 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom LLMs to LRMs: Rethinking Pruning for Reasoning-Centric Models
Jan 26, 2026Large language models (LLMs) are increasingly costly to deploy, motivating extensive research on model pruning. However, most existing studies focus on instruction-following LLMs, leaving it unclear whether established pruning strategies transfer to reasoning-augmented models that explicitly generate long intermediate reasoning traces. In this work, we conduct a controlled study of pruning for both instruction-following ($\textbf{LLM-instruct}$) and reasoning-augmented ($\textbf{LLM-think}$) models. To isolate the effects of pruning, we align pruning calibration and post-pruning recovery data with each model's original training distribution, which we show yields more stable and reliable pruning behavior. We evaluate static depth pruning, static width pruning, and dynamic pruning across 17 tasks spanning classification, generation, and reasoning. Our results reveal clear paradigm-dependent differences: depth pruning outperforms width pruning on classification tasks, while width pruning is more robust for generation and reasoning. Moreover, static pruning better preserves reasoning performance, whereas dynamic pruning excels on classification and generation but remains challenging for long-chain reasoning. These findings underscore the need for pruning strategies that explicitly account for the distinct characteristics of reasoning-augmented LLMs. Our code is publicly available at https://github.com/EIT-NLP/LRM-Pruning.
SonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
E^2-LLM: Bridging Neural Signals and Interpretable Affective Analysis
Jan 11, 2026Emotion recognition from electroencephalography (EEG) signals remains challenging due to high inter-subject variability, limited labeled data, and the lack of interpretable reasoning in existing approaches. While recent multimodal large language models (MLLMs) have advanced emotion analysis, they have not been adapted to handle the unique spatiotemporal characteristics of neural signals. We present E^2-LLM (EEG-to-Emotion Large Language Model), the first MLLM framework for interpretable emotion analysis from EEG. E^2-LLM integrates a pretrained EEG encoder with Qwen-based LLMs through learnable projection layers, employing a multi-stage training pipeline that encompasses emotion-discriminative pretraining, cross-modal alignment, and instruction tuning with chain-of-thought reasoning. We design a comprehensive evaluation protocol covering basic emotion prediction, multi-task reasoning, and zero-shot scenario understanding. Experiments on the dataset across seven emotion categories demonstrate that E^2-LLM achieves excellent performance on emotion classification, with larger variants showing enhanced reliability and superior zero-shot generalization to complex reasoning scenarios. Our work establishes a new paradigm combining physiological signals with LLM reasoning capabilities, showing that model scaling improves both recognition accuracy and interpretable emotional understanding in affective computing.
Speak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models
Jan 11, 2026Multimodal Large Language Models (MLLMs) have achieved strong performance across many tasks, yet most systems remain limited to offline inference, requiring complete inputs before generating outputs. Recent streaming methods reduce latency by interleaving perception and generation, but still enforce a sequential perception-generation cycle, limiting real-time interaction. In this work, we target a fundamental bottleneck that arises when extending MLLMs to real-time video understanding: the global positional continuity constraint imposed by standard positional encoding schemes. While natural in offline inference, this constraint tightly couples perception and generation, preventing effective input-output parallelism. To address this limitation, we propose a parallel streaming framework that relaxes positional continuity through three designs: Overlapped, Group-Decoupled, and Gap-Isolated. These designs enable simultaneous perception and generation, allowing the model to process incoming inputs while producing responses in real time. Extensive experiments reveal that Group-Decoupled achieves the best efficiency-performance balance, maintaining high fluency and accuracy while significantly reducing latency. We further show that the proposed framework yields up to 2x acceleration under balanced perception-generation workloads, establishing a principled pathway toward speak-while-watching real-time systems. We make all our code publicly available: https://github.com/EIT-NLP/Speak-While-Watching.
Fault2Flow: An AlphaEvolve-Optimized Human-in-the-Loop Multi-Agent System for Fault-to-Workflow Automation
Nov 17, 2025Power grid fault diagnosis is a critical process hindered by its reliance on manual, error-prone methods. Technicians must manually extract reasoning logic from dense regulations and attempt to combine it with tacit expert knowledge, which is inefficient, error-prone, and lacks maintainability as ragulations are updated and experience evolves. While Large Language Models (LLMs) have shown promise in parsing unstructured text, no existing framework integrates these two disparate knowledge sources into a single, verified, and executable workflow. To bridge this gap, we propose Fault2Flow, an LLM-based multi-agent system. Fault2Flow systematically: (1) extracts and structures regulatory logic into PASTA-formatted fault trees; (2) integrates expert knowledge via a human-in-the-loop interface for verification; (3) optimizes the reasoning logic using a novel AlphaEvolve module; and (4) synthesizes the final, verified logic into an n8n-executable workflow. Experimental validation on transformer fault diagnosis datasets confirms 100\% topological consistency and high semantic fidelity. Fault2Flow establishes a reproducible path from fault analysis to operational automation, substantially reducing expert workload.
The Few Govern the Many:Unveiling Few-Layer Dominance for Time Series Models
Nov 10, 2025Large-scale models are at the forefront of time series (TS) forecasting, dominated by two paradigms: fine-tuning text-based Large Language Models (LLM4TS) and training Time Series Foundation Models (TSFMs) from scratch. Both approaches share a foundational assumption that scaling up model capacity and data volume leads to improved performance. However, we observe a \textit{\textbf{scaling paradox}} in TS models, revealing a puzzling phenomenon that larger models do \emph{NOT} achieve better performance. Through extensive experiments on two model families across four scales (100M to 1.7B parameters) and diverse data (up to 6B observations), we rigorously confirm that the scaling paradox is a pervasive issue. We then diagnose its root cause by analyzing internal representations, identifying a phenomenon we call \textit{few-layer dominance}: only a small subset of layers are functionally important, while the majority are redundant, under-utilized, and can even distract training. Based on this discovery, we propose a practical method to automatically identify and retain only these dominant layers. In our models, retaining only 21\% of the parameters achieves up to a 12\% accuracy improvement and a 2.7$\times$ inference speedup. We validate the universality of our method on 8 prominent SOTA models (LLM4TS and TSFMs, 90M to 6B), showing that retaining less than 30\% of layers achieves comparable or superior accuracy in over 95\% of tasks.
Tools are under-documented: Simple Document Expansion Boosts Tool Retrieval
Oct 26, 2025Large Language Models (LLMs) have recently demonstrated strong capabilities in tool use, yet progress in tool retrieval remains hindered by incomplete and heterogeneous tool documentation. To address this challenge, we introduce Tool-DE, a new benchmark and framework that systematically enriches tool documentation with structured fields to enable more effective tool retrieval, together with two dedicated models, Tool-Embed and Tool-Rank. We design a scalable document expansion pipeline that leverages both open- and closed-source LLMs to generate, validate, and refine enriched tool profiles at low cost, producing large-scale corpora with 50k instances for embedding-based retrievers and 200k for rerankers. On top of this data, we develop two models specifically tailored for tool retrieval: Tool-Embed, a dense retriever, and Tool-Rank, an LLM-based reranker. Extensive experiments on ToolRet and Tool-DE demonstrate that document expansion substantially improves retrieval performance, with Tool-Embed and Tool-Rank achieving new state-of-the-art results on both benchmarks. We further analyze the contribution of individual fields to retrieval effectiveness, as well as the broader impact of document expansion on both training and evaluation. Overall, our findings highlight both the promise and limitations of LLM-driven document expansion, positioning Tool-DE, along with the proposed Tool-Embed and Tool-Rank, as a foundation for future research in tool retrieval.
PricingLogic: Evaluating LLMs Reasoning on Complex Tourism Pricing Tasks
Oct 14, 2025
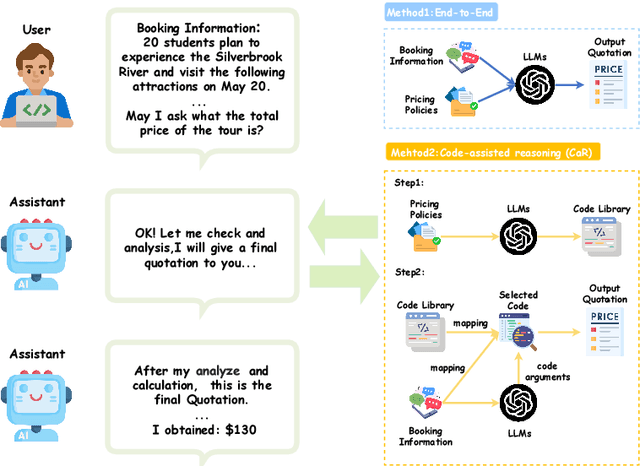


We present PricingLogic, the first benchmark that probes whether Large Language Models(LLMs) can reliably automate tourism-related prices when multiple, overlapping fare rules apply. Travel agencies are eager to offload this error-prone task onto AI systems; however, deploying LLMs without verified reliability could result in significant financial losses and erode customer trust. PricingLogic comprises 300 natural-language questions based on booking requests derived from 42 real-world pricing policies, spanning two levels of difficulty: (i) basic customer-type pricing and (ii)bundled-tour calculations involving interacting discounts. Evaluations of a line of LLMs reveal a steep performance drop on the harder tier,exposing systematic failures in rule interpretation and arithmetic reasoning.These results highlight that, despite their general capabilities, today's LLMs remain unreliable in revenue-critical applications without further safeguards or domain adaptation. Our code and dataset are available at https://github.com/EIT-NLP/PricingLogic.
MCM-DPO: Multifaceted Cross-Modal Direct Preference Optimization for Alt-text Generation
Oct 01, 2025The alt-text generation task produces concise, context-relevant descriptions of images, enabling blind and low-vision users to access online images. Despite the capabilities of large vision-language models, alt-text generation performance remains limited due to noisy user annotations, inconsistent standards, and MLLMs' insensitivity to contextual information. Previous efforts to fine-tune MLLMs using supervised fine-tuning (SFT) have struggled, as SFT relies on accurate target annotations, which are often flawed in user-generated alt-text. To address this, we propose Multi-faceted Cross-modal Direct Preference Optimization (MCM-DPO), which improves alt-text generation by learning to identify better options in preference pairs without requiring precise annotations. MCM-DPO optimizes preferences across single, paired, and multi-preference dimensions, covering textual, visual, and cross-modal factors. In light of the scarcity of high-quality annotated and preference-labeled datasets for alt-text, we constructed two large-scale, high-quality datasets named TAlt and PAlt, sourced from Twitter and Pinterest. These datasets include 202k annotated alt-text samples and 18k preference pairs that cover diverse preference dimensions, aiming to support further research in this domain. Experimental results show that our proposed MCM-DPO method consistently outperforms both DPO and SFT, establishing a new state of the art in alt-text generation. We release the code and data here: https://github.com/LVUGAI/MCM-DPO
MultiJustice: A Chinese Dataset for Multi-Party, Multi-Charge Legal Prediction
Jul 09, 2025Legal judgment prediction offers a compelling method to aid legal practitioners and researchers. However, the research question remains relatively under-explored: Should multiple defendants and charges be treated separately in LJP? To address this, we introduce a new dataset namely multi-person multi-charge prediction (MPMCP), and seek the answer by evaluating the performance of several prevailing legal large language models (LLMs) on four practical legal judgment scenarios: (S1) single defendant with a single charge, (S2) single defendant with multiple charges, (S3) multiple defendants with a single charge, and (S4) multiple defendants with multiple charges. We evaluate the dataset across two LJP tasks, i.e., charge prediction and penalty term prediction. We have conducted extensive experiments and found that the scenario involving multiple defendants and multiple charges (S4) poses the greatest challenges, followed by S2, S3, and S1. The impact varies significantly depending on the model. For example, in S4 compared to S1, InternLM2 achieves approximately 4.5% lower F1-score and 2.8% higher LogD, while Lawformer demonstrates around 19.7% lower F1-score and 19.0% higher LogD. Our dataset and code are available at https://github.com/lololo-xiao/MultiJustice-MPMCP.