 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fine-Tuning for In-Context Retrieval and Efficient KV-Caching in Long-Context Language Models
Jan 26, 2026With context windows of millions of tokens, Long-Context Language Models (LCLMs) can encode entire document collections, offering a strong alternative to conventional retrieval-augmented generation (RAG). However, it remains unclear whether fine-tuning strategies can improve long-context performance and translate to greater robustness under KV-cache compression techniques. In this work, we investigate which training strategies most effectively enhance LCLMs' ability to identify and use relevant information, as well as enhancing their robustness under KV-cache compression. Our experiments show substantial in-domain improvements, achieving gains of up to +20 points over the base model. However, out-of-domain generalization remains task dependent with large variance -- LCLMs excels on finance questions (+9 points), while RAG shows stronger performance on multiple-choice questions (+6 points) over the baseline models. Finally, we show that our fine-tuning approaches bring moderate improvements in robustness under KV-cache compression, with gains varying across tasks.
GaRAGe: A Benchmark with Grounding Annotations for RAG Evaluation
Jun 09, 2025We present GaRAGe, a large RAG benchmark with human-curated long-form answers and annotations of each grounding passage, allowing a fine-grained evaluation of whether LLMs can identify relevant grounding when generating RAG answers. Our benchmark contains 2366 questions of diverse complexity, dynamism, and topics, and includes over 35K annotated passages retrieved from both private document sets and the Web, to reflect real-world RAG use cases. This makes it an ideal test bed to evaluate an LLM's ability to identify only the relevant information necessary to compose a response, or provide a deflective response when there is insufficient information. Evaluations of multiple state-of-the-art LLMs on GaRAGe show that the models tend to over-summarise rather than (a) ground their answers strictly on the annotated relevant passages (reaching at most a Relevance-Aware Factuality Score of 60%), or (b) deflect when no relevant grounding is available (reaching at most 31% true positive rate in deflections). The F1 in attribution to relevant sources is at most 58.9%, and we show that performance is particularly reduced when answering time-sensitive questions and when having to draw knowledge from sparser private grounding sources.
Learning to Reason Over Time: Timeline Self-Reflection for Improved Temporal Reasoning in Language Models
Apr 07, 2025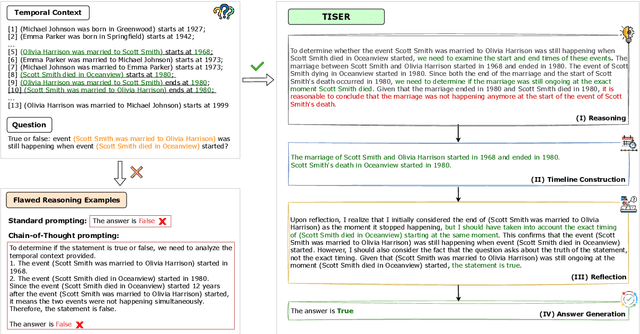
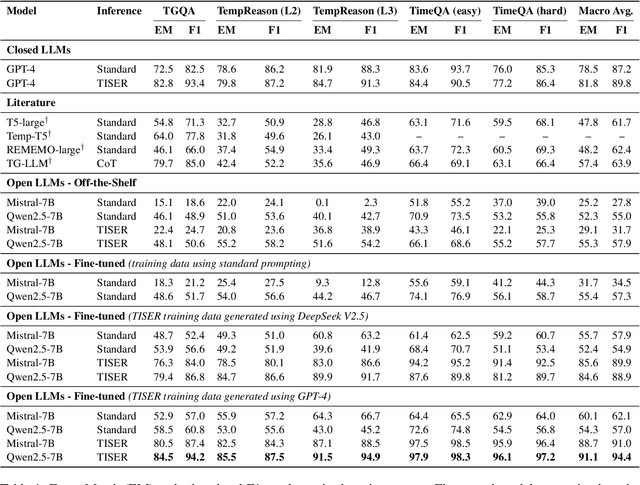
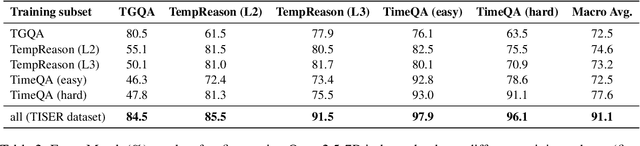
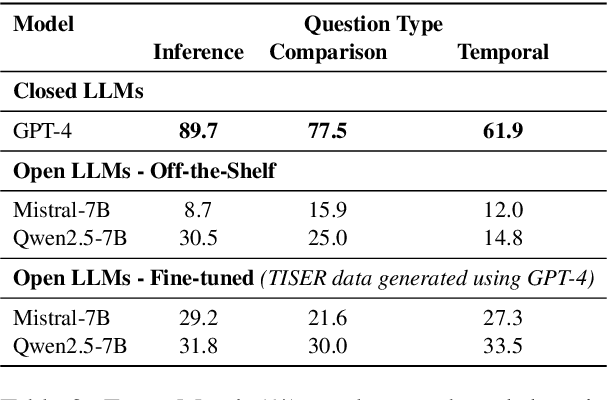
Large Language Models (LLMs) have emerged as powerful tools for generating coherent text, understanding context, and performing reasoning tasks. However, they struggle with temporal reasoning, which requires processing time-related information such as event sequencing, durations, and inter-temporal relationships. These capabilities are critical for applications including question answering, scheduling, and historical analysis. In this paper, we introduce TISER, a novel framework that enhances the temporal reasoning abilities of LLMs through a multi-stage process that combines timeline construction with iterative self-reflection. Our approach leverages test-time scaling to extend the length of reasoning traces, enabling models to capture complex temporal dependencies more effectively. This strategy not only boosts reasoning accuracy but also improves the traceability of the inference process. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, including out-of-distribution test sets, and reveal that TISER enables smaller open-source models to surpass larger closed-weight models on challenging temporal reasoning tasks.
Assessing "Implicit" Retrieval Robustness of Large Language Models
Jun 26, 2024



Retrieval-augmented generation has gained popularity as a framework to enhance large language models with external knowledge. However, its effectiveness hinges on the retrieval robustness of the model. If the model lacks retrieval robustness, its performance is constrained by the accuracy of the retriever, resulting in significant compromises when the retrieved context is irrelevant. In this paper, we evaluate the "implicit" retrieval robustness of various large language models, instructing them to directly output the final answer without explicitly judging the relevance of the retrieved context. Our findings reveal that fine-tuning on a mix of gold and distracting context significantly enhances the model's robustness to retrieval inaccuracies, while still maintaining its ability to extract correct answers when retrieval is accurate. This suggests that large language models can implicitly handle relevant or irrelevant retrieved context by learning solely from the supervision of the final answer in an end-to-end manner. Introducing an additional process for explicit relevance judgment can be unnecessary and disrupts the end-to-end approach.