help improve pseudo answer labels. We carry out extensive experiments on two benchmark datasets with open-domain dialogues. The experimental results show that ICAST outperforms baselines consistently with 1%, 5% and 10% labeled data. Specifically, it improves 2.06% and 1.00% of F1 score on the two datasets, compared with the strongest baseline with only 5% labeled data.