 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCM-DPO: Multifaceted Cross-Modal Direct Preference Optimization for Alt-text Generation
Oct 01, 2025The alt-text generation task produces concise, context-relevant descriptions of images, enabling blind and low-vision users to access online images. Despite the capabilities of large vision-language models, alt-text generation performance remains limited due to noisy user annotations, inconsistent standards, and MLLMs' insensitivity to contextual information. Previous efforts to fine-tune MLLMs using supervised fine-tuning (SFT) have struggled, as SFT relies on accurate target annotations, which are often flawed in user-generated alt-text. To address this, we propose Multi-faceted Cross-modal Direct Preference Optimization (MCM-DPO), which improves alt-text generation by learning to identify better options in preference pairs without requiring precise annotations. MCM-DPO optimizes preferences across single, paired, and multi-preference dimensions, covering textual, visual, and cross-modal factors. In light of the scarcity of high-quality annotated and preference-labeled datasets for alt-text, we constructed two large-scale, high-quality datasets named TAlt and PAlt, sourced from Twitter and Pinterest. These datasets include 202k annotated alt-text samples and 18k preference pairs that cover diverse preference dimensions, aiming to support further research in this domain. Experimental results show that our proposed MCM-DPO method consistently outperforms both DPO and SFT, establishing a new state of the art in alt-text generation. We release the code and data here: https://github.com/LVUGAI/MCM-DPO
CHiP: Cross-modal Hierarchical Direct Preference Optimization for Multimodal LLMs
Jan 28, 2025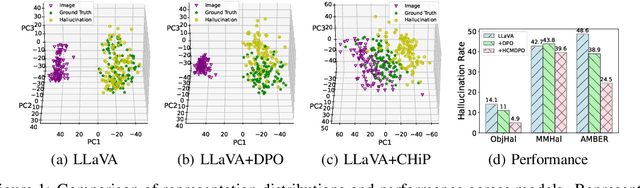



Multimodal Large Language Models (MLLMs) still struggle with hallucinations despite their impressive capabilities. Recent studies have attempted to mitigate this by applying Direct Preference Optimization (DPO) to multimodal scenarios using preference pairs from text-based responses. However, our analysis of representation distributions reveals that multimodal DPO struggles to align image and text representations and to distinguish between hallucinated and non-hallucinated descriptions. To address these challenges, in this work, we propose a Cross-modal Hierarchical Direct Preference Optimization (CHiP) to address these limitations. We introduce a visual preference optimization module within the DPO framework, enabling MLLMs to learn from both textual and visual preferences simultaneously. Furthermore, we propose a hierarchical textual preference optimization module that allows the model to capture preferences at multiple granular levels, including response, segment, and token levels. We evaluate CHiP through both quantitative and qualitative analyses, with results across multiple benchmarks demonstrating its effectiveness in reducing hallucinations. On the Object HalBench dataset, CHiP outperforms DPO in hallucination reduction, achieving improvements of 52.7% and 55.5% relative points based on the base model Muffin and LLaVA models, respectively. We make all our datasets and code publicly available: https://github.com/LVUGAI/CHiP.
Hint-before-Solving Prompting: Guiding LLMs to Effectively Utilize Encoded Knowledge
Feb 22, 2024

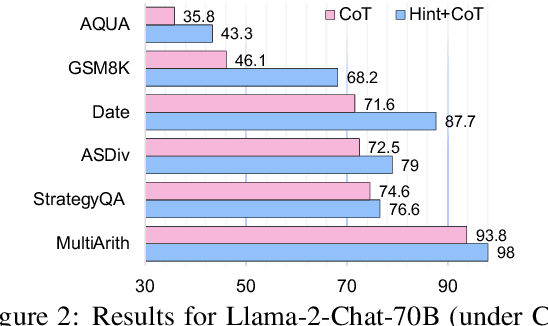

Large Language Models (LLMs) have recently showcased remarkable generalizability in various domains. Despite their extensive knowledge, LLMs still face challenges in efficiently utilizing encoded knowledge to develop accurate and logical reasoning processes. To mitigate this problem, we introduced Hint-before-Solving Prompting (HSP), which guides the model to generate hints (e.g., specific knowledge or key ideas) for solving the problem and then generate solutions containing intermediate reasoning steps. Since HSP is orthogonal to prompting methods (e.g., Chain-of-Thought (CoT)), we applied HSP to CoT, Least-to-Most, Plan-and-Solve, and Standard promptings. The results of extensive experiments on 6 reasoning benchmarks and 4 open-source LLMs demonstrate that HSP can effectively improve the accuracy of reasoning tasks: (1) By applying high-quality hint-enhanced HSP to CoT prompting, Llama2-70B-Chat shows an improvement of 9.7. (2) Beyond exploring training-free LLM capabilities, we built the HSPMATH dataset based on HSP and fine-tuned Llemma-7B, reaching 64.3 accuracy, surpassing GPT-3.5 and WizardMath-13B. We make our code and dataset publicly available at \url{https://github.com/jinlanfu/HSP}.